EC-Cache: Load-Balanced, Low-Latency Cluster Caching with Online Erasure Coding
0x00 引言
EC-Cache是在Alluxio上面实现的一个关于在线EC的一个实现。总的来说,EC-Cache还是作为一个内存Cache的存在,并不是一种支持持久化的对象存储的在线EC的方式,所以这样避免了很多问题。EC-Cache总体的思路是,在写入的时候就讲对象拆分并做EC处理,在读取的时候只需要读取足够恢复数据的部分即可,这样的方式在一些情况下可以减少一些延迟。这篇Paper的内容很长,但是实际上核心的内容就是一节¯_(ツ)_/¯,
As compared to selective replication, EC-Cache improves load balancing by more than 3× and reduces the median and tail read latencies by more than 2×, while using the same amount of memory. EC-Cache does so using 10% additional bandwidth and a small increase in the amount of stored metadata.
0x01 基本思路
EC-Cache的EC的处理时在EC- Cache’s client library完成的。在写入操作的时候,会将对象拆分为k块,然后使用EC算法计算出r个校验块。这里要处理的一个核心问题时,写入的时候如何决定写入的位置。这里使用一个EC-Cache coordinator来决定写入的位置。在写入操作的时候,会先和EC-Cache coordinator交互,获取可以写入(k + r)个的位置。写入的位置信息会作为元数据的一部分保存下来。在读取操作的时候,EC-Cache client library会并发的从(k + r)个数据块中读取(k + ∆)个数据块。这样的方式有几个好处,1. 并行操作,2. 将操作的负载分发到不同的服务器上,有利于负载均衡。3. (k + ∆)中有k个返回就可以了,可以降低延迟。好像没有什么特别的。over。
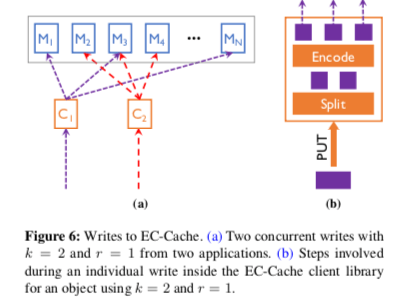
0x02 评估
这里的具体信息可以参看[1].
SP-Cache: Load-Balanced, Redundancy-Free Cluster Caching with Selective Partition
0x10 基本思路
SP-Cache[4]也是一个在Alluxio上面改进的Custer Cacheing的机制。SP-Cache和EC-Cache不同的对方在与SP-Cache不使用对象分块然后EC的方式,而是使用先整体写入,根据对象的访问情况对齐进行分区的方式,
We implemented SP-Cache in Alluxio, a popular in-memory distributed storage for data-intensive clusters. EC2 deployment and trace-driven simulations show that, compared to the state-of-the-art solution called EC-Cache , SP-Cache reduces the file access latency by up to 40% in both the mean and the tail, using 40% less memory.
SP-Cache的基本思路是selective partition。在写入操作的时候,直接将对象就是作为一个整体写入。之后系统会追踪对象的访问情况。SP-Cache会周期性地执行通过re-partitioning操作来实现负载均衡。Paper中的设置是SP-Master会根据对象过去24小时内的访问情况来决定re-partitioning操作。读取的时候,客户端会先河SP-Master交互,获取对象保存的位置,如何经过了re-partitioning操作,这里会是一个server的list。设Si为第i个文件的大小,Pi为其“热度”,ki为这个文件分区的数量,则这里使用这样的方式, \(k_i = ⌈αL_i⌉ = ⌈αS_iP_i⌉\)
Giza: Erasure Coding Objects across Global Data Centers
0x20 引言
这篇Paper明显会比前面两篇考虑更多的东西,一个原因是这篇Paper实现的系统是要支持持久化的,另外一个这个是一个在实际中被使用的系统。这篇Paper的基本内容就是如何支持跨DC的EC。这个是一个比较有趣的话题。这里的对象存储构建在微软已经存在的一些系统之上,比如数据保存在Azure Blob storage上,元数据保存在Azure Table storage之上。另外,以OneDrive使用为例,这些数据有这样的特点,1. 大对象占了大部分的存储空间,虽然可能在对象总数来说比例不会很大。Paper中的数据4MB一下的占用空间小于0.9%,所以Giza的设置中只会对这些对象进行EC操作,小对象直接使用副本的方式即可。这个具体的数据可能不同的应用有不同,但是这样的基本特点是很普遍的。2. 对象访问的次数下降很快,这个也是一个常见特别的。3. Cache可以显著降低跨DC的流量。4. 很少并发操作,但是多版本是很有用的。5. 删除操作比较常见,所以要处理好GC的问题。
0x21 基本设计
为了容忍一个DC不能使用,这里可以选择的方式是2+1,即将一个对象为2+1的EC编码保存到3个DC中。也可以选择n+1,这里的n可以为4、6等,这个是跨DC流量和存储空间开销之间的tradeoff。在进行PUT操作的时候,路径被分为Data Path和Metadata Path。Data Path中回奖对象拆分为几个部分并做EC操作。EC之后的每个块都会赋予一个唯一的标识符,并会带有一个Version信息。这两个字段唯一决定的一个数据。然后这些EC之后的块会被分发到各个DC中,Metadata会被复制到各个DC中。数据和元数据保存到时候,数据保存在Azure Blob storage上,元数据保存在Azure Table storage之上。这里主要要解决3个问题,1. 强一致性地复制元数据,2. 单个RTT的跨DC操作,3. 良好的GC。
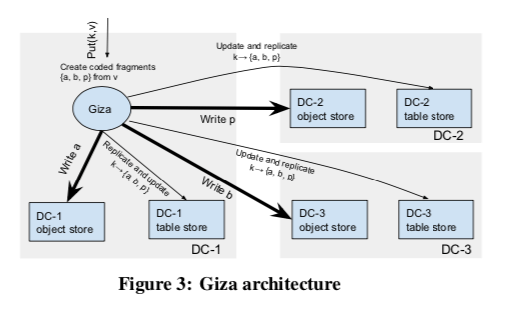
在元数据的恢复上面,Giza直接使用了Paxos和Fast Paxos算法。这里如何利用Paxos和Fast Paxos做元数据的复制具体的内容可以参看[3],反正通过论文写的这部分也很难真的去实现一个出来¯_(ツ)_/¯。为了获取一个对象最新版本的元数据,只从本地DC中读取是不合适的,因为可能本地DC不处于这个最近数据负责的多数范围之内。这里Giza维护了一个known committed versions的信息,这个信息表示了这里知道的所有的DC已经提交版本的值。在多数情况下,这个值就会是最新的。当读取一个版本K的时候,通过这个信息可以确认是否读取本地的版本就可以确认是否读取这个版本就够了。否则就要从所有的DC中读取元数据。
0x22 优化和故障恢复
这里会存在数据和元数据两类的复制操作,常见保证正确的方式是先复制数据,在复制元数据。一种潜在的优化方式是并行复制,但是在数据复制 or 元数据复制出现故障的情况下,就会出现问题。这里解决这个问题的方式如下,
- 在PUT操作的时候,并行复制数据和元数据。Giza这里维护的known committed versions要保证是这些数据都复制了的。加入元数据复制失败,复制的数据就会变成孤儿对象,会在后面的GC操作中被回收。如果是数据复制失败,GET操作的时候就要注意。
- GET操作的时候,最简单的操作就是读取最新的版本。会读取本地元数据,然后根据本地的信息读取数据。在另外启动读取正常的元数据读取方式,来验证读取数据的版本是否有效。如果读取无效,则要重新操作。这里类似于一种乐观的并发控制。
- DELETE操作这里表现为一种特殊的PUT操作。主要就是回去更新元数据,标记一个删除的版本信息。对象的回收由GC机制完成。这里的基本流程是读取元数据,删除数据,最后删除元数据。要注意的一个问题是删除的同时的并发PUT操作。这里就采用一种两阶段提交的方式,第一个阶段标记为所有DC中元数据对应的行为confined,之后的get or put操作不能完成。第二步操作的时候才会实际移除数据。
在一个DC 暂时的故障中,Giza可以通过EC恢复出数据,继续提供服务。如果是一个DC永久性故障,则需要重建数据操作[3].
0x23 评估
这里的具体信息可以参看[3].
Erasure coding in Windows Azure storage
0x30 引言
这篇Paper和下面的这篇XORing Elephants主要讨论的是称之为Local Reconstruction Codes (LRC)的技术。Local Reconstruction Codes (LRC)总体的思路是比较简单的,但能够有效地减少数据修复时候需要的网络带宽。这个LRC的技术被应用到了Windows Azure Storage (WAS)中,很有实际的参看价值。
0x31 基本思路
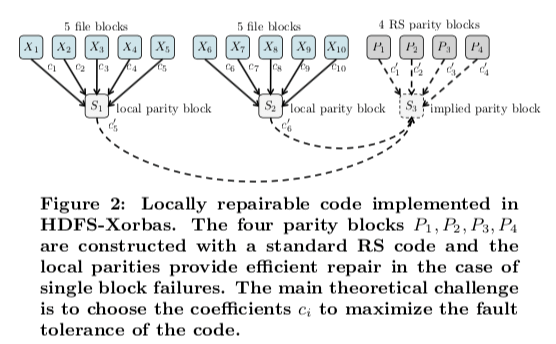
LRC总体的思路是原数据块如何组合生成校验块。以(6,2,2)编码为例,6个块生成2个全局的校验块,3个一组生成2个局部的校验块。在这种配置中,最大可以容忍的是4个块出现故障,但不是任意的4个块。比如下图中的x0,x1,x2和Px故障时就不能恢复,而x0,x1,y1和y2故障时候就可以恢复。这里具体的数学证明[1]¯(ツ)/¯,在多数情况下,都是一个块出现问题,这样的编码方式可以大大减少网络的流量。

在Windows Azure Storage (WAS)的实现中,EC是离线完成的,这样将EC的操作保持数据写入的critical path之外。WAS架构中,SM会周期性地扫描已经sealed的extent,然后根据stream的策略和系统的负载决定对那些extent进行EC操作。SM会根据erasure coding的配置生产一个erasure coding的参数。比如一个extent生成16个fragment,这样就是LRC(12, 2, 2)的配置。SM会指定一个有这个Extent 的副本中的一个来进行EC操作。在决定如何将Extent划分的时候,要考虑到Block的边界,避免Block跨越不同的fragment。之后这个指定的EN联系EC之后数据会保存的ENs,将EC之后的数据发送给这些ENs。这个指定的EN和其它的target ENs都会将这些EC进度的信息持久化,如果在这个过程中发生故障,接下来的工作会另外安排一个EN完成。在完成EC操作之后,EN会联系SM,通知EC已经完成。之后SM会更新对应的metadata。总体的逻辑没有什么特别的,不过具体的实现会是一个要考虑到很多因素的操作。
- 在读取的时候,可以直接读取extent的fragment来获取数据。在fragemnt不可用 or 成为热点的时候,可以通过reconstruction read读取的方式获取数据。一个EN会获取需要的fragment,进行reconstruction操作。这些reconstruction 操作的结果会被缓存。reconstruction 之后就可以返回给客户端数据。
- 在决定extent放置位置的时候,主要考虑两个因素,1. 负载,选择空间占用更低、负载更低的Extent Node。2. 避免将2个fragment放到同一个fault domain 和 upgrade domain,前者不如同一个机架,后者只的是会在同一时间升级操作的domain。这个是分布式系统中常见的操作。
XORing Elephants: Novel Erasure Codes for Big Data
0x40 基本思路
XORing Elephants的思路和前面WAS的思路类似。这里以10个块为例,通过基本的RS算法编码出4个校验块。另外,10个块分为两组,每个生成一个具体的parity block。出现数据损坏的多数情况是一个块的损坏,这样的话不用跨越DC,使用本地的parity block修复即可。
\(设 S_1= c_1X_1+c_2X_2+c_3X_3+c_4X_4 \\
X_3故障之后,通过X_3=c_3^{-1}(S_1-c_1X_1-c_2X_2-c_4X_4)重新计算出X_3.\)
这里可以通过参数的选择来消除S3,实际上也可以达到S3存在的效果。如果P2损坏,则恢复的思路一般是
\(P_2=(c_2')^{-1}(S_3-c_1'P_1-c_2'P_2-c_4'P_4). \\
如果满足S_1+S_2+S3=1, 则上式可表示为P_2=(c_2')^{-1}(-S_1-S_2-c_1'P_1-c_2'P_2-c_4'P_4).\)
Partial-Parallel-Repair (PPR): A Distributed Technique for Repairing Erasure Coded Storage
0x50 基本思路
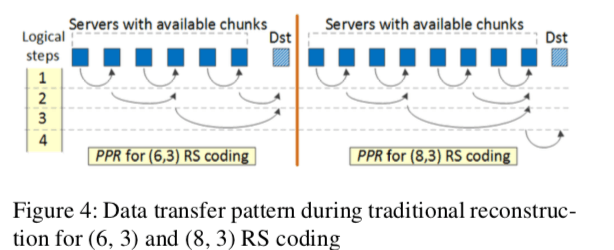
这篇Paper的思路从EC使用的一个数据得出。在EC修复操作中,网络传输的数据占了大部分。这个数据在Paper中占了80%以上,不过这个数据和网络的关系比较大,这个数据感觉参考的价值不是很大。这里先假设在EC修复的操作中,网络传输占了大部分。这里的提出的思路在下篇OpenEC论文中的一幅图表达得更加清晰一些。通常的思路如a、b所示,要所有的数据块传输到一台机器上面的时候才开始编码操作。而PPR则将其分成几个阶段,这里示意图是2ge,第一步是1、2单独生产一个中间结果块,3、4同理。最终的结果由中间的结果得出。这样的好好处就是1,2和3,4的组合并发进行,传输需要的时间降低,5、6同理。缺点是拉长了操作的步骤,在一些假设的情况下才能得到预期的效果。
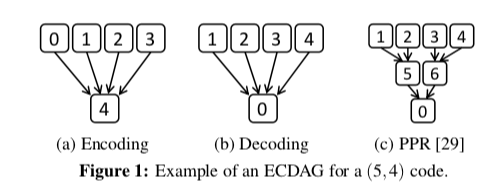
Partial-Parallel-Repair (PPR)在更多数据块下面的思路,总体感觉挺麻烦的。实际上就是一个“树形”的思路。
参考
- EC-Cache: Load-Balanced, Low-Latency Cluster Caching with Online Erasure Coding, OSDI ‘16.
- Efficient and Available In-memory KV-Store with Hybrid Erasure Coding and Replication, FAST ‘16.
- Giza: Erasure Coding Objects across Global Data Centers, ATC ‘17.
- SP-Cache: Load-Balanced, Redundancy-Free Cluster Caching with Selective Partition, SC ‘18.
- Erasure coding in Windows Azure storage, ATC ‘12.
- XORing Elephants: Novel Erasure Codes for Big Data, VLDB ‘13.
- Partial-Parallel-Repair (PPR): A Distributed Technique for Repairing Erasure Coded Storage, EuroSys ’16.
- OpenEC: Toward Unified and Configurable Erasure Coding Management in Distributed Storage Systems, FAST ‘19.
