Datacenter RPCs can be General and Fast
0x00 引言
这篇Paper是NSDI ‘19的一篇Best Paper。eRPC在一般的硬件上面实现了高效的RPC。和一般的RPC实现使用TCP甚至是HTTP之类的协议,eRPC更像是直接实现在IP上面的一个协议,自己处理包丢失、拥塞等传输层协议处理的问题。这里虽说是一个RPC系统的设计,不过感觉这里说成一个新的的特殊的传输层协议更加好,
eRPC performs well in three key metrics: message rate for small messages; bandwidth for large messages; and scalability to a large number of nodes and CPU cores. It handles packet loss, congestion, and background request execution. In microbenchmarks, one CPU core can handle up to 10 million small RPCs per second, or send large messages at 75 Gbps.
0x01 基本设计
之前有不少的利用RDMA使用RPC系统的Paper。eRPC认为RDMA虽然可以提供很高的带宽和很低的延迟,不过缺点也不少,最主要的一点就是需要特殊的硬件,另外RDMA存在一些可拓展性的限制,这个与RDMA工作的机制相关。eRPC使用基于Packet的IO,它会在一个packet里面放入多个请求的数据,基本的结构如下图所示。每一个RPC的packet会有一个header以及data部分,msgnbuf的布局是的所有的数据部分都保存到一起,应用可以作为一个不透明的buffer使用。第一个packet的header保存在最前面,和第一个包数据部分相邻。这样就可以在message比较小的时候使用一个DMA read操作读取这个message。这样设计的目的是将应用的数据放在一块,另外加速第一个message的处理。
-
多个message保存在一个msbuf的时候,读取第一个以外的message需要两次DMA操作,一次读取header,一次读取data。另外,为了实现zero-copy,eRPC直接使用用户拥有的msgbuf传输数据,这里就要求在eRPC有一个机制[1]处理一个msgbuf里面数据的时候,应用不能去修改这个msgbuf里面的数据。
-
这里有两个优化比较有趣可以看一下,第一个是优化使用信号作为DMA completion通知,这种方式可能带来25%的性能降低。eRPC使用的方式基于优化最常见情况的思路,通过在排队retransmitted packet之后对TX DMA queue进行flush操作,虽然这个flush操作的成本比较高,但是由于很小的重传的概率,所以总的效果高了很多,
... We flush the TX DMA queue after queueing a retransmitted packet, which blocks until all queued packets are DMA-ed. This ensures the required invariant: when a response is processed, there are no references to the request in the DMA queue.另外一个优化是在Zero-copy的请求处理的时候,为了实现zero-copy且避免一些msgbuf的动态分配,这里在处理packet buffer的时候,NIC只能在packet buffer描述符重新添加到接受队列的时候(不是很清楚这里的具体情况),
... eRPC owns the packet buffers DMA-ed by the NIC until it re-adds the descriptors for these packets back to the receive queue (i.e., the NIC cannot modify the packet buffers for this period.) This ownership guarantee allows running dispatch-mode handlers without copying the DMA-ed request packet to a dynamically-allocated msgbuf.

0x02 Wire protocol
eRPC的Wire协议采用了一些传输协议使用的客户端驱动的方式。基本的同学过程如下图所示。除了最后一个数据包之外,每一个请求packet服务端返回一个credit return。如果一个请求数据数据一个包能够搞定,这里一个请求包和一个响应包就可以完成操作。如果需要多个返回,由于这里是客户端驱动的,处理只有第一个数据包可以直接返回,后面的数据包要使用request-for-response的方式。
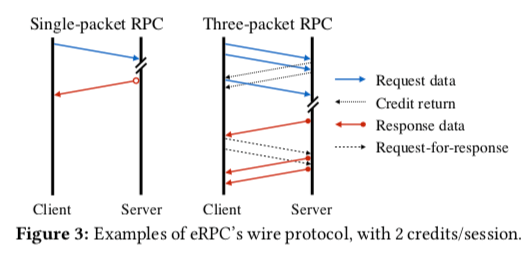
-
拥塞控制,这里讨论使用机遇RRT的Timely算法和机遇显式拥塞通知的算法,这里基本上使用的是前面的一些研究算法。在前面算法的基础上在eRPC的使用中有采用了一些优化措施,比如批量RTT测量,没有拥塞的时候避免更新一些信息等。
-
包丢失和包乱序这里eRPC也得处理,eRPC这里将包乱序也当作包丢失来处理。这个做法基于在数据中心网络中,包乱序是一个比较小概率的事件。eRPC在怀疑包丢失的时候,使用简单的go-back-N的处理方式。不过由于eRPC使用客户端驱动的方式,这里是由客户端来处理,另外这里还要处理错误判断包丢失的问题,
eRPC client then reclaims credits used for the rolled-back transmissions, and retransmits from the updated state. The server never runs the request handler for a request twice, guaranteeing at-most-once RPC semantics.
0x03 评估
这里的详细信息可以参看[1],
RPCValet: NI-Driven Tail-Aware Balancing of μs-Scale RPCs
0x10 引言
这篇Paper也是一篇关于RPC优化的一篇Paper。NI是Network Interface的缩写。与前面的eRPC设计一个新的RPC系统不同,这里的重点是Load Balancing,
Our design improves throughput under tight tail latency goals by up to 1.4×, and reduces tail latency before saturation by up to 4× for RPCs with μs-scale service times, as compared to current systems with hardware support for RPC load distribution.
0x11 基本思路
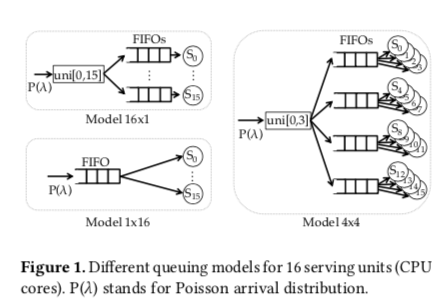
Paper中先举了一个load balance的例子。类似的例子在ZygOS的Paper中也有。这里假设一个16核的系统。使用三种任务分发的模型,1x16使用一个FIFO队列,S0到S15都从这一个队列上取得任务,另外一个完全相反的模型是16x1的模型,将任务分发到16个队列里面,每个S从自己的队列里面获取任务处理。第三个模型是一种折中的设计,使用4个FIFO队列,每个队列由4个S使用。这三种模型中,1x16的模型会明显表现的比16x1的模型要好。这个结论和ZygOS论文中的处理的结论一样,
1×16 significantly outperforms 16 × 1. 16 × 1’s inability to assign requests to idle cores results in higher tail latencies and a peak throughput 25–73% lower than 1 × 16 under a tail latency SLO at 10× the mean service time S ̄.
1x16的模型在事件应用的时候也会存在一些问题,比如多个核心对单个的队列进行操作,由此带来的同步的开销也十分显著。包这些考虑进去之后,16x1的优势会增大,另外NIC也支持RSS之类的功能。可以说多个队列的模型在实现任务分发的同时并不一定实现了load balancing。
RPCValet的出现就是为了解决这些问题。RPCValet的使用Push的模型,它的一个核心之一就是通过网络接口的深度集成来优化性能。在系统初始化的时候,每个S会注册一部分的内存到一个partitioned global address space (PGAS)中。NI可以直接访问内存,避免要通过PCIe取回数据的roundtrips。处理消息的时候,RPCValiet先将消息写入到PGAS中的一个槽位中,这个PGAS由N * S个槽位。然后RPCValet选择一个核心,并使用一个memory-mapped queue pair (QP)通知这个核心来处理这个请求。这样的处理方式可以使用消息保存的位置和每个核心处理的内存区域分开。这样既可以使用单个队列时候负载均衡好的特点,也可以实现使用多个队列不需要同步,容易实现zero-copy的特点。
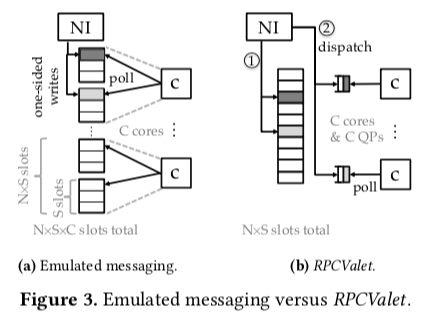
为了估计每个核心的负载,这里使用了一种节点的方式,即就是简单地追踪每个核心被分配了的处在请求过程中请求的数量。如果这里每个核心只保留一个正在处理过程中的请求,这样就和单队列的系统非常相似,不过这里带来的一个缺点就是处理完成到等到分配另外一个任务这段时间的浪费。一个优化的方式是允许有两个处理中的请求。
0x02 评估
这里的具体信息可以参看[2],
参考
- Datacenter RPCs can be General and Fast, NSDI ‘19.
- RPCValet: NI-Driven Tail-Aware Balancing of μs-Scale RPCs, ASPLOS ‘19.
