The φ Accrual Failure Detector
0x00 引言
这篇Paper提出的算法被后面不少的分布式系统使用。一般故障探测的思路是给出一个节点(or 进程)是否已经故障的bool型的判断。而这篇Paper的思路则从故障探测不是完全可靠的出发,给出的是一个是否故障的概率值。
0x01 基本概念
故障探测中,实际的环境中时很难区分真正的故障还是low process。有这样的两个性质,
Property 1 (Strong completeness) There is a time after which every process that crashes is permanently suspected by all correct processes.
Property 2 (Eventual strong accuracy) There is a time after which correct processes are not suspected by any correct process.
process故障与否的情况,被别的进程认识到从市存在一个时间差。由于存在误判和从故障到意识到故障的时间查,评价一个故障探测器的两个重要指标一个市故障发现的时间,另外一个就是误判的概率,
Definition1(Detection time T_D) The detection time is the time that elapses since the crash of p and until q begins to suspect p permanently.
Definition 2 (Average mistake rate λ_M ) This provides a measure of the rate at which a failure detector generates wrong suspicions.
现在的很多故障探测时基于心跳的方式,假设一个进程q监控另外一个进程p的健康情况,
- Heartbeat failure detectors,最常见的方式就是周期性地p向q发送心跳消息,如果在一个预定义的时间段∆to内,q没有收到q的心态,q就认为p已经发生故障。∆to大小的设计决定了故障发现的时间和误判的概念。Heartbeat failure detectors这里可以采用的一个优化方式就是基于transmission time来决定一个∆to。
- Adaptive failure detectors,比如Chen-FD方法的思路是基于网络流量的概率性分析,这个协议使用最近几次的到底时间去样来预测下一个心条达到的时间。∆to的设置就根据这个预测的时间在假设一个固定的safety margin α。Bertier-FD方法的基本思路和Chen-FD是一样,不过这个safety margin α不是一个固定的值,而是根据RTT计算出来的一个值。
0x02 基本思路和实现
The φ Accrual Failure Detector的基本思路是使用是否故障的概率判断代替是否故障的bool类型的判断。这里使用 susp_level_p 来表示评估进程p是否已经故障的函数,susp_level_p(t)的输出会有以下的性质,
Property 3 (Accruement) If process p is faulty, the suspicion level susp_level_p(t) tends to infinity as time goes to infinity.
即如果进程确实故障,susp_level_p输出的值会随着时间趋向于无穷大.
Property 4 (Unknown upper bound) If process p is correct, then susp_level_p(t) is bounded.
如果进程p是健康的,则函数输出值是有界的.
Property 5 (Reset) If process p is correct, then for any time t0, susp_level_p(t) = 0 for some time t ≥ t0.
如果进程p是健康的,则在一个时间短后,这个susp_level_p输出为0.
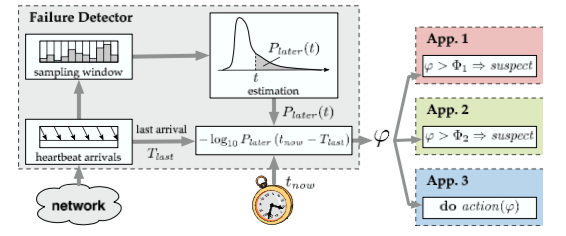
在实现中,The φ Accrual Failure Detector使用基于Window Size的心跳时间采样的方法,使用一个固定长度的队列记录最近若干次的心跳间隔时间,使用以下公式计算φ(T_now), \(φ(T_{now}) = -\log_{10}(P_{later}(T_{now}-T_{last}))\) 其中T_last表示最近一次收到心跳的时间,T_now表示这次收到心跳的时间。而P_later的定义如下, \(P_{later}(t) = \frac{1}{\sigma\sqrt{2\pi}}\int_t^{+\infty}e^{-\frac{(x-u)^2}{2\sigma^2}}dx = 1 - F(t)\) 后面是一个正态分布的积分。这里主要要处理的参数就是期望和方差。这两个值就使用之前Window Size采样计算出来。The φ Accrual Failure Detector整体的思路如下图。从上面的方程来看,T_last - T_now会被函数P_later转化为0 - 1 之间的一个值,-log10的函数在(0, 1)可去值为0到+∞,如果t越多,P_later积分得出的值就会约小,而会使得φ(T_now)得出的值越大。
0x03 评估
这里的具体消息可以参看[1],
SWIM: Scalable Weakly-consistent Infection-style Process Group Membership Protocol
0x10 引言
在分布式系统中,通常是一个节点的集合一起来实现一个系统。而Membership Protocol就是处理这个集合中的节点如果认识这个集合中另外节点的Protocol。SWIM节点主要要处理两个问题,一个就是节点的故障探测,另外一个就是信息的传播。从SWIM名字上就可以看出SWIM成员协议的几个特点:1. Scalable,可拓展,2. Weakly-consistent 弱一致性,3. Infection-style,类似Gossip一样的与集群中部分节点交换信息的方式,而不是全部广播。
0x11 基本思路
SWIN包含两个主要的组件,1. Failure Detector Component,用于探测成员的健康状况,2. Dissemination Component,用于发送成员状况信息的组件。
-
SWIM Failure Detector,SWIM的故障探测器使用2个参数,一个是一个协议的周期T’,和一个整数K。每一个周期内,集群中的一个节点随机选择一个节点,像其发送ping消息,并期待它恢复ack。如果在一个时间内没有收到这个选择节点的ack回复。这个时候并不会直接认为这个节点已经挂掉了,而是会选择另外的K个节点,向它们发送ping-req消息。在收到这个ping-req消息之后,节点会使用ping消息来探测指定节点是否存活。这种方式避免来一个节点做出决定,这样更加容易发生误判。如果在这个时间周期内,主动探测的节点没有收到直接的ack回复,也没有收到K个节点间接的ack回复,这个节点在自己的local membership list中标记这个被探测的节点为故障。之后被Dissemination Component处理。
-
Dissemination Component,节点失败的消息使用多播的方式发送给集群中的其它节点。对于主动离开和新节点加入的情况也可以使用同样的方式。新加入的节点至少要知道集群中一个已经存在的节点才可以加入。也可以使用一个指定的节点来处理新节点的加入,
This can be realized through one of several means: if the group is associated with a well known server or IP multicast address, all joins could be directed to the associated address. In the absence of such infrastructure , join messages could be broadcast, and group members hearing it can probabilistically decide (by tossing a coin) whether to reply to it.
0x12 优化
SWIM的基本协议如上。除此之外,Paper中还提出了几项优化的措施,
- Infection-Style Dissemination Component,在最初的设计中,Dissemination Component使用的是多播的方式,但是这个在很多的情况下是不能使用的。如果不能使用就只能使用一个个的“广播”的形式,比较低效。Infection-Style Dissemination Component就是为了优化这个问题。这里优化的一个讨巧的设计就是在故障探测组件离开的ping、ping-req和ack消息中捎带上要广播的消息。
- Suspicion Mechanism,主要目的是用于减少误判的概率。这个其实不能说是一个优化,而是一个在故障发现时间和误判概率之间的一个权衡。在一个节点探测的周期中,如果它没有直接也没有间接收到被探测节点的ack消息,不是将其标记为故障而是标记为怀疑故障。怀疑节点会被暂时当作是非故障节点,如果其它节点能够收到被探测节点的ack,则发送消息“纠正”这个怀疑,被探测节点本身收到自己被怀疑的消息也是要做“纠正”处理。如果在一定时间内没有收到这个被探测节点依然存活的消息,那这个节点就被标记为故障。
- Round-Robin Probe Target Selection。简而言之就是不是使用随机选择的方式,而是造member list里面依次选择。
0x14 评估
这里的具体信息可以参看[2].
HyParView: A Membership Protocol for Reliable Gossip-Based Broadcast
0x20 引言
这篇Paper也是描述了一种Membership Protocol ,也是基本常见的Gossip的思路。这里的一个重要的概念是Partial Views,表示一个节点本地保存的一部分关于所有成员节点的信息。在HyParView中,维护了两个不同的节点集合,一个小一点的集合称之为active view,大小为fanout + 1,这个集合中的节点知道彼此的存在,一个大一些的passive view,大于 log(n)数量,
A small active view of size fanout+1, as links are symmetric and thus each node must avoid relaying each message back to the sender. A larger passive view, that ensures connectivity despite a large number of faults and must be larger than log(n). Note that the overhead of the passive view is minimal, as no connections are kept open.
0x21 基本思路
在Active View中的节点,会保持一个连接用于消息传输。这里的连接是对称的,意味着节点q的active view中包含了p,那么p的active view中也包含了q。这里默认使用连接方式是TCP。在active view之外,有一个大小更大的passive view,这个view里面的节点不用于消息传播,这里面的节点可以用于在active view里面的节点故障的时候替代active view里面的节点。
-
一个节点打算加入一个集群的时候,它必须知道一个已经在集群中的节点。这个节点称之为contact node。想要加入的时候,这个节点和contact node建立一个TCP连接,并发送一个JOIN请求给contact node。contact node在收到了JOIN请求之后,contact node会将这个节点加入到active view中,即使会导致contact node会将一个active view中的节点drop掉。这种想要drop的情况下,contact node会发送一个DISCONNECT通知个一个从active view中随机选择的节点。contact node然后发送一个FORWARDJOIN请求给这个contract node的active view中其它节点,FORWARDJOIN会被一个步伐长度传播,实际上就是跳过一部分然后发送一个。这里涉及到两个 Walk Length (ARWL),第一个称之为Active Random Walk Length (ARWL),表示这个FORWARDJOIN被最大传播的距离,一个Passive Random Walk Length (PRWL)表示哪些节点会加入到一个passive view中,后面解释。
-
一个节点p接受到FORWARDJOIN请求的时候,执行下面的操作步骤,1. 如果消息的time to live等于0的时候,或者是p的active view中的节点数量为1的时候,将新的节点加入到active view中。在必要的时候执行前面描述的DISCONNECT操作。2. 如果time to live等于PRWL,将这个新的节点加入到其passive view中,3. 递减这个消息的time to live值,4. 如果没有添加到p的active view中,从p的active view中随机选择一个传播这个请求。
-
Avctive view使用reactive测量管理。当一个节点p认为其active view中的一个节点故障的时候,会从其passive view中随机选择一个节点q,与其建立一个TCP连接。如果这个连接建立失败,则考虑这个节点q已经故障,则将这个节点q从p的passive view中移除,另外选择一个节点q‘。连接成功建立的时候,p向q发送一个NEIGHBOR请求,请求保护了它的标识符和优先级。这个优先级取决于p的active view中元素的数量,越少优先级越高。高的优先级会使得q更大可能接受这个请求,即使可能造成需要将一个节点从q的avtive view中移除。q在接受了这个请求的时候,p将q从passive view中移除,加入到actvie view中。如果q拒绝了这个请求,重新选择一个重复操作。
-
Passive view使用 cyclic测量管理。每个节点周期性地进行shuffle操作。节点发送一个SHUFFLE请求,带有自己的标识符,active view中的ka个节点,passive view中的kb个节点。这里的两个参数为需要设置的值。节点q在接受到这个请求之后,减少这个请求的time to live。如果这个请求的time to live大于0且q的active view的大小大于1,这个节点会直接从active view随机选择一个节点转发这个请求,这个随机选择的节点不能是消息来的节点。否则则接受这个请求,然后使用一个临时的TCP连接发送一个回复。SHUFFLEREPLY消息中包含了从passive view中随机选择的一些节点,
Then, both nodes integrate the elements they received in the SHUFFLE/SHUFFLEREPLY message into their passive views (naturally, they exclude their own identifier and nodes that are part of the active or passive views). Because the passive view has a fixed length, it might get full; in that case, some identifiers will have to be removed in order to free space to include the new ones.
0x22 评估
这里的具体信息可以参看[3].
参考
- The φ Accrual Failure Detector, SRDS ’04.
- SWIM: Scalable Weakly-consistent Infection-style Process Group Membership Protocol, DSN ‘02.
- HyParView: A Membership Protocol for Reliable Gossip-Based Broadcast, DSN ‘07.
