Sharding the Shards: Managing Datastore Locality at Scale with Akkio
0x00 引言
这两篇关于Sharding的Paper出自两个著名科技公司的实际系统,和一般的Sharding讲的是数据分区不同,Akkio实际是关于利用数据访问的Locality,将数据搬到离访问提更近的位置。大型的互联网公司为了系统的容灾,存储系统的数据很多是使用多个副本分别保存到不同数据中心的策略。这些公司一般又有多个数据中心,数据访问很多时候会有一些地域特性,如果将数据 or 数据的主副本保存离用户更近的位置,访问的性能也会提高。
0x01 基本架构
Sharding是数据存储系统为了实现可拓展常用的一种策略,Sharding the Shards的含义就是Data Store中的Shards继续分成更新的Shard。这里使用的Data Store是Facebook内部的一个系统ZippyDB。这里Sharding the Shards就设计到Akkio中一个核心的概念u-shard,通常的Shared这里ZippyDB中是几个GB的大小,但是对于为了实现访问的Locality而迁移数据来说,几个GB的大小还是太大了,这里就使用了一个再次发片的u-shard,它的大小在几百KB的级别。另外的,这里将一个Shard的副本称之为shard replica set,这些副本的数量,和这些副本保存的位置的配置称之为replication configuration。然后,这里有将有系统replication configuration的shard replica set称之为replica set collection。对于这样的一个集合,会有一个location handle,Akkio就负责将u-shard在不同的replica set collection之间进行迁移。
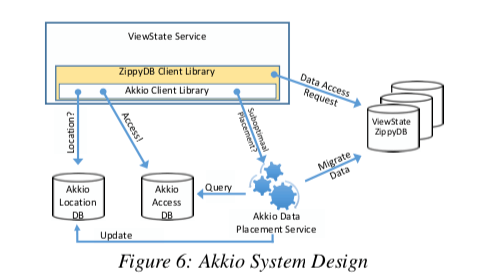
Akkio的基本思路和实现的架构还是比较简单的,不过这个真正在实际系统中实现的时候,估计要考虑非常多的问题,实现的难度也不会小。Paper中的架构以构建在ZippyDB上面为例,为了支持Akkio,一般的read(key)接口被更改为read(μ-shard-id,key),第一个参数就是一个u-shard的ID。者这里的架构中,包含了这样的几个核心组件,
- Akkio Location Service (ALS),这个就是维护每个u-shard副本的位置信息,Akkio的客户端可以通过getLocation(μ-shard-id)来获取这个信息,这个接口返回一个location handle。这个返回的信息可以被ZippyDB的客户端使用,知道如何访问合适的服务器。
- Access Counter Service (ACS),ACS就是一个访问记录,用于记录不同区域在最近的一段时间内数据的访问信息。
- Data Placement Service (DPS),在知道了u-shard不同区域的访问信息之后,DPS就可以根据这些信息来就定一个u-shard是否需要进行迁移,怎么样迁移能够取得更加好的效果。在给u-shard决定一个保存的位置的时候,主要是通过计算一个score。这个score通过对目前可用的replica set collections进行一个评分。这里计算的时候,会排除一些存储空间占用已经很大的,或者是目前负载已经很高的部分,如果迁移到这些地方可能并不会带来更好的效果。计算这个Score分为两步,1. 根据最近X天内每个数据中心内访问某个u-shard的次数,计算出一个Score,越是最近的访问,在计算Score 中的权重越大。如果第一步就计算出最高分,则直接分配。2. 如果第一步出现相同的最高分,则选择资源占用更小的一个。
这里还要解决的一个问题就是如何将数据迁移过去。Akkio对于不同的Data Store使用不同的迁移方式。ZippyDB是一个支持ACL的存储系统,这里迁移的时候就先将源的u-sahrd设置为只读,如何将数据迁移过去。刚刚迁移过去的时候,目的的u-shard也要设置为只读。然后更新u-shard的位置映射。之后就是删除源的u-shard和ACL信息。将目的的u-shard设置为可写。

而对于Cassandra,有于不支持SCL,这里要使用double-wrting的方式。等待客户端本地缓存的位置信息过期。如果将源u-shard拷贝到目的地。之后读就切换到目的位置读取,在等待本地缓存的位置信息过期之后终止双写的操作。

一般而言这样的系统,原理和基本出发思路都没有很难理解的。难点在于在实际的系统中实现。Paper中只是能能看出思路而已。
0x02 评估
这里的具体信息可以参看[1].
Slicer: Auto-Sharding for Datacenter Applications
0x10 引言
Google的Slice要解决的一个问题就是如果将请求动态的分配到一组服务器上面,处理热点和负载均衡这样的问题,在实现高可用的同时,减少系统的负载不均衡,也要降低对实际系统的影响。这一些方面来看,Slice扮演的是一个处理负载均衡的通用服务的角色,
It is used to allocate resources for web service front-ends, coalesce writes to increase storage band- width, and increase the efficiency of a web cache. It currently handles 2-7M req/s of production traffic. The median production Slicer-managed workload uses 63% fewer resources than it would with static sharding.
0x11 API 和 模型
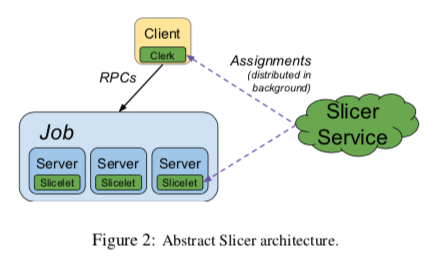
Slicer作为一个通用的sharding service,解决了一般负载均衡方式比较难实现动态负载均衡的问题。在这里task指的是运行中的一个进程,一般来说,一个数据中心内的应用会有多个task,合起来称之为一个job。Slicer的工作就是将这个job的工作划分到这些task上面。Slicer与Google内部使用的RPC框架和frontend HTTP load balancers集成在来一起。其基本架构如下,一个中心化的Slicer Server来负责将一个Key按照一定的范围(Slices)分配到一组的task,并将这些信息交给链接在客户端中的library。这里的Application keys是应用定义的,可以是User ID,也可以是其它方法生成的一个Key。对于一个Key,与其相关的状态信息会配合这个Key分配给的tasks保存,对于不同的Key,则可能分配到了不同的Key。Slicer本身不会处理应用的状态,它只会通知tasks它处理哪些部分的Keys。
- 在Slicer中,Application Key会被Hash处理为一个63bit的Hash值。每个Slice分配这个keyspace的一个range。这样的话,Splicer处理Application Key就和具体的Key无关了,无论是使用几十基本的Key,还是十亿数量级别的Key。通过Hash的方式,一个应用热点的Key更加可能被瓶平均分配到tasks中。一些应用会要求同一个Key的必须被用一个task来处理,对于有这样要求的应用,Slicer可以通过一个Key分配一致性的保证。也有很多的系统不会有这样的要求,这样可以提供弱一些的一致性保存。处理将一个Slice分配给一个task来处理外,还可以Slice的请求让多个tasks来同时处理,这里将其称之为key redundancy,对于热度的Key,还可以配置不同的task的数量。
-
使用Slicer的Server通过Slicer提供的API与Slice来进行交户。但是Server使用这些API不是完全必要的,应用完全可以忽略这些接口的存在,直接处理分配过来的请求就可以了。这个API提供多个语言的版本。下面是Java版本的例子。Slicelet接口用来查询一个接口是否分配到这里,SliceletListener可以用于监控Slice分配的变化。getSliceKeyHandle和isAssignedContinuously两个接口用于处理要求独占一个Key的需要,用于保持状态的一致性。在请求得到的时候回去到SliceKeyHandle,在返回结果的时候将获取到的SliceKeyHandle作为一个参数传回去。
interface Slicelet { boolean isAffinitizedKey(String key); Opaque getSliceKeyHandle(String key); boolean isAssignedContinuously(Opaque handle); } interface SliceletListener { void onChangedSlices(List<Slice> assigned, List<Slice> unassigned); }仅仅是在处理前后检查一个Key是否分配到一个task是不够的,因为这个分配可能在处理的过程中被分配出去,然后又被分配回来。而Clerk的接口则很简单,就是通过一个Key获取一组可用的地址,
interface Clerk { Set<Addr> getAssignedTasks(String key); }
0x12 基本架构
下图是Slicer跟多细节的架构信息。Assigner是Slicer Backend Service的一个核心,它收集服务器的健康信息、task的可用情况以及负载等的信息等。然后根据这些信息对这个系统得出一个View,从而根据这个决定如何将work分配给tasks。Assigner是一个中心化的设计,另外的组件还包含Distributor、Backup Distributor。
- 如何将work分配给task的信息由Assigner产生,这些信息Distributor、Backup Distributor也会保存。Distributor和Backup Distributor负责将这些信息分发给客户端,客户端也会缓存这些信息。也就是说,Assigner并不会直接将分配的信息分发给客户端。由于可能存在大量的客户端,而Assigneder的数量又比较少,大量的客户端访问可能给Assigneer代理不小的压力。Slicer通过引入Distributor,使用一个两层的设计r来解决这个问题。Assignment信息的分发是一个Pull的模型,客户端作为一个订阅者的角色。拉取的对象就是Distributor,如果Distributor有这个信息,则直接返回,如果没有,则请求Assigner。
- 实际使用中会部署多个的Assigner,这样做的好处就是提高了系统的可用性。但是缺点是可能带来的分配意见不同的问题。为了缓解这个问题,Assigner会将这些分配的信息保存到一个optimistically-consistent的存储系统中,在保存之前,会读取分配信息,产生一个递增的版本好,然后将这些新的信息写入到这个存储系统中,覆盖之前的数据。如果这个时候发生并发的写入,则重试操作。一般的steady状态下面,一个job只会使用一个Assigner产生的分配信息,这个Assigner对于这个Job来说就是一个preferred Assigner。
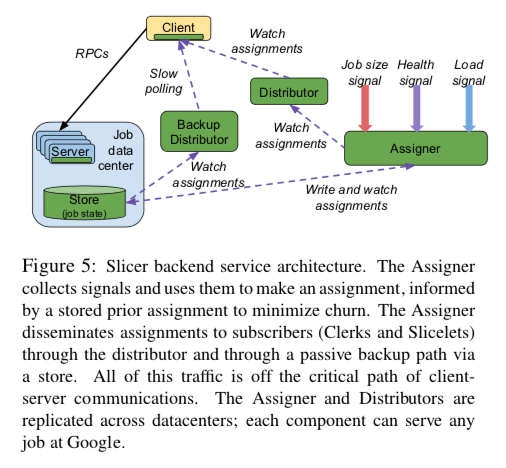
容错是这样的系统很重要的一个方面。这里利用了多种的手段来实现容错。第一个就是图中的Distributor 和 Backup Distributor。一般情况下,Client是从Distributor获取信息。另外的一个Backup Distributor作为 Distributor备份,而且Backup Distributor只会和Distributor使用一部分不重要的代码。Backup Distributor演进的速度更慢,更加简单。如果系统中此时只有Backup Distributor可用,系统就降级为根据不久前的负载和健康信息的一种静态的sharding方式。另外的一些容错的策略有,1. 多个Distributor和Assigner被部署在不同的数据中心,客户端可以访问任意的Distributor,Distributor也可以访问任意的Assigner。一般情况下,选择的会是本数据中心内的,这样可以容忍网络分区。可以访问任意Distributor和Assigner的策略可以在一部分Distributor和Assigner失效的情况下依然可以工作。2. 即使Slicer的所有的服务都不可用,客户端还是可以根据缓存信息继续工作。
负载均衡
Slicer的一个核心作用就是实现更好的负载均衡。前面提到Slicer会将63bit的keyspace划分为range来处理,如果一个range里面存在热点,Slicer会考虑将其分裂,例如将[a, c) 的range分裂为[a,b),[b,c)。另外为了避免划为了太多的range,Slicer也会在适当的时候将一些range合并。Slicer只会负责分配这些work到tasks,而给一个job添加CPU和内存这样的操作交给了其它的系统。当Slicer做出需要重新分配的过程如下,
-
将一些Key重新分配,比如分配给由于类似机器故障等原因导致的不在属于这个Job的tasks。
-
根据配置增加 or 减少 key redundancy。
-
合并一些cold slicers。满足这样的一些条件下进行这样的操作,
(a) there are more than 50s lices per task in aggreate, (b) merging two slices creates a slice with less than mean slice load, (c) merging two slices does not drive the receiv- ing task’s load above the maximum task load, and (d) no more than 1% of the keyspace has moved. -
使用一种贪心的策略来重新分配。在重新分配操作是,Slicer必须遵守一些约束,比如分配给一个key的最大、最小的task的数量。同时也会避免一次改动过多的分配,这里称之为key churn,即每次改动分配的Key占keyspace的比例。这里可以理解为每次在考虑到这些限制的情况下,去尝试移动造成最大不均衡的部分,
... for each slice in the hottest task, three possible moves are considered: reassigning the slice to the coldest task to displace the load, redundantly assigning the slice to the coldest task to spread the load, or removing the slice which offsets the load to existing assignees.另外,如果负载最大的task的负载都小于25%的话,Slicer就不会执行rebalancing的操作。 这里Paper还解释了为什么consistent hashing的原因,一种consistent hashing的变体load-aware consistent hashing。
Strong Consistency
Slicer这里的Strong Consistency指的是在某个时刻,task知道的一个分配给的key确实是分配给它的。一个简单的做法就是维护关于每个Key的一个租约,重新分配的时候,新分配给的task必须等到前面的租约过期。但是这样的一个问题就是现在用于实现这个租约的Chubby无法拓展到为很大量的key维护一个租约信息。这里使用另外的一种bridge lease的方式来解决这个问题。这里Assigner会请求一个job lease,用于实现一个时间段内只会有一个Assigner来写入某些的分配的信息。在分发这些分配信息的时候,这里会引入一个guard lease,只有在获取来这个guard lease之后,Slicelet才可以读取这些请求。但是Clerk也就是客户端的部分是不需要这个lease的,因为它发送了一个错误的请求之后会被直接拒绝,之后重试即可。在修改分配信息的时候,必须等到guard lease被回收,这里常用的方式就是等到这个lease过期。但是这里会引入一段时间的不可用,这个是不可接受的。解决这个问题的思路是这样的:假设分配信息A2取代了A1,对于那些A1和A2都相同的分配,完全可以继续使用,而不用让其不可用。对于A1 ∩ A2,即两者相同部分,Assigner在产生和分配A2的时候,会创建一个bridge lease,在A1 A2交替的中间时期使用,
The Assigner writes and distributes assignment A2, creates the bridge lease, delays for Slicelets to acquire the bridge lease for reading, and only then does it recall and rewrite the guard lease. A Slicelet is allowed to use the intersection if it holds the bridge lease.
0x13 评估
这里的具体信息可以参看[2].
参考
-
Sharding the Shards: Managing Datastore Locality at Scale with Akkio, OSDI ‘18.
-
Slicer: Auto-Sharding for Datacenter Applications, OSDI ‘16.
