Flat Datacenter Storage
0x00 引言
这篇也是分布式存储方向一片很有名的Paper。Flat Datacenter Storage的目标是设计一个高性能、容错、大规模以及locality-oblivious的分布式存储系统。Flat在FDS中的一个含义就是所有的所有的节点都能以同样的带宽和延迟访问数据,这样的话在FDS中不需要考虑数据局部性的问题,以解决一些系统在考虑局部性的时候反而带来的效率降低的问题,
FDS applications achieve single-process read and write performance of more than 2 GB/s. We measure recovery of 92GB data lost to disk failure in 6.2s and recovery from a total machine failure with 655GB of data in 33.7s.
0x01 基本架构
在FDS中,数据的存储都是一个blob为抽象,一个blob使用一个128bit的GUID来表示。这个GUID可以是客户端指定的,也可以是系统自己生成的。Blob的大小限制只取决于系统的存储空间大小。FDS的一个设计目标是可以让应用使用系统的能够通过的所有的带宽,这里FDS的一个设计就是将blob划分为tract,这个tract的大小一般为8MB,在一些Flash存储上可以设置得更加小一些,比如64KB。FDS中的每个磁盘有一个tractserver进程来管理,它处理来自客户端的读写请求。tractserver这里不会使用文件系统,而是直接使用裸的存储设备来管理数据,它一般将tract的元数据都Cache在内存中。
//Getting access to a blob
CreateBlob(UINT128 blobGuid)
OpenBlob(UINT128 blobGuid)
CloseBlob(UINT128 blobGuid)
DeleteBlob(UINT128 blobGuid)
//Interacting with a blob
GetBlobSize()
ExtendBlobSize(UINT64 numberOfTracts)
WriteTract(UINT64 tractNumber, BYTE *buf)
ReadTract(UINT64 tractNumber, BYTE *buf)
GetSimultaneousLimit()
FDS提供的接口如上。在FDS中,一般的工作包含这些一些内容,
-
数据定位,分布式存储的核心问题之一就是它数据位置。常见的方式是使用元数据服务器来记录数据的位置,比如GFS、HDFS。这样的一个问题就是这个元数据服务会是整个系统的一个瓶颈。FDS这里使用一个不同的方法。在FDS中,同样存在一个中心的元数据服务器,不过它的功能非常简单,就是收集目前活跃的tracserver的信息,方便客户端获取这些信息。这个数据被称之为tract locator table(TLT)。为了读写一个Blob的第i个tract,客户端使用
Tract Locator = (Hash(g) + i) mod TLT Length这样的一个计算方式来获取它的Tract Locator。这里Hash(g) + i的设计比Hash(g+i)的设计更能利用全部的存储服务器。这里的计算客户端就可以知道数据保存的tractserver,另外的一些元数据就保存在这个server上面。取读写一个Blon的tact的时候,也要将这个Blob的GUID和tract的信息daishang。这里也就是说TLT值保存了tractsever很有限的一点儿数据。这样的话解决了中心化元数据服务器的元数据服务器的瓶颈问题。另外,TLT的这些信息只有在集群发生更改的情况下才会被更新,这样给客户端缓存这些信息也提供了很好的条件。在保存TLT的服务器故障之后,TLT数据的恢复的速度也很快。这样的元数据有这样的一些特点,
- FDS这样的中心元数据服务器处理压力远小于GFS一类的设计。
- 这部分的元数据可以被客户端缓存更长的时间。
- 简单的工作,不大的数据,使得这个中心的元数据服务器很容易实现。
- tractservers为随机排列,为了客户端能够更好地利用均匀全部的服务器。
-
元数据,Blob另外的一些元数据,比如长度的信息。它作为Blob一个特定的tract来保存。这个tract的编号为-1。使用读写数据tract一样的方式来读写这个元数据的tract。数据tract的编号就从0开始。删除一个数据的时候直接删除tract = -1的元数据就可以了。后面的垃圾回收就可以根据这个tract有没有对应的元数据tract来决定这个对象是否可以回收。新创建的tract长度为0。在写入数据之前,要先通过extend操作来处理文件的元数据。这里extend操作是原子、并发安全的。操作成功返回这个Blob新的长度信息。这个extend操作就逻辑上面对应了GFS中的原子追加的操作。这里extend操作还有在实际写入数据的时候才会实际地分配存储的空间。
-
动态work分配,在FDS中,计算和存储是分开的。这里涉及到一个工作任务分配的问题。这里和Mapreduce中的一样,主要的问题就是尾延迟的问题。这里大概是采用了一种类似每次分配一小个任务集合给一个worker,在这个woreker现在处理的任务就要完成的时候请求下面的worker。缓解尾延迟的问题,
... The best practice for FDS applications is to centrally (or, at large scale, hierarchically) give small units of work to each worker as it nears completion of its previous unit. This self-clocking system ensures that the maximum dispersion in completion times across the cluster is only the time required for the slowest worker to complete a single unit.
0x02 副本和容错
副本和容错的问题是分布式存储系统必须处理的一个问题。FDS在复制方面使用Primary负责复制到其它副本的方式。这里数据的提交使用2PC的方式,这里在副本都确认提交成功之后,Primary才会确认提交。在副本数量的选择上面,FDS可以按需选择需要的副本的数量。比如对于写入一次的计算类型的业务,单副本就可以满足要求,而其它的对数据可靠性要求很高的业务,可以提高副本的数量。这些副本数量的信息会被保存到Blob的元数据中。
故障恢复
在TLT中,tractserver在中心的元数据服务器表示的实际上表格,一行代表一些数据的k个副本,如下图所示。这个表格中的一个单元就表示一个tractserver。每一行有一个version number。一个tractserver添加到集群的一行之后,元数据服务器会将这个信息发送给这个服务器。和常见的系统设计一样,这里tractserver和元数据服务器通过判断一个tractserver是否正常工作。如果元数据服务器认为一个tractserver故障时,它按照一下的流程来处理,
- 使当前的TLT失效,增加这个tractserver出现的row的version number;
- 随机挑选一个tractserver来代替故障server的位置;
- 发送TLT更新信息给受影响的tractserver;
- 等待这些tractserver确认。
在TLT更新的时候,客户端必须等待这恶搞TLT更新完毕。这个tractserver新添加进去之后,它会和其它的副本交互。拉取这部分tracts的数据。在这个重新复制的时候,是可以进行处理客户端的请求的。这里当个tractsererv故障处理的逻辑相对来说是比较简单的,当多个tractserver和元数据服务器固执之后,处理的逻辑会复杂一些。
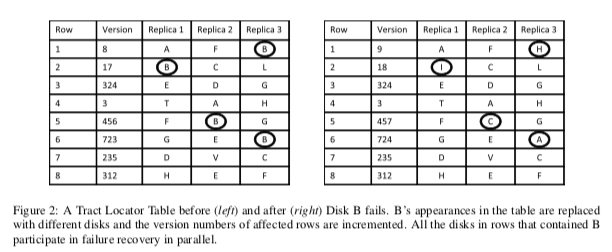
在多个副本故障的情形中,元数据服务器要做的就是按照单个tractserver故障的逻辑来处理。如果TLT中一行在一个窗口中都故障了,数据丢失的情况就会发生。这里设计上的选择就是如何处理故障的服务器之后有比较快的恢复的问题。FDS在论文中实际使用了的方法就是不管这个,直接使用新的tractserver代替。如果在重新复制数据到这个新的tractserver过程中,故障的服务器恢复了。这个时候添加哪一个是一个可以优化的问题。有的时候直接添加故障恢复了的tractserver可以减少一些数据复制。这里FDS将这种很快就恢复的故障称之为transient faults,
To further mitigate the effects of transient faults, the metadata server could separate the replacement of a failed server in the TLT from the initiation of the data movement required for failure recovery.
在FDS中一个tractserver对应的是一个磁盘,而不是一台服务器。这里还有一个很重要的问题,以副本数量k-2为例。在上图的TLT的设计中,如果一个tractserver i复制,那么它的副本只会来自另外的两个磁盘。在一个tractserver故障的时候,受限于HDD磁盘的带宽,几个TB的磁盘数据完全拷贝的时间可能非常长。这里FDS使用了一些其它的优化方式,
-
一个优化的方式是使用一个O(n^2)项的TLT,
A better TLT has O(n^2) entries. Each possible pair of disks (ignoring failure domains) appears in an entry of the TLT. Since the generation of tract locators is pseudo-random, any data written to a disk will have high diversity in the location of its replica.这种方式使得一个磁盘上面的数据的副本分布在其它的所有的磁盘上面。这样的话一个磁盘故障之后复制恢复可以利用其它所有磁盘的带宽,大大提高了故障恢复的速度。利用大量磁盘来加快恢复速度的思路在前面的RAMCloud和SiloR中也有使用。
-
这样带来的一个问题就是这个TLT可能比较大,特别是磁盘的数量达到了万级别的时候。这里有两个基本的策略去解决这个问题,第一个就是是一个tractserevr管理多个磁盘,减少tractserver的数量。第二个就是现在一个磁盘上面数据分布到其它磁盘数量。Paper中认为3000个磁盘就可以在20s内恢复1TB的数据。
在考虑这些数据发布的时候,FDS这里引入了Failure domain的概率。一个Failure domains就是有很大可能一起出故障的区域,比如位于同一个机架上面的服务器。这里基本的策略也就是避免将一个数据的副本保存在一个rack上面。
0x03 其它
关于一致性的问题。FDS在Paper中提到它使用的复制协议是基于客户端去写所有的副本。这样的话FDS提供的是一种week consistency的保证。如果一个客户端在写了部分的副本之后就Crash了。这样的话不同的客户端可能看到了不同状态的数据。FDS这里可以通过利用Chain Replication来实现强一致性。在故障恢复的时候也会存在不一致的状态,这里主要是因为tracserver更新TLT的信息需要一定的时间。
0x04 评估
这里的具体信息可以参看[1].
参考
- Flat Datacenter Storage, OSDI ‘12.
- Azure Data Lake Store: A Hyperscale Distributed File Service for Big Data Analytics, SIGMOD ’17.
