Socrates: The New SQL Server in the Cloud
0x00 引言
这篇Paper是将发表在SIGMOD ‘19上面的关于微软开发的一个New SQL Server的论文(个人感觉这篇Paper题目中的New SQL Server双关,表示是一个新的SQL Server,也可以表示一个New SQL的Server)。在Amazon提出了Aurora的架构之后,类似Aurora架构的数据库出现了不少。这篇Paper总体上是一个类似Aurora的架构,不过也存在存在很多不同的地方。 Socrates本质上是构建在SQL Server之上New SQL。所以SQL Server的一些功能也会影响到Socrates的设计。Paper中先总结了对于Socrates来说比较重要的几个功能,1. Page Version Store,快照隔离级别实现的基础之一,2. Accelerated Database Recovery,优化undo节点的一些设计,3. Resilient Buffer Pool拓展,利用SSD作为BufferPool功能在Scrates上面的拓展,4. 远程IO协议。以及5. 快照备份/恢复和6. IO栈虚拟化等功能。
0x02 基本架构
Socrates是一个存储计算分离、Shared-disk的架构,构建在SQL Server之上。在这样的基本架构之上,将Log分开处理,以及将一些功能下推到存储层等来优化性能。总结说,Scorates的设计原则和目标分为这样的几点,
a) separation of Compute and Storage,
b) tiered and scaled-out storage,
c) bounded operations,
d) separation of Log from Compute and Storage,
e) opportunities to move functionality into the storage tier, and
f) reuse of existing components.
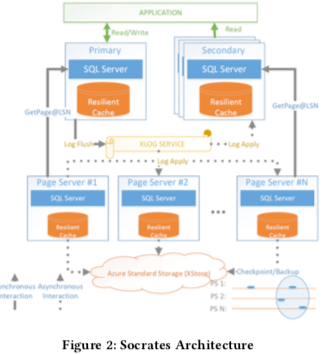
总体上,Scorates分为四层,基本的架构如下图所示,
- 第一层为计算节点,应用直接和计算节点交互。结算节点为多个,其中一个为主节点,另外的为从节点。主接口可以处理读写请求,而从节点只处理读请求。主节点故障之后会选择一个从节点为新的主节点。所有的计算节点会在内存和本地的SSD中缓存数据Pages。这里提供的是和SQL Server兼容的接口,这里估计就是从SQL Sever改来的。
- 第二层为XLOG服务,这一层实现分离日志的设计思想。这里的设计和Aurora的存在一些差别。XLOG实现了低的提交延迟和良好的可拓展能力。由于只有当个主节点对日志进行写入,更容易实现写日志的低延迟和高吞吐。其它的节点会异步地消费这些日志来更新数据。
- 第三层为存储层,通过使用Pages Servers实现。每个Page Server包含数据库的一部分的数据。Page Server在Scorates中扮演两个重要的角色,第一个是给计算节点提供数据Page,计算解决通过请求Page Server获取数据Page,Page Server这里可以实现bulk loading, index creation, DB reorgs, deep page repair, 和 table scans等诸多的功能,这里就是将一些计算节点的功能下放到了Page Server。另外的一个角色是做Checkp和备份数据到XStore。同样地,Page Sever也是将数据保存到内存中,也可以保存到本地的SSD中,这里估计也是从SQL Server改来的。
- 第四层为Azure Storage Service,即XStore。Azure Storage Service是一个在Scorates之外的组件,复杂存储最终的数据库数据。
这里第一、三层就是无状态的,也就是说它们在任何时候的故障都不会影响到数据。数据真正保存早XLOG和XStore中。XLOG是一个专门为Scorates设计的一个服务,而XStore利用来Azure之前就存在的存储系统。
0x03 XLOG Service & Compute Node
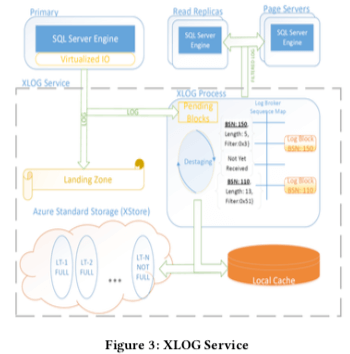
XLOG的内部组成大致如下图所示,Primary计算节点直接写入日志快到 landing zone (LZ) 中。这里是一个高性能的存储系统,目前使用Azure Premium Storage service (XIO)来实现,这里的写入的数据会保存三份。LZ是一个高性能的存储系统,但是存储的大小不会很大,它被组织为一个环形缓冲区,日志格式就使用原来SQL Server的日志格式,避免重复造轮子。
-
另外Primary节点也会将日志写入特定的XLOG,这个XLOG会将日志传播到其它的计算节点个Page Serverrs。写LZ的时候是同步写,而写这个XLOG的时候会是一个异步操作,前一个使用一个可靠的方式,而后一个使用的是一种不完全可靠的方式,且Primary节点写LZ和XLOG是并行进行的。
-
并行写可能带来的一个效果就是从节点会比LZ先拥有最新的数据,这样的话可能在一些故障的时候导致一些不一致的问题。为了避免这个问题,XLOG只会将已经持久化到LZ上面的数据才传播到其它的从节点和Page Servers,
To this end, the Primary writes all log blocks first into the “pending area” of the XLOG process. Furthermore, the Primary informs XLOG of all hardened log blocks. Once a block is hardened, XLOG moves it from the “pending area” to the LogBroker for dissemination,在日志块到的LogBroker的时候,XLOG也会将这个日志块持久化保存到本地的SSD上,这里称之为LT。这些数据在Socrates中设置为保存30天。可以用户数据恢复到过去的时间点 or 拥有灾难恢复。LZ和LT组织的方式要特别注意,如果LT中的数据还没有持久化保存(destage,离台,磁盘存储),且LZ中没有了存储空间,这个时候系统就不能处理有数据更新的事务。
-
LOG的消费者为其它的从节点和Page Servers。它们使用pull的方式拉去日志数据。这种模式的一个优点是LogBroker不需要追踪从节点和Page Sevrer的信息,这些节点就更容易拓展到很大的一个集群。内存中的Blcok保存到一个Seqence Map中,如果这个Map里面没有发现,回去本地的SSD Cache 里面查找。在本地缓存失效的时候回去LZ中查找,这里没有发现则去LT中查找。前两者可以看作是数据缓存,后两者是持久化保存的地方。
0x04 Compute Nodes
计算节点的Primary节点主要工作就是处理读写事务,并产生日志。这里的Primary节点有一些和一般的主从集群中的Primary几点不同的地方,一些存储层的操作,如checkpoint,备份及恢复操作,Page处理被代理给Page Server和下层的存储层来处理。而Priamry使用virtualized filesystem机制将日志写入LZ,同时在IO虚拟化层上面使用RBPEX缓存机制。所以这些节点仅仅只会缓存热点的数据而不会保存数据。这样就需要一种机制来处理计算节点回去数据Page是机制,
-
Scorates使用GetPage@LSN机制来获取数据页。相关函数原型:
getPage(pageId, LSN)。pageId是对应Page唯一的ID,LSN是 log sequence number。这个函数会返回至少应用到这个LSN对应日志的这个数据Page的版本。 -
假设这样一个例子,Priamry节点在本地buffer中更新数据页X,之后由于内存or存储空间等的原因X从buffer pool和RBPEX中都驱逐,在驱逐之前,对X更新操作的日志肯定已经持久化保存了。之后Primary重新读取X。这种情况,保存Primary节点看到的数据页的版本对于保证数据一致性是必须的,所以这里LSN用于保证X被驱逐的时候已经应用的更新操作都被应用重新返回的Page上面。
-
这里还有另外一个问题要处理,Primary难以保存了所以数据页驱逐时候应用到的LSN。Scorates将这些最高LSN保存到一个hash map里面,每个hash map的bucket记录一个最高值,
... the Primary builds a hash map (on pageId) which stores in each bucket the highest LSN for every page evicted from the Primary keyed by pageId. Given that Page X was evicted at some point from the Primary, this mechanism will guarantee to give an X-LSN value that is at least as large as the largest LSN for Page X and is, thus, safe.
Scorates和其它存储计算分离架构一样,这里的从计算节点不需要保存所有的数据。它从本地的buffer pool中驱逐一个数据页时,可以直接删除即可,不需要持久化保存。从计算节点会拉取Primary节点的日志,重放日志的时候不需要将所有的日志重放,只需要重放保存在本地buffer pool中的数据页相关的日志即可,保持自己本地buffer pool数据更新。这里提到了两个要处理的race condition,
-
检查一个数据页是否存在本地的buffer pool和一个正在进行中的GetPage@LSN请求之间可能的race condition。这里的解决办法是在应用日志之前注册这个GetPage@LSN请求。应用相关日志的时候要等到这个page被load完成。
-
另外一个race condition来自在B-tree中操作的时候,读取B-tree内部一个节点在本地buffer pool中,但是其子节点不在,获取这个page的时候使用GetPage@LSN请求,但是这个子节点可能”来自未来”,考虑这样一种情况,
• The Secondary reads B-tree Node P with LSN 23. (The Secondary has applied log until LSN 23.) • The next Node C, a child of P, is not cached. The Secondary issues a getPage(C, 23) request. • The Page Server returns Page C with LSN 25, following the protocol described in Section 4.4.这样的一个节点就是可能导致数据不一致的问题。这里的解决办法是探测到这样一个不一致之后,会暂停等到日志应用现场将相关数据更新。
0x05 Page Servers & XStore
Page Server在Socrates中的作用有这样的几个,1. 保存数据库一部分的数据,用应用Primary节点产生的日志更新这部分的数据;2. 处理GetPage@LSN请求;3. 执行分布式的checkpoint和进行备份操作。Page Server和从计算节点一样拉去数据并应用,这里和从计算节点不同的是,从计算可能需要感受到日志中的任何改动,但是Page Server只需要知道自己的那一部分即可,所以在XLOG的这一步,XLOG之后将相关的日志发动给某个Page Sever,节省发送日志的量。
- 处理GetPage@LSN请求时,需要应用对应Page的日志不低于LSN。所有这里有多个Page Server,这样的话热点数据在Page Server这一层就比较分散,而且最热点的数据一般在计算节点这一层就被缓存了。所以Page Server这里所有的Page都使用RBPEX机制来缓存。
- Page Server的checkpoint操作和备份操作都要和XStore交互来处理。
XStore使用的就是Windows Azure Storage。相比一其它部分而言,XStore处理的速度可能较满,所以Scorates在前面用了几层的Cache机制。在执行checkpoint操作时,Page Server讲脏页刷到XStore中即可,备份操作利用了XStore的snapshot的功能。用户执行恢复到获取一个时间点的操作时,需要处理snapshot和日志两个部分,
When a user requests a Point-In-Time-Restore operation (PITR), the restore workflow identifies
(i) the complete set of snapshots that have been taken just before the time of the PITR, and
(ii) the log range required to bring this set of snapshots from their time to the requested time.
0x06 评估
这里的详细信息可以参看[1].
参考
- Socrates: The New SQL Server in the Cloud, SIGMOD ‘19.
