X-Engine: An Optimized Storage Engine for Large-scale E-commerce Transaction Processing
0x00 引言
这篇Paper是SIGMOD ‘19上面已经可以下载到的一篇Paper。X-Engine是阿里为其X-DB开发的一个存储引擎,基于LSM-tree,引入了FPGA、NVMe等新型的硬件来优化性能,
... which utilizes a tiered storage architecture with the LSM-tree to leverage hardware acceleration such as FPGA-accelerated compactions, and a suite of optimizations including asynchronous writes in transactions, multi-staged pipelines and incremental cache replacement during compactions.
0x01 基本架构
X-Engine的基本架构是一个围绕找LSM-tree的设计。其基本的部分有这样的几个,
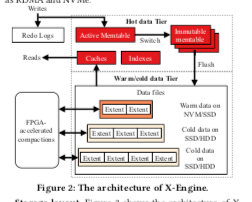
- 存储层,为一个分层的设计。热数据层保存在内存之中,对应到LSM-tree中的memtables。在下面,不同冷热程度的数据可以分别保存到不同的存储介质之中,比如NVMe SSD可以保存Warm数据,而冷数据可以保存到HDD上面。存储层的一个Levle由多个extent组成,一个extent会包含其数据blocks和相关的filters和索引。冷热数据的区分这里使用了机器学习的方法。LSM-tree的存储系统中,由于其Compaction会带来一些性能上面的不稳定等现象,这里X-Engine引入了一个FPGA来做Compaction,解放CPU的处理能力。X-Engine的并发控制机制还是基于MVCC,依赖于redo logs, metasnapshots, 和 indexes这几个部分。每个meta snapshot包含meta索引,这个索引记录这一个快照中所有的memtables,所有的extents。
- The read path。Read Path基本上是LSM-tree中读取的流程。这里还使用了meta索引和内存中的一个缓存来提高查询的速度。使用一种incremental cache缓存替换算法来减少在Compaction的时候不必要的数据驱逐。
- The write path,在基本的LSM-tree写入流程的基础之上, 通过multi-staged pipeline来提高吞吐,减少线程不必要的停顿。另外将数据写入从事务处理中分离开来优化性能,这个思路也被其它的一些MySQL的版本使用。
- Flush and compaction,这里X-Engine使用了不少的优化方式。
总结而言,X-Engine中使用了下列的一些优化方式,

X-Engine是一个自持事务的存储引起,通过MVCC和2PL实现RC和SI的事务隔离基本。在X-Engine中,同一个记录的不同版本分开保存,使用一个递增的Version ID标识。这个Version和LSN紧密相关,一个新到达的事务使用LSN表明它可以看到的Snapshot。一个事务只会看到Version比其LSN小的数据记录。写入冲突使用行锁来处理。
The read path
Read Path中主要讨论了4点设计,
-
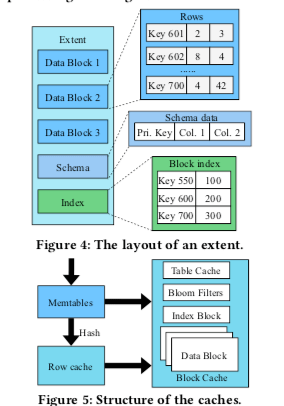
Extent,一个Extent由一组联系的书数据Block和其索引已经其它的一些元数据组成。X-Engine中配置了Extent的大小为2MB。如下图所示,X-Engine在Extent的元数据中保存了一个带版本的schema数据,用于加速DDL的操作,schema的修改早数据库中是一个很麻烦的一个操作,在很多时候也很耗时。在这里,在数据库表中添加一列的时候,就不需要对已经存在的Extent进行任何的改动,新的Extent会保存新的schema的信息,在查询的时候如果读取的Extent里面的schema信息与目前的不符合,则添加的列就使用一个默认的值。
-
点查询在X-Engine面向的环境中是一个很常见的操作。在下面的图中,X-Engine使用了Row Cache和Block Cache两层的Cache。Row Cache这里使用LRU的方式,只会缓存一条记录的最新的版本,因为最新版本的数据最有可能被访问。缓存不论这条记录来自于LSM-tree的那一个Level。Block Cache以Data Block为单位缓存,
-
Multi-version Metadata Index,Metadata Index这里类似于RocksDB中的Manifest数据的作用。X-Engine每次修改这些信息都是使用一个新版本的Metadata Index,而不是去修改原来的,这里就是一个Copy-on-Write的操作。这样做的一个好处就是事务可以以只读的方式访问任意版本的数据,而且不需要使用锁之类的手段。对于过期的这类数据,X-Engine会对其进行GC处理。
-
Incremental cache replacement,这里的问题来源于LSM-tree在Compaction的时候可能导致的大量的数据被从缓存中驱逐,从而降低了系统的性能。为了解决这个问题,X-Engine不会驱逐所有的Compacted的Extent,而是在Compaction的时候,用合并了的新的Data Block代替缓存中对应的旧的Data Block。
The write path
X-Engine在Paper提到它是一个为写入优化的系统。这里X-Engine在写入优化也应用来很多丰富。 Write Path这里提到了4点的优化策略,
-
Multi-version memtable。Memtable实现使用了一个LockFree的SkipList,X-Engine使用一个多版本的设计来优化热点key的问题。在这里的SkipList,更新一个Key的数据会使得这个Key对应的数据产生一个新的版本。多数情况下,使用的是最新版本的数据,有些情况下需要扫描这些数据。多版本的数据组织为一个list,较新的会放到这个list靠前的位置,减少不必要的list遍历。
-
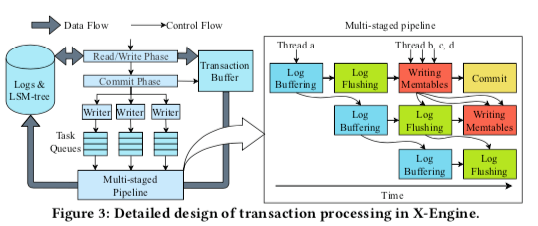
Asynchronous writes in transactions。InnoDB中最初使用的是一个事务一个线程处理到底的方式,这样的处理方式在数据最终写入到磁盘上面的过程中,会造成这个线程有较长时间的停顿不能处理其它请求。一种在其它一些优化版本采用了的方式是将处理事务的线程和写入线程分开,处理事务的线程在将写入的工作交给写入线程之后就可以处理其它的请求,在写入线程写入完成之后,这个事物就可以返回给客户端。在X-Engine中,采用了一种更新深度优化的策略。如下图所示,写入任务会被分发到多个的T无锁的ask Queues上面,在任务添加到Queue上面的时候,大部分的线程就可以返回了,其中的一个线程会继续处理这些任务,
... The optimal number of queues is bounded by the I/O bandwidth available in the machine, and contentions among multiple threads over the head of each lock-free queue. We find that eight threads per queue can saturate the I/O bandwidth in a 32-core machine这样带来的一个好处就是可以将Task Queue上面的写入请求批量处理,提高吞吐。
-
Multi-staged pipeline,Task Queues下面是一个多staged的pipeline。写入路径是一个多步的操作,涉及到多个操作。这里就将这个pipeline分割为多个stage,如下图所示。四个stage操作如下:1. log buffering,从transaction buffer中收集每个写入请求的WAL到log buffer,并计算CRC32的校验值,2. log flushing,将数据刷入磁盘,写入会地址LSN。3. 多个线程并行地将数据修改应用到当前的actove memtable,3. 提高事务,释放其占用的一些资源,如锁等。每个阶段操作不同,多计算能力要求也不同,X-Engine会分配调整每个阶段操作线程的数量。
0x02 Flush and Compaction
Flush and Compaction这里是X-Engine重点优化的一个部分,这里最大的特点之一是引入了FPFA这样的异构硬件来解决LSM-tree Compaction时候影响系统整体性能的问题。优化都做得很细致,
-
Fast flush of warm extents in Level0,Level0保存在内存之中,这部分的数据操作的频率相对而言也比较高。这里使用Level0内部Compaction的方式来减少Level0数据都被刷入Level1的次数。这样的另外一个好处就是可以将warm extents的数据更大可能地保存在内存中。
-
Accelerating compactions,LSM-tree Compaction操作的时候会显著地降低系统整体的性能。为了优化这个问题,这里使用了多种的优化策略,
- data reuse,X-Engine选择将Extent设置为一个比较小的值,2MB,Extent被继续划分为16KB的Data Blocks。这样Compaction操作的时候,Extent有更大的可能不会存在数据重叠,也就不需要对这个Extent进行实际的数据操作,Compaction只需要改送meta index即可。
- asynchronous I/O,一个Compaction操作有基本的三步,1. 从存储设备上面取回两个Extent,2. 在内存中合并,3. 将合并之后的数据写入磁盘。第1、3步都会涉及到磁盘操作,这里都使用异步IO来处理。
- FPGA offloading,Compaction操作在做了如上的一些优化之后,其会占用的CPU的资源还是比较高。FPGA的作用就腾出CPU的计算能力,处理事务请求。这里具体地做法在这篇paper中没有说明,这里应该也会是一个比较大的内容。
-
Scheduling compactions,这里精细地将Compaction划为多种,1. intra-Level0,Level0内部的Compaction,如前文所言,2. minor compactions,相邻两个Level数据的合并,不包括最大的Level,3. major compactions,合并最大Level和其它Level的数据,4. self-major compactions,最大的Level自己的Compaction操作,用于减少碎片和删除已经删除的数据。Compaction操作由一个Lelve中数据的大小 or Extent数量达到一个阈值触发。被触发的Compaction任务会被推荐到一个优先队列中。决定每个Compaction任务优先级的规则可以配置,可能根据数据上面运行的不同的应用而改变。在一个删除操作比较多的数据库应用中,X-Engine的配置如下,
(1) Compactions for deletions. (2) Intra-Level0 compactions. (3) Minor compaction. (4) Major compaction. (5) Self-major compactions.
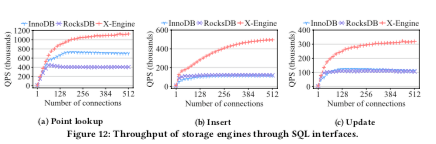
0x03 评估
这里的具体信息可以参看[1],
参考
- X-Engine: An Optimized Storage Engine for Large-scale E-commerce Transaction Processing, SIGMOD ‘19
