Faster: A Concurrent Key-Value Store with In-Place Updates
0x00 引言
Faster是微软开发的一个KV Store,其设计上有不少可圈可点的地方。特别是Hash Table的实现,Faster中Lock-Free Hash Table的实现的水平很高,也助Faster实现了一个超高的性能,
... Faster achieves orders-of-magnitude better throughput – up to 160M operations per second on a single machine – than alternative systems deployed widely today, and exceeds the performance of pure in-memory data structures when the workload fits in memory.
0x01 基本设计
Faster本质上就是一个基于Hash Table的一个KV Store。核心的两个部分一个是Hash索引,另外一个就是数据记录的保存。Faster基本的架构如下图。从下面的图看起来,Faster像是将完全将数据保存在内存中的KVS,和将数据保存在磁盘上面的KVS的一个结合体,在结合基础之上,多添加了一个Hybrid Log。这个Hybird的Log又有点类似于LSM-tree中Memtabl的思路。总体设计上面,Faster使用基于Epoch的内存回收方式。这中并发控制也是很多内存存储系统使用的方式,比如Silo,Bw-Tree等。这里的Epoch的基本思路是唯一一个共享的计数器 E,其当前的值称之为current epoch。这个值可以被任何一个线程增加。在这个全局的E之外,每一个线程会保存一个线程局部的E,使用ET表示。这个线程局部的ET使用周期性地冲全局的E读取来更新。线程具体的ET被保存在一个epoch table中。为了避免伪共享,这里每个ET会占用一个Cache Line的大小。如果每个线程具体的ET值都大于一个epoch c,则称这个epoch c为安全的。这里用于内存回收的时候,就是表明安全的epoch内分配的内存可以被回收的。在增加全局的epoch的时候,Faster这里可以设置一个触发器,在这个epoch变为安全的时候被调用。
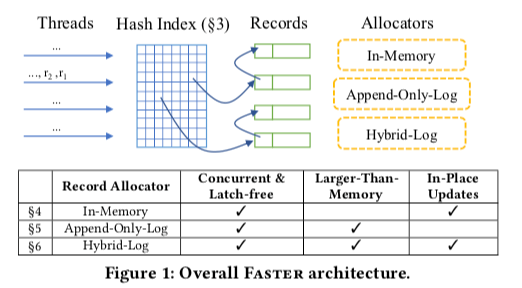
0x02 Hash Index
Faster的Hash Index是实现地比较精巧的一个地方。不过有的地方处理也粗糙。Faster的Hash Index的设计有这样的几个特点,
- 为了优化Cache的友好度。Faster的Hash Index很多结构都是Cache Line对其的。每个Bucket也是刚好分配一个Cache Line的大小。这的一个显著就是Faster使用的Key的大小是8 byte。可以保存一个指针。64Byte的Cache Line大小的话,可以保存7个,另外一个保存一个指向Overflow的Bucket的指针。由于一般x86机器上面使用的指针实际只使用了64bit中的48bit。这里将余下的16个bit中的15个作为一个tag,1个作为tentative bit,这个bit会被用于后台的并发操作。tag可以用来保存key 的Hash值的一部分,这个可以用来检测一些Hash冲突。这个思路也在一些Cuckoo Hash Table设计中使用。
- 在Hash Index中查找和删除一个数据项都是比较直观的操作。查找就是利用Hash值来找到对应的Bucket,并对比Key是否相等。另外,这里可以利用tag中保存的部分Hash值的来减少不必要的Key比较。删除则是在查找的基础之上使用CAS操作将Slot置为0即可。添加操作造这里有额外的一个问题要处理,想象一下这样的一种情况,1. 一个Bucket中,一个线程准备添加一个数据项,找到第5个为空,准备将数据项添加到这里。2. 另外一个线程删除了第3个,然后添加一个和准备添加到第5个数据项相同的数据。这样就可能导致存储同样Key的数据。为了解决这个问题,前面的tentative bit就派上了用场。在添加的时候,同时设置这个tentative bit,设置了这个tentative bit不能被查找和更新发现。另外这个时候添加还没有完成。在设置了之后,重新扫描这个Bucket,如果发现了相同的tag,则回退重试操作。如果没发现,则清理tentative bit完成添加。
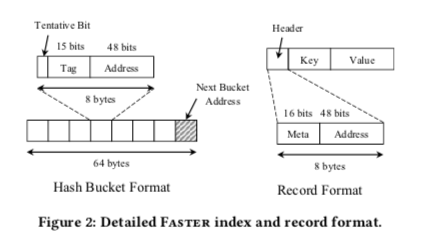
0x03 数据存储
为了支持保存超过内存大小的数据。这里Faster引入了逻辑地址来表示数据保存的位置。逻辑地址空间使用48bit的地址表示。一部分保存在内存中,另外的部分可以保存在磁盘上面。基本的结构如下图所示。这里维护了一个Head Offet和一个Tail Offset。前者表示了On-Disk的地址部分,后者表示目前写入数据的位置。在这两个Offset中间的数据访问就是内存访问。访问小于HeadOffset的数据则要访问磁盘。
- 在内存的中数据增大之后,在需要的时候,需要将内存中的一些数据写入磁盘。这里要注意这样的一个问题,就是要保存数据写入的时候,这个数据page上面,没有继续的更新操作,否则可能导致写入磁盘的Page和内存中的不一致,从而导致数据丢失。这里还是利用了Faster的Epoch的机制。目前这里的设置都是append-only的。所以当内存的数据开始写新的Page的数据,就可以考虑将之前的Page写入磁盘。写入开始写新的Page,但是并不代表旧的Page里面的写操作都已经执行完成了。这个时候就需要Faster的Epoch机制来保证前面的Page已经处理安全状态。
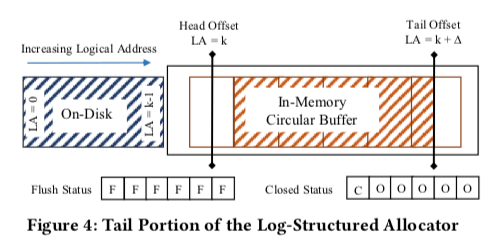
内存中和磁盘上面都是Append-Only的方式的好处就是实现简单。但是这里有一个明显的问题就是写入操作最终都会转化为写入磁盘的数据。对于频繁更新的场景,如果频繁更新的数据都保存在内存中,完全可以考虑直接更新,而不同Append新版本的方式。所以这里引入了HybridLog,来优化这个问题。HybridLog即基本结构如下图所示。可以理解为在初始的设计上面添加了一个可以就地更新的区域。同时为了兼容之前的设计,比如刷page到磁盘,保存了一部分的Read-Only的区域。
-
为了直接在内存中in-place的一些问题。这里使用的方式感觉和LSM-tree的Memtable一样的思路。将内存中的数据分配为只读的部分和Memtable的部分。Mutable的数据只有在变为rad-Only之后才能写入磁盘。如果要更新Read-Only部分的数据,则要使用Read-Copy-Update (RCU)的策略,即在Mutable的区域创建一个新的数据版本来进行更新操作。
-
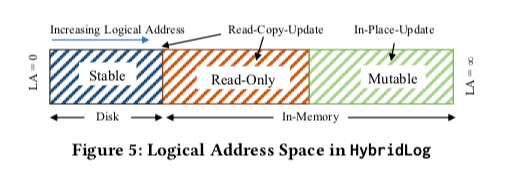
这里Faster为HybridLog维护一个Read-Only和Mutable的分界线。称之为L。这里可能存在一个丢失更新的问题。考虑这样一个场景,线程T1和T3准备更新同一个数据。T1在另外一个线程更新L2之前获取到了L的值,T1发现这个数据处于一个可以就地更新的区域,直接使用就地更新的方式更新数据。而T3在T2更新了L之后获取L的值,发现数据处理Read-Only的区域,而创建了这个数据的一个新的版本。虽然T1、T3是同时更新,但是T1的更新就像是被丢失了。这里简单的方式是可以使用一个锁来解决,但是这样的话又会影响到Faster的性能。
-
所以这里使用的方式是使用一个safe read-only offset标记来表明一个read-offset的值已经被所有的线程知道了。在这个safe read-only offset之前的操作都不会出现上面描述的情况。这里这个safe read-only offset的维护同样基于epoch机制。这样的话直接说逻辑地址空间被分为了4个区域,safe read-only offset和read-only offset之间的区域被称之为 fuzzy region。这这个Region里面的更新操作,不同的操作类似执行不同的策略,
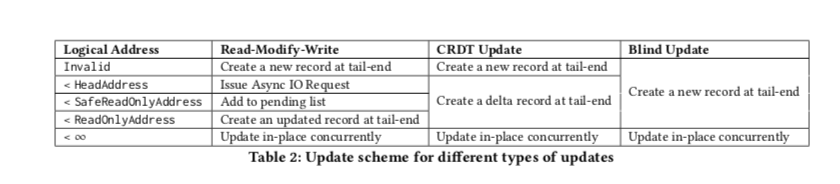
-
HybridLog这样的设计也就类似于一个将内存当缓存的功能。
0x04 评估
这里的具体信息可以参看[1].
Concurrent Prefix Recovery: Performing CPR on a Database
0x10 引言
Concurrent Prefix Recovery是Faster的Recovery机制。Write Ahead Lgging是机会所有的数据库都会使用的保证持久化的方法。Concurrent Prefix Recovery则是另外的一种保存数据持久化的机制。这里的一个概念就是transactionally consistent,它表明一个数据库在崩溃后可以恢复到崩溃之前的一个状态,其中已经提交的操作都会反映出来,但是没有提交的操作都不会被反映。而prefix recovery则比transactionally consistent要更加严格,它要求数据库可以恢复到整个数据库范围内已经请求处理的事务的一个前缀部分。
0x11 基本设计
实现prefix recovery一个简单的方法就是在一个时刻停止接收请求,直到形成一个commit-consistent checkpointing。但是这样方式在实际的系统中显然不适合采用的。这里提出了一种新的prefix recovery的方式。这里要解决的一个核心问题就是得到一个虚拟时间点t,每个执行的线程都知道在这个点之前的提交的请求和在这个点后提交来的请求。但是要在全部的线程中达成这样一个共识会是一个开销很大的操作。为了解决这个问题,这里提出了Concurrent Prefix Recovery(CPR)的概念,
-
为了得到一个 prefix snapshot,就是数据库提交所有的客户端在一个时间t之前提交的请求。而这里放松这个的一个限制,使用一个客户端本地的时候TC,而不是系统全局的一个时间,来作为这个时间点t。这里就是将系统全局的要求放松为对于单个客户端范围内的要求。Concurrent Prefix Recovery这里就被定义为:
A database state is CPR consistent if and only if, for every client C, the state contains all its transactions committed before a unique client-local timepoint tC , and none after. -
在Faster这里的设计中,采用的也是group commit的提交方式。会在一个时间提交一组的操作。这种group commit的方式在很多内存数据中被采用。一般的通过WAL实现,而这里通过asynchronous consistent checkpoints 的方式实现。asynchronous consistent checkpoints会记录下Commit之间数据所有的改动,同时由不会导致性能瓶颈。
由于这里的实现是基于前面的Faster KV Store,会用到Faster中的Epoch机制。这里假设数据库使用shared-everything的架构,所有的工作线程可以访问全部范围的数据。而且一个客户端的请求由一个对应的线程来处理。
-
为了支持CPR,这里在一个记录中保存两个数据版本,一个stable和一个live。另外有一个整数来保存当前的版本。一个稳定的状态下面,数据处于一个版本 v。一个CPR commit操作会将这个版本v变为v+1。算法分为几个步骤执行:prepare, in-progress and wait-flush。为了支持算法的运行,这里维护两个全局的变量 Global.phase和Global.version,分别表示数据库当前的状态和版本。每个线程会拷贝这些信息一个线程局部的版本,只会在epoch synchronization更新线程局部的信息,减少同步的开销。
-
Rest Phase,Commit在数据处于rest phase状态的时候被请求。设这个时候数据的版本为v。这个阶段由Commit函数触发。这个函数中更新数据库的状态为prepare,并添加一个PrepareToInProg。这个tigger会在所有的线程进入prepare状态后触发。每个线程也会更新本地的保存的信息。之后进入prepare阶段;
-
Prepare Phase,这个阶段主要是一些准备工作。为了保存 CPR consistency,这里如果遇到了大于目前版本V的数据版本,这个事务的执行abort。这个线程会更新线程本地的信息,
Interestingly, at most one transaction per thread is aborted this way for every commit, since the thread advances to the next phase, in-progress, when it refreshes. -
In-Progress Phase,下图中的PrepareToInProg函数会在所有的线程进入prepare状态之后被触发。它会更新系统的状态为in-progress,然后添加另外的一个trigger,刷新本地的信息。一个In-Progress状态的线程在数据版本为v+1的状态下面执行事务。这个操作的时候,如果一个线程遇到去读写记录集合内,且版本小于v+1的,它会将这些记录的版本信息修改为v+1。这么处理的原因是为了其它线程防止读取到这些还没有提交的数据。为了相互操作的不Blocking。这里会将记录live的数据拷贝到stable部分中。
-
Wait-Flush Phase。所有的线程进入In-Progress之后触发InProgToWaitFlush操作。这个操作会首先设置全局状态信息为wait-flush。如果对于版本信息为v+1的记录,收集起stable版本,否则收集live版本。这个时候进来的事务会按照在in-progress阶段中处理的方式一样处理,所有的记录被收集且持久化之后,更新状态为rest,并更新全局的版本信息为v+1。进入下一个操作流程。新写入的数据怎么持久化的????
没看出这里有什么很特别的地方¯\(ツ)/¯,甚至有点无聊。。可以看出来这里的操作,实际上就类似于一个状态机。

0x12 评估
这里的具体信息可以参看[2].
参考
- Faster: A Concurrent Key-Value Store with In-Place Updates, SIGMOD ‘18.
- Concurrent Prefix Recovery: Performing CPR on a Database, SIGMOD’ 19.
