##Hyperion: Building the Largest In-memory Search Tree
0x10 引言
这篇Paper也是SIGMOD ‘19上面的一篇关于索引的一篇Paper。这篇Paper的关注点在Trie类型的索引如何节省内存方面。在去年的SIGMOD上面就有一篇类似的Paper,HOT。利用将多个BiNode压缩保存在一个节点内的方式实现了很低的一个内存使用。这篇Paper提出的Hyperion,通过紧凑的节点设计和定制的内存分配方式实现了更低的内存占用,不过在性能方面也做出了也妥协,
Hyperion can significantly reduce the index memory footprint and its performance-to-memory ratio is more than two times better than the best implemented alternative strategy for randomized string data sets.
0x11 基本思路
Hyperion第一个设计就是使用了更大的partial key来减少节点的overhead,每个节点会表示一个Key中16bit的内容。但是如果是最朴素的trie的设计的话,使用16bit的partial key会造成的结果就是一个节点比较大,而且空间的利用率很低。这里核心的问题是一个可以表示65536个partial key的节点实际使用的时候,里面被真正使用的是比较小的一部分,优化的基本思路就是如果只在需要的时候才去分配这些空间,而不是一开始就将65536个partial key的空间全部分配。之前的ART的设计就是使用8bit的partial key,将节点的大小分为几种,根据节点里面实际保存数据数量选择合适大小的节点。这里的思路则有些不同,
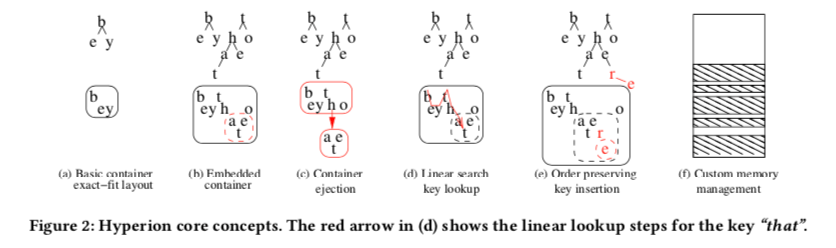
- Hyperion这里用Container来保存16bit的partial key的数据。Hyperion将其16bit的partial key分为2个8bit的部分保存,如下图a表示的那样,be和by中b只会被保存一次,在需要添加更多的Key的时候,超出了这个Container的表示范围的话,需要进行Container ejection的操作。为了节省内存,Contrainer中的数据都是一个个以非固定偏移的范围保存的,这样的坏处就是性能上面可能差一点。一个Container中查询的方式也是线性搜索的方式。同样,为了节省内存,每次Container大小的增长是以32 byte为粒度。
-
Container的结构如下图所示,其中4byte的头部包含了好几个部分的内容,第一个19bit保存了Container大小的信息,接下来的8bit保存了没有使用的空间的大小。后面是3bit的jump table和2bit的split deply信息。其用途在后面说明。16bit 的partial key分为两个部分,保存在一个Container里面,两个8bit部分的节点分别称之为“T-Node” (top) 和 “S-Node” (sub),

-
T-Node和S-Node的结构中,两者的最前面的2个bit表示node type:01表示inner node类型,10和11表示leaf node类型,00表示invalid node。leaf node有分为两个类型,10表示没有带有value,11表示带有value。invalid node表示Contrainer中多分配的空间,目前没有使用。一个T-Node下面的S-Node总是和这个T-Node“挨着”的。T-Node的k bit为0,而S-Nod的k bit为1。下图中,16个bit中8个bit表示元数据,而剩下的8bit表示数据,处理前面说明的3个bit之外,T-Node接下来是3个 d bit,js、jt各一个bit,S-Node则最后面为2bit的c。用途在后面说明。
-
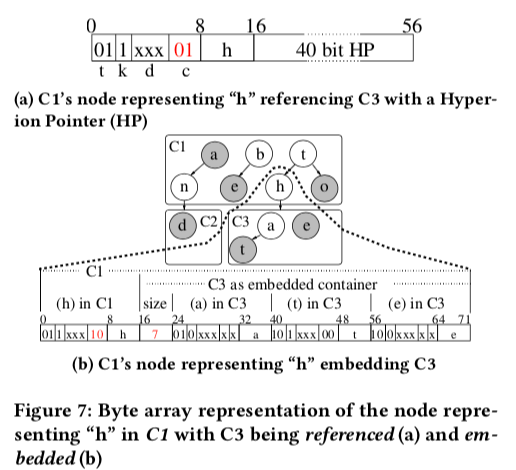
Child Containers,S-Node的2个 c bit,00表示这个S-Node没有Child Container,01表示有一个使用Hyperion Pointer (HPs)指针指向的Child Container。除了使用指针间接地引用一个Child Container,这里还使用10表示embedded container,这个embedded container直接保存在父Container中。Embedded container的Header只会保存其大小的信息。由于S-Node的最大的大小为256bit,这里使用Embedded container也会受限于这个大小。在必要的时候,保存在父Contrainer中的Embedded container需要进行逐出的操作。在进行这个操作的时候,需要将Embedded container中的数据转移到新分配的Contrainer中。父Contrainer中的元数据要进行修改,部分数据要进行必要的移动。
-
第四种情况就是c bits为11,表示path-compressed node (PC)。很多时候trie的key有相同的部分数据。PC Node就用于suffix压缩保存,这个策略在其它的一些trie结构中也被使用。PC Node有一个byte的Heder,其中7bit表示其大小信息,1bit表示有一个value属于这个节点。这样的话,PC Node的大小最多为127个char。当存在一个value的时候,value保存在这个header的后面,partial suffix key继续追加在后面保存。
在这样的设计下面,查询操作在每个Contrainer中,根据T-Node和S-Node找到对应的位置,在需要的时候继续查询Child Contrainer。由于Hyperion这里使用order-preserving添加方式,添加的时候可能需要进行数据的移动操作。Delete和Insert操作类型,操作相反而已。update操作在需要追加value的时候需要数据移动。
0x12 内存管理
一般在64bit的平台上面,指针式8byte的大小。在一些图数据库上面,为了节约内存使用,将一些数据的对象分配为一整个大数组(or称之为对象池,比如为65536个)。这样的话,分配一个对象只要记录这个大数组的地址和在这个数组中的偏移信息就可以了。这个数据的信息可以多个对象公用,这样实际上很多时候只要用2byte的空间就可以找到对应的对象了。节约了不少内存。这里也是使用类型的思路。Hypersion中内存管理的结构大致如下,
-
最上面的是Superbin,最多有64个。 SB0 处理全部大于2,016byte的分配请求。 SBi 最终用于分配32 · i 大小的segment。不过中间要经过Metabin、Bin和Chunk几个层级。Chunk就是用于保存container的内存单元,
Superbin SB0 handles all requests larger than 2,016 bytes; and each superbin SBi , i ∈ [1, 63], provides segments of 32 · i bytes. Every superbin has up to 2^14 metabins, every metabin up to 256 bins, and every bin 4,096 chunks.A chunk Ci is the memory segment used to store a trie container. So, every superbin addresses up to 2^34 chunks.
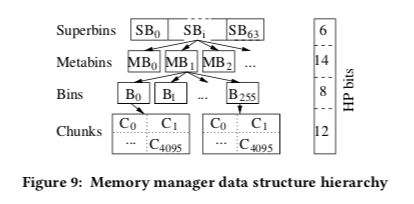
这样的话,分配Contrainer使用内存的时候,使用5byte大小的Hyperion Pointers (HPs)即可。为了处理大于2016bit的分配请求,这里引入了Extended Bins,在SB0中管理。使用16bit的extended Hyperion Pointers (eHP)保存,16byte中包含一个8byte的指针,4byte的requested size信息,2byte的over0allocated 信息,剩下的2byte保存housekeeping flags信息。Chained Extended Bins (CEB)是同时分配和释放的。Hypersion中另外使用的一些提高内存使用率和性能的方式,
-
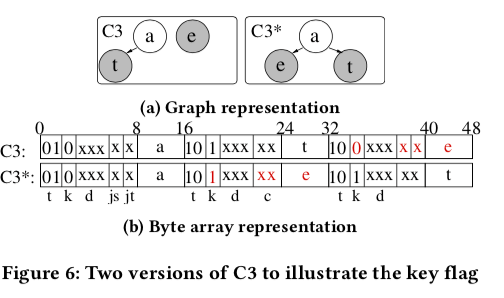
Delta Encoding (d),前面节点中d bit的用途。由于∆(a,e)=101−97=4,所以在S3中的d bit中直接保存4即可。而∆(e,t)=116-101=15,15大于了d bit的表示分为,所以在C3*中,这个还是保存在了后面。
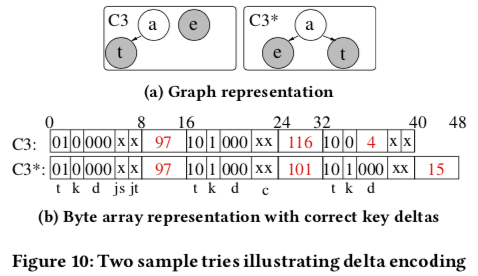
-
Jump Successor (js),这里就是如何从一个T-Node快速定位Contrainer中的下一个T-Node。如果这个Bit被设置,这个T-Node后面会追加一个 jump reference,
This reference is the offset to the successor sibling in bytes. As the reference is limited to 16 bits, the maximum jump distance is 65,536 bytes and the maximum S-Node size is 256 bytes. -
Jump Tables (jt),T-Node jump table通过一个15个unsigned short类型的数据保存到一个T-Node的S-Node信息。同时为了适应delta encoding的方式,对于这个T-Node jump table中15个项,ei , i ∈ {0, 1, …, 14}, 记录16 · (i + 1)的8-bit partial key。这样的编码方式可以避免将8bit的partial key保存在这个table里面。emmm,这里得在看看
The mapping makes it unnecessary to store the destination key along with the jump offset and the jump table entry for a key ki can be determined by a bit shift JT (ki ) = (ki ≫ 4) − 1. Nevertheless, additional destination points must be created if keys are missing.container jump table则用于快速定位T-Node。Container header中的3个j bit,如果每个定位7个为一组的T-Nodes的话,可以最多49个T-Node。这个table中的每一项是32bit的一个数,包含8bit的key信息和24bit的offset信息。这里两个table的信息其实就类似于Contrainer中的一个二级索引。
-
Splitting Containers和Key Pre-processing,TODO。
0x13 评估
这里的具体信息可以参看[2]。Paper中的测试结果,Hypersion表示出来的内存消耗的数据还是很厉害的。
Automatically Indexing Millions of Databases in Microsoft Azure SQL Database
0x10 引言
这篇Paper则不是设计一种新型的索引数据结构,而是如何自动为数据推荐、建立索引。这里的面向的环境是大型的云计算的环境,运行着百万计的数据库。这么大数量的数据库实例的一个就会有很多索引建立不合理的数据表,同时也给自动话的索引推荐、建立带来了很大的难度。这里的系统要实现这样的一些任务,1. 表明数据的workload的特征,2. 在不影响数据运行的情况下分析数据,3. 实现索引更新,4. 保证这些操作不会影响到数据库实例的性能,4. 在workload改变的时候,系统也要做出新的变化。
0x11 基本思路
在将自动化的索引建立应用到大规模的云环境之前,SQL Server本事也有一些自动话的索引推荐工具, (a) Missing Indexes [34]; 和 (b) Database Engine Tuning Advisor (DTA),这两个系统只能应用到单机上面。这里的系统实现的时候,也会用带这两个工具。auto-indexing service的基本架构如下。在一个region内,会有一个or多个的数据库集群分布在这个区域的一个or多个的数据中心内,一个区域内会有一个auto-indexing service。1. 这里核心的一个组件是Control Plane,作为整个系统的控制面板,处理自动化索引优化的整个流程,协调不同的组成完成任务。Control Plane作为核心组件会通过副本的方式实现高可用。2. 两个索引推荐的工具,这个来自以前为SQL Server设计的工具Missing Indexes和Database Engine Tuning Advisor (DTA),3. Validator,用于验证添加 or 删除索引的实际效果。
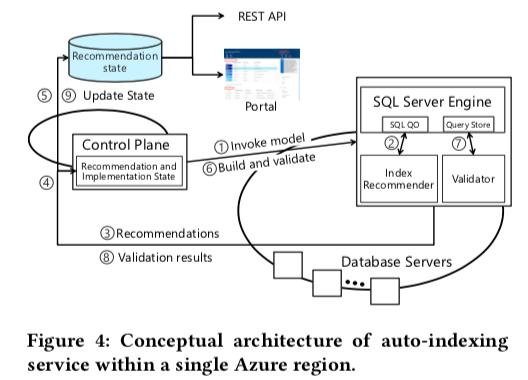
Control Plane编排自动索引服务的各个组件,每个数据库实例独立地处理自动化索引的任务。Control Plane实际上包含很多的子功能,通过引入微服务的方式将Control Plane拆分为多个独立的微服务。主要有这样的一些服务,1. 触发数据分析,并产生索引推荐,2. 应用推荐,3. 验证推荐的实际效果,4. 在应用之后检测异常情况,在必要的时候采取纠正措施。根据自动化索引进行的步骤,分为这样的一些状态,1. Active,索引准备创建 or 删除,2. Expired,推荐已经过期了,3. Implementing,应用中,4. Validating,验证中,5. Success,成功,5. Reverting,回滚中,6. Reverted,已经回滚,7. Retry,重试,8. Error,失败了。索引推荐的产生这里实际上没有实现新的组件,而是利用了之前为SQL Server设计的两个工具,
- Missing Indexes (MI)是在SQL Server 2005的时候就引入的一个功能,在查询优化的时候。数据库将缺失的可能提高性能的索引信息通过dynamic management views (DMVs) or execution plan XML暴露出来。MI的一个优化是它是一个很轻量级的工具,缺点是比较简单,不能对复杂的查询提出优化。
-
Database Engine Tuning Advisor (DTA),DTA是一个更复杂的工具。DTA用于一个Workload作为输入,产生为这个Worload优化的设计。这两个系统的具体内容在其它的论文里面。
在实际应用的时候,这里为减少DTA对系统造成的影响做了一些其它的优化。DTA工作的时候需要连接数据访问元数据、建立和读取一些统计信息,以及一些调用query optimizer的操作。为了减少对实际数据库实例的影响,这里是在一个数据库的副本中进行操作。负载的信息来源于SQL Server的另外一个功能Query Store。经过这样的一些和其它的一些操作,DTA就类似于一个服务的存在。除了添加索引的建议外,还会有删除索引的建议,这里的难度有这样一些,1. 偶发操作需要用的索引,2. 在SQL语句中使用hint使用的索引,3. 重复索引。这些case的存在给实际的索引删除带来不少的困难。这里通过更详尽的分析索引使用情况,不去处理强制使用的索引,分析更长时间内的使用情况,比如60天来缓解这些问题。在实际应用的时候,会选择负载的低峰事情进行操作。验证的时候使用实际数据的一个副本来进行验证操作,在自动优化之后的实例上面运行workload。
emmmm,感觉读了…..¯_(ツ)_/¯。主要就是一个中心的Control Plane利用SQL Server之前的存在的一些工具进行自动化索引优化的操作,并执行验证等。
0x13 评估
这里的具体信息可以参看[2]。这种在实际系统中使用的大规模系统的评估信息是很有价值的。
参考
- Hyperion: Building the Largest In-memory Search Tree, SIGMOD ‘19.
- Designing Distributed Tree-based Index Structures for Fast RDMA-capable Networks, SIGMOD ‘19.
- Automatically Indexing Millions of Databases in Microsoft Azure SQL Database, SIGMOD ‘19.
