Fast Database Restarts at Facebook
0x00 引言
这篇Paper将的是Facebook使用的在线分析型的数据库Scuba的快速重启机制。之前的一些数据库系统比如RAMCloud和SiloR这类in-memory的存储系统快速重启的方式基于使用大量的磁盘提供很大的带宽。Scuba也将数据保存在内存之重,它快速重启的思路主要是利用共享内存,
... We can therefore use shared memory to preserve memory state from the old server process to the new process. Our solution does not increase the server memory footprint and allows recovery at memory speeds, about 2-3 minutes per server.
0x01 基本思路
Scuba的基本架构如下图所示。两种主要的角色是aggregator和leaf。另外一个Scuba “tailer”的角色负责将数据从Scuba之外拉取到Scuba之中。每N行数据or每个t秒钟,tailer就选择一个Scuba的leaf server,将这些数据发送到这个服务器。选择服务器会先随机选择两个,在根据leaf服务器的当前状态,比如内存使用量,选择其中的一个。在Facebook的使用中,一台物理其中运行8个leaf server和一个aggregator server,leaf server负责保存数据。重启其中的一个leaf server不会影响到其它的leaf server继续工作。Scuabe另外的一些信息如下,
-
Scuabe中Leaf Server,保存一个表的一部分,使用基于列的存储引擎。Leaf Server中内存布局如下图所示。首先是指向一个table数据的指针,Table的结构中保存的是指向row block的指针。一个row block保存65,536个联系的rows的数据,row block的数据会以一定的大小压缩保存(The row block iscapped at 1 GB, pre-compression, even if there are fewer than 65K rows)。Row Block内爆粗的一些元数据和数据本身。
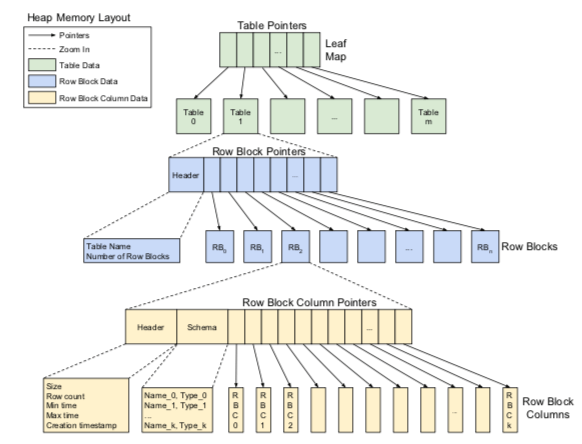
-
使用共享内存进行快速回复可以使用的一种方式,就是将在堆上面分配的内存都在共享内存的区域分配。不过这样的一个缺点就是与现有一个一些机制存在不少兼容的问题。所以Scuba这里使用的方式是在shudown的时候将数据拷贝到共享内存,如果在重新启动的时候从共享内存中重新加载。
-
同样地,Scuba也会将数据备份到磁盘上面。使用共享内存快速启动常用于系统的神经。而由于crash之类的原因导致的重启一般就使用从磁盘上面回复的机制,因为Crash可能导致内存中的数据存在错误。
0x02 恢复操作
Scuabe的恢复操作可能是从磁盘中恢复,也利用共享内存进行恢复。从磁盘中恢复操作主要有这样的一些步骤,
- 通过一个API通知指定的Scuba Leaf Serber进行关闭操作。收到这个操作之后,Leaf Server就不会理会后面新到底的数据和请求,但是会继续处理进行中的请求,处理完进行中的同步数据到磁盘上面的请求。Scuba不是一个完全不保证数据丢失的数据库,作为分析用的数据库,应用时可以容忍一部分的数据丢失的。
- 重新启动一个Servre的速度慢得多,因为数据都要从磁盘中加载。Scuba这里的一个做法是在加载部分的数据的时候,也可以处理查询请求,部分只会返回在已经加载了部分的数据。另外可以在没有加载完数据的时候就处理新的数据,但是会尽量避免这么做。
在使用共享内存进行恢复的时候,需要对Scuba的内存布局进行一些修改,部分还是和原来的基本上是一样的,可以从下图中看出,这个和上面的图很类似。在共享内存中数据的布局主要少了一层的间接,这个是因为 row blocks 和 row blocks columns的数量在内存分配的时候就已经确定了,这样就可以将其分配到一个连续的位置。每个lead server在共享内存中保存一份leaf元数据,即使同一时刻只会有一个serevr使用共享内存。每个leaf server使用一个固定的地址来定位在共享内存的leaf元数据的地址,
In that location, the leaf stores a valid bit, a layout version number, and pointers to any shared memory segments it has allocated. There is one segment per table. The layout version number indicates whether the shared memory layout has changed; note that the heap memory layout can change independently of the shared memory layout.
当使用共享内存进行恢复操作的时候,主要有这样的一些步骤,
-
Shutdown操作的时候,会将所有的table的数据拷贝到共享内存之中。并在推出之前设置共享内存中的valid bit。
-
启动新server的时候,先要检查这个valid bit。如果检查通过,直接从共享内存中拷贝回来,如果没有设置,只能从磁盘中恢复。
-
另外,在拷贝处理和拷贝回来的是,可能导致的一个问题就是加大内存的消耗。这里使用了一个渐进式的方式。不是一次性就分配所有的需要的内存,而是以block为粒度,没拷贝一部分就是在原来的地方释放一部分内存,这样实际上多使用的内存就少多了,
There are hundreds of tables (and thousands of row block columns, with a maximum size of 2 GB) per leaf servers, so this method keeps the total memory footprint of the leaf nearly unchanged during both shutdown and restart.
0x03 评估
这里的具体信息可以参看[1].
Constant Time Recovery in Azure SQL Database
0x10 引言
这篇Paper是介绍Azure SQL Database快速恢复机制。通过将事务操作范围三个不同的种类,不同的种类各自使用不同的恢复方式,Azure SQL Database的Constant Time Recovery(CTR)机制可以实现1. 数据库可以在常数的时间内恢复,而与用户的workload和事务大小,2. 事务回滚可以在常数时间内完成,而不论事务的大小,3. 持续的事物log删短,即使当前运行着长事务,
... This paper describes the design of our recovery algorithm and demonstrates how it allowed us to improve the availability of Azure SQL Database by guaranteeing consistent recovery times of under 3 minutes for 99.999% of recovery cases in production.
0x11 背景
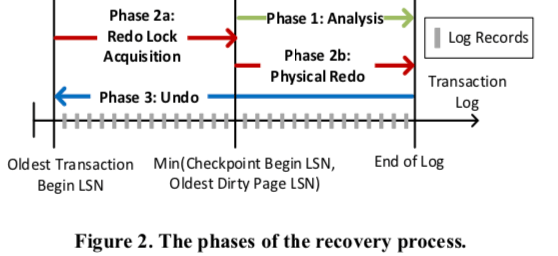
SQL Server的WAL算法就是基于著名的ARIES算法。日志和数据分开保存,在实际去修改数据page之前,会将这些操作记录到日志之中。每个日志回由一个唯一的LSN标明,这里日志的格式已经数据Page中记录的一些数据也基本和ARIES一致,这里就可以直接看看ARIES的Paper。一般而言,数据库恢复操作分为三个主要的步骤,示意如下图所示,
-
Analysis,分析这一步骤主要完成的事情,一是回滚任何因为Crash没有提交的数据,二是最旧的数据Pages上面对应的LSN,这个信息会记录到Page上面,用于标记这个Page上面应用到LSN的位置,这里就用于找到要开始恢复的起点。
-
Redo,Redo简而言之就是将由于Crash没有修改完成Page但是已经完成提交的事物,继续操作完成。根据前面得到的Oldest Dirty Page LSN。这里的操作会占用不少的恢复时间,特别是在大尺寸的事务的情况下。
-
Undo,Undo用于回滚由于Crash没有完成的操作。这部可以在开始接收用户操作的情况下进行,不过如果操作遇到了没有undo完成的部分,则会block这些操作,
... Undoing these operations is also logged using Compensation Log Records (CLR) to guarantee that the database is recoverable even after a failure in the middle of the Undo process. The log records for each transaction can be efficiently traversed using the Previous LSN stored in each log record.
另外,SQL Server的并发控制基于MVCC。对于每个用户的更新操作,SQL就地修改数据Page,另外在一个append-only的version store记录旧版本的数据,旧的版本会有一个指针指向旧版本的数据,这样多个版本会被组成一个chain。在访问一行的数据的时候,会遍历这个chain,通过这个事务的snapshot时间戳来发现合适的可见的数据版本。。基于ARIES的WAL算法,和SQL Server的MVCC机制,会是下面设计Constant Time Recovery算法的基础。
0x12 Constant Time Recovery
在基本思路上面,CTR将数据库的操作分为这样的三种,分别采用相适应的恢复思路,
- 数据更新的操作,用户执行DML语句导致数据更新。CTR利用SQL Server的MVCC机制来实现立即的undo操作,而不用使用txn log来undo每个操作。由于每个更新都是用版本的方式来记录,每个版本的数据会记录上对应事务的ID,这样的话通过直接查询这个事务的状态(活动中,已经提交,abort)。当一个事务abort时候,只是将这个事务标记为abort,即标记了所有有这个事务产生的数据都是无效的数据。在恢复的分析阶段,会得出每个事务的状态,在Redo阶段会恢复出在故障时候数据库中包括verion store在内容的数据。Undo阶段,直接标记没有提交的事物为abort,这样的话这些事务造成的修改都是不可见的。
- 系统操作,这里的操作主要是指数据库维护内部结构的操作,比如存储空间的分配和方式,以及维护B-tree的结构等。这些操作和数据库更新的操作不同,它不好用对版本的方式解决。这部分的undo操作在后台完成。
- Logical and Other Non-versioned Operations,其它的就是一些类似加锁一样的逻辑操作,后者是在系统启动的方式就得去访问,在redo、undo发生之前。CTR这里使用额外的一个SLog,用于记录相关的一些操作,而不用处理全部的事务的log。
Persistent Version Store
为了实现持久化和恢复一行数据的早期的版本,SQL Sever实现了一个Persistent Version Store (PVS),在PVS中,一行数据的不同版本也会被组织为链式的结构。利用这个PVS,CTR可以实现之前的已经提交的版本,而不用等到undo操作来恢复哪些没有提交的事物造成的修改。PVS通过将不同版本的一行的数据保存在事务日志和数据库中来使得其可以恢复,在CTR中,这些数据得保存到一句提交的版本都已经被应用到了数据页上面,这个可能造成PVS的尺寸比较大。另外,用日志记录这些版本的数据也会造成额外的一些开销。为了解决这个问题,PVS引入了两层的设计,
-
In-row Version Store,这个是将早些的版本和最新的版本保存到一起的一种优化,类似于一些MVCC实现的时候采用的不完整保存每个版本的数据,而是先保存一个基线版本,另外的版本保存的是和这个版本的差异信息。早通常情况下,不同的版本之间的数据差异是比较小的。这些每次访问没有保存完整数据的版本的时候就需要进行重建操作,虽然这个会花费一些时间,但是和直接将数据保存到另外的Off-row Version Store相比,不需要访问另外的Page,还是快了很多。这种方式还节约了不少的存储空间,以及降低了logging的开销。在删除一行的时候,就是标记为这一行删除,数据保留可能用于重建之间的版本,更新操作的时候不仅仅要就地更新最新的版本,还要最佳和上一个版本的差异信息。这种方式的缺点就是可能增加一个B-tree Pages中行的大小,造成更多的Page分裂等的操作。
-
Off-row Version Store,为了结合In-row保存和Off-row保存的优点,PVS这里是采用两个混合使用的策略。每个Off-row Version Store被实现为一个没有索引的table,因为都是考更新的版本中保存的位置信息来进行寻址。每个版本的行的数据都在这里面保存为单独的一行,还会添加另外的一些列来保存一些额外的信息,
Each version of user data is stored as a separate row in this table, having some columns for persisting version metadata and a generic binary column that contains the full version content, regardless of the schema of the user table this version belongs to.Off-row PVS使用通常的日志机制来实现恢复。在旧的版本不在需要的时候会进行GC的操作。
Logical Revert
Logical Revert用于将已经提交的数据版本恢复到数据Page中的main row中,这里是为处理由于abort的事物导致的将之前的数据保存到了PVS中,但是main row中保存的数据缺失无效的abort的数据。这里会有后台的任务来处理,这个操作也不是产生版本信息的操作。另外这里的一个优化是,如果是新的事物遇到了这样的一个aborted的数据,它去执行Logical Revert操作可能对这个事物操作的性能带来比较大的影响,这里的一个优化是让这个事物可以直接修改这个aborted了的版本的数据。为了追中事物执行的状态,这里引入了一个Aborted Transaction Map(ATM)。
- ATM使用事物ID可以快速定位一个事物的状态。一个事物abort之后,在释放锁之前,将这个事物abort的状态信息添加到这个ATM中。并写入一条abort信息的日志。形成一个checkpoint的时候,这个ATM的所有信息都会被写入到日志中,作为checkpint操作的一部分。在restart的时候,通过读取上一个checkpoint中的ATM的数据和后面日志记录的abort信息来重新构建这个ATM。在一个abort的事务产生的所有数据都被清除之后,就可以从ATM中清除。这个操作也会产生一条FORGET日志记录,表明这个事务产生的数据已经被正确清除。
- 维护一个ATM还是带来一些额外的开销,特别是OLTP类型的场景。事务多但是每个事务执行的时间都很短,这个就会给ATM维护带来比较大的开销。CTR通过判断这个事务操作的大小,决定使用CTR的方式还是传统的方式,对于短事务,直接使用传统的方式就可以了。
Non-versioned Operations
在数据库中,像获取索引 or 表级别的粗粒度的锁,分配数据Page之类的元数据更新操作,更新关键的元数据信息等。这些操作和数据的更新不同,都是不带版本信息的操作。为数据在故障之后的快速恢复,CTR机制这里使用两种方法来加速恢复的操作,
-
SLog: A Secondary Log Stream,SLog用于记录非版本化的操作,这些操作在redo or/and undo的时候得使用。在一般的WAL方法中,处理这些得扫描全部的事物日志。SLog的存储使得可以快速定位处理这些信息。Slog保存在内存之中,并持久化到磁盘上面,内存中的SLog由日志项的LSN排序之后保存,保存为一个链表。为了快速处理undo,有同一个事物产生的日志也组织为一个链表。基本的组织结构如下图所示。在非版本化的操作的时候,数据库会产生一条日志写入到事物日志中,同样的,这些数据也会被添加到内存中的SLog中,在checkpoint操作的时候,LSN小于这个Checkpoint所在的LSN的SLog的信息都会被持久化到磁盘上面。同样地,和前面的ATM类似,重建这个SLog也是依赖于上一个的Checkpoint保存的数据和分析这个Checkpoint之后的数据。在恢复操作的第一步分析完成之后,数据库就可以重建这个SLog。
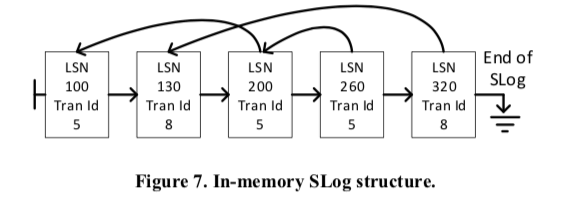
-
重建之后的SLog会被用于后面的Redo和Undo操作。在CTR中,Redo操作被拆分为两步,1. 从最老的没有提交事物的开始的LSN到min(Oldest Dirty Page LSN, Checkpoint Begin LSN),使用的方式是利用Slog,2. 从min(Oldest Dirty Page LSN, Checkpoint Begin LSN)到日志末尾,使用的是常规的操作方式。在Undo操作的时候,数据修改操作使用常规的方式处理,非版本化的操作undo才会使用到SLog,而这些操作一般都只有很少的一部分,undo这些操作会是一个很快的过程。
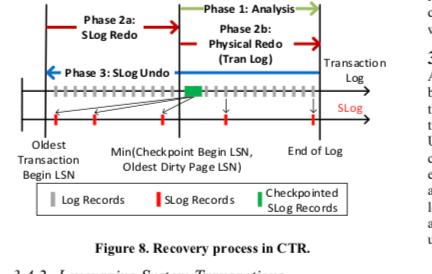
-
Leveraging System Transactions。为了减少SLog的大小,CTR这里提出的一个优化策略是使用System Transactions。这里主要讨论的是存储空间分配的恢复的优化。这些操作也是非版本化的。为了避免这些操作也使用S Log,CTR通过System Transactions来处理存储空间的分配和释放。这些操作的恢复操作使用一般的事物日志,由于这些操作一般占用很小,处理这些对整个系统恢复的时间影响不大。在CTR中,分配一个新的数据Page都是会被立即提交的操作,然后标记为这个Page为“potentially containing unused space”,如果用户的事务被回滚,这些空间就可以被回收。一个后台的cleanup线程会定期扫描数据库发现这些的Pages,如果发现这些数据Page可以被回收,则执行回收操作。对于Page的释放,则不能满是就提交,而是要等到事务已经提交了,CTR通过将释放推迟到相关的事务已经提交。对于比较大量的Pages的释放操作,事务将其标记为““deferred deallocated”,信息会被添加到SLog中,实际的回收操作会被推迟到事务提交之后,并在后台处理完成回收操作。
其它优化
除了上面采用诸多的优化恢复时间的机制之外,CTR这里还使用了其它更多的优化策略,
-
Redo Locking Optimization。在之前的恢复方式中,需要恢复没有提交的事务获取的所有的锁,这样就不回等到Undo操作完成就可以执行用户新的事务请求了。但是在CTR这里,Undo操作的效率非常高,这里直接就等到Undo操作完成才让数据库处理新的事务请求,这样Redo操作就不需要恢复获取的锁了。但是这样有几个问题,1. 从节点故障恢复的时候,比如使得其可以再去处理Primary发送过来的请求,2. 处理分布式事务的时候,这里具体的case可以参看[2]。总的来说,这里还是利用了SLog,
... SLog is used to track and reacquire low-volume, coarse-grained locks, such as table or metadata object locks, during Redo, while a new locking mechanism is introduced at the transaction level to handle granular locking, at the page and row level, where the volume can be extremely high.在Redo操作的结尾,每个没有提交的事务都会使用其Transaction ID请求一个排它的Transaction Lock。当一个新的事务范围到相关的行的时候,它将请求一个共享的锁,如果之前事务在恢复的过程中,这个操作会被Block。当之前的事务完成恢复操作,无论是提交还是Abort,释放了锁之后之后的事务就可以访问对应行的数据。
-
Aggressive Log Truncation,简而言之就是通过利用Logical Revert 和 the SLog,CTR可以只使用最后一个Checkp后面的日志部分,而不是最老一个没有提交的事务开始的日志之后的部分。这里就可以在保留用于undoing system transactions信息的基础上激进地截断日志,
The log must still be preserved for undoing system transactions without versioning, but it can now be aggressively truncated up to the minimum of a) the Checkpoint Begin LSN of the last successful checkpoint, b) the Oldest Dirty Page LSN and c) the Begin LSN of the oldest active system transaction. -
Background Cleanup,即在后台处理Logical Revert、后台清理In-row Versionq和Off-row Version。
这些操作不了解数据库的具体实现的话,还是很难理解其行为,以及为什么这样。
0x13 评估
这里的具体信息可以参看[2],
参考
- Fast Database Restarts at Facebook, SIGMOD ‘14.
- Constant Time Recovery in Azure SQL Database, VLDB ‘19.
