SILK: Preventing Latency Spikes in Log-Structured Merge Key-Value Stores
0x00 引言
以LSM-tree结构为基础的Key-Value存储中,一个很麻烦的问题就是延迟尖刺的问题。这个问题的出现和LSM-tree Compaction和Memtable Flush密切相关。即使是想RocksDB这样被广泛使用的Key-Value Store,里面关于这个参数的调整也是一个比较麻烦的问题。这篇Paper提出解决这个问题的节点思路:1. 在系统负载低的时候可以考虑给KVS内部的操作更多的IO带宽,2. Flush和Compaction操作的时候根据不同的Level划分优先级,3. 可抢占的Compaction,
... We use both a production workload at Nutanix and synthetic benchmarks to demonstrate that SILK achieves up to two orders of magnitude lower 99th percentile latencies than RocksDB and TRIAD, without any significant negative effects on other performance metrics.
0x01 延迟尖刺现象
这里将LSM-tree中内存中的Memtable称之为Cm,磁盘上面以Level形式组织的称之为Cdisk,日志部分称之为Clog。通过一个修改版本的RocksDB,其取出来Flush和Compaction的操作,这种情况下延迟尖刺现象变得很少。Paper中分析了造成延迟尖刺的两个主要原因,
- 在一个时间,L0的容量达到阈值之后。几个Compaction操作在L0、L1和L2中进行,但是只会有一个L0到L1的操作。在IO带宽平均分配到这些Compaction操作的时候,L0到L1的操作就满下来了。造成了L0的容量维持在一个高位,从而导致写入延迟的尖刺现象。
- 虽然L0的容量没有达到一个阈值,但是其中的Flush操作可能遇到异常的长时间操作。这里分析出主要原因是系统中存储多个Compaction操作,更大的Level的操作抢占了IO带宽。
除了RocsDB之外,这里还分析了TRIAD和PebblesDB两个KVS的延迟尖刺现象,分析都存在这样的问题。这里主要总结出几点:1. 写入延迟尖刺的原因主要是Cm被填满。可能磁盘上面的第一层满了,导致Mentable不能即使Flush到磁盘。或者是有同时多个Compaction操作,抢占了IO带宽。2. 一些优化方式,比如限制内部操作使用的带宽不能实际解决问题,这是将问题出现的时间延后了一些。运行时间长了之后还是会出现。3. 其它的一些“避开“Compaction的优化实际上都不是真正解决问题。
0x02 基本思路
这篇Paper解决这些问题的基本思路如下,
- Opportunistically allocating I/O bandwidth,使用另外的一个线程,来监控系统的负载情况。假如系统可以提供的带宽是T,客户端使用了的带宽是C,则系统会将剩下的带宽I = T −C−ε分配给内部操作,其中ε是一个留下的buffer,避免用得“太紧”。通过使用一个rate limiter来限制IO带宽的使用。为了避免频繁调整带宽限制,这里只有在新的测量值和旧的值相差大于一个阈值的时候才会调整。
- Prioritizing internal operations。这里的思路在其它的一些KVS也出现过。基本思路就是根据不同类型的IO来设置一个优先级。很显然Memtable Flush到磁盘的优先级应该是最高的,必须保证内存中有足够的空间给新添加的数据,这里会只用一个指定的线程池来执行操作。其次是L0到L1,L0空间不够的时候也会阻塞Flush的操作,导致写入延迟尖刺的线程。L0到L1的Compaction操作不会使用一个特定的线程池,但是存在多个Compaction的操作时候,可以抢占更高Level的Compaction操作。虽然这里也要服从于动态IO带宽的调整,但是不会被暂停,在必要的时候会将这里的任务已入更高的优先级,保持其运行。
- Preempting compactions,L1级更高的Level的Compaction操作的优先级更低。这些操作进行的时候可以被更高优先级的操作抢占。在这些优先级高的操作完成之后在继续运行。
0x03 评估
这里的具体信息可以参看[1].
ElasticBF: Elastic Bloom Filter with Hotness Awareness for Boosting Read Performance in Large Key-Value Stores
0x10 引言
这篇Paper是优化LSM-tree Bloom Filter的一个思路。和前面的Monkey优化的思路是一样的,但是具体的做法不一样。在很多的负载场景中,数据访问的比例分布是不均匀的,这样所有的SST文件使用相同的Bloom Filter设置的话不一定就是最好的方式。一个思路就是频繁访问的数据可以使用FPR更低的Bloom Filter设置,对于访问频率比较低的部分的数据,使用较高FPR的Bloom Filter设置,能够取得很好的性能表现。Monky的思路就是这样的,这里的ElasticBF则是将Bloom Filter设置为多个,每个称之为Filter Unit,对于频繁访问的数据可以使用更多的Filter Unit,访问较少的数据使用少一些的Filter Unit,
... We build ElasticBF atop of LevelDB, RocksDB, and PebblesDB, and our experimental results show that ElasticBF increases the read throughput of the above KV stores to 2.34×, 2.35×, and 2.58×, respectively, while keeps almost the same write and range query performance.
0x11 基本方式
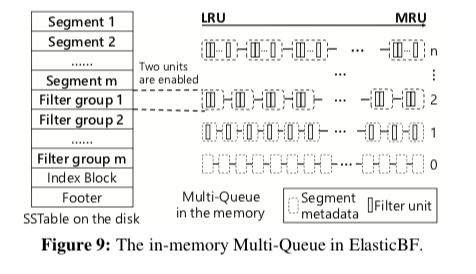
这里基本的思路就如下图所示,思路是很简单的。在此的基础之上,考虑到一个SST文件中不同的的Data Block访问的频率也不同,这里可以将SST文件划分为若干个Segment,Filter Group为每个Segment设置。所有的Bloom Filter都会保存到SST文件中,在读取的时候,固定数量的Bloom Filter会被读取。
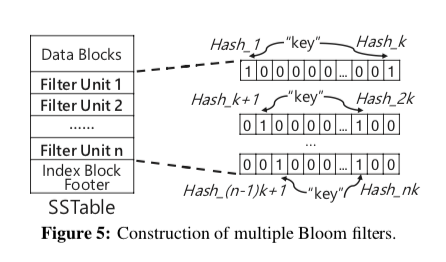
为了测量每个Segment的热度,这里使用了基于访问时间的方法。系统维护一个currentTime,每个访问的时候递增这个值。同时设置被访问Segment的lastAccessedTime,同时这里会有一个expiredTime,等于lastAccessedTime + lifeTime。标记一个Segment访问信息是否过时。使用这些信息标记热度。emmmm,感觉Paper中这里的设计挺牵强的,不如TinyLFU中机遇Bloom Filter + Count Sketch,加上定期衰减的机制。这里在Compaction操作的时候,这些信息会被继承到合并之后的SST文件中。具体在内存中保持多少数量的Bloom Filter基于下面的公式, \(E[ExtraIO] = \sum_{i=1}^{M}f_i \cdot r_i\) 其中M表示Segment的总数,fi表示每个Segemnt的访问频率,ri表示FPR。这里的目的就是使这个值最小。为了支持使用Filter Unit数量的动态调整,这里使用对歌LRU的List来管理Filter Unit。每个相同数量的Filter Unit的Semgent的Filter Group组织为一个list。在需要移除一些Filter Unit的时候,从Q_n到Q_1进行搜索,这里的n代表Filter Unit的数量。在通过这里的过期测量找到过期的项之后,可以减少这个Segment的Filter Unit的数量,所在的List也会改变。
0x12 评估
这里具体的信息可以参看[1].
SolarDB: Towards a Shared-Everything Database on Distributed Log-Structured Storage
0x20 引言
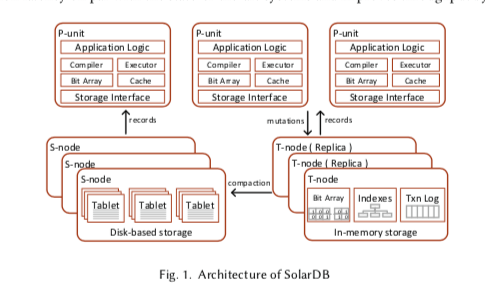
和前面的两篇优化的LSM-tree的Paper不同,这篇是一个完整的数据实现。这里的Distributed Log-Structured Storage是基于之前某里的一个数据库的设计。LSM-tree中,Memtable保存到内存中,其它部分的数据保存到磁盘上面。这里设计了一个两层的架构,将传统LSM-tree中的Memtable保存到一台机器上面,其它部分的数据保存到若干的其它的机器上面,形成一个分布式的两层的架构设计,
In our empirical evaluation on TPC-C, Smallbank and a real-world workload, SolarDB outperforms existing shared-nothing systems by 50x when the transactions requiring distributed commits are close to or more than 5%.
0x21 基本架构
SolarDB将事务处理的过程划分为omputation, validation 和 commit 几个阶段,事务在一个P-unit被初始化,这个P-unit本事不会保存任何数据,保存的一部分信息是用于一些优化的操作,并不是必要的部分。P-unit从T-node 或 S-node获取数据。在事务提交 or abort之前,P-unit会暂存事务产生的数据,在事务提交的时候,会将这些数据发送给T-node来进行验证和提交的操作。T-node在接受到这些数据之后,进行验证和提交的操作。提交完成之后将这些数据写入到内存中,也会在WAL中写入一份,保证数据的持久化。T-node在完成这些操作时候,通知P-unit。S-node只负责保存数据。P-unit可以部署在集群中,也可以部署在集群外,常见的就是和客户端一起部署or和S-node一起部署。在T-node中,内存中的数据同时对于与Primary Key使用一个B-tree索引和一个Hash索引。在集群负载低的时候,会进行一个Compaction的操作,将T-node中的数据转移到S-node中。T-Node这里即作为一个事务管理器,有作为LSM-tree中的Memtable部分,
SolarDB使用结合了OCC和MVCC的并发控制机制。T-Node中的Memtable对于每个数据会保存多个版本,事务开始时候回去的时间read-timestamp作为读取时候哪些版本数据可见的标示。在事务提交的时候,会获取一个commit-timestamp,这个commit-timestamp会比已经存在的commit-timestamp和read-timesamp都要大。在事务提交的时候,会将commit-timestamp保存到记录对应的版本中。另外考虑到这个Memtable Comapction的特点,这里维护了一个last data compaction time (compaction- timestamp),一个Memtable中的数据的commit-timestamps一定会大于compaction-timestamp。在事务处理分为三个主要的阶段,
- Processing,在这里阶段,P-unit中的一个工作线程执行事务逻辑,事务tx在这个事务第一次和T-node交会的时候获取一个read-timestamp,使用rtx表示。然后根据这个rtx,从T-node中获取这个rtx能够读取数据的最新的版本的数据,如果T-node中没有这个数据,在从对应的S-node中获取。在事务处理的时候,写入的数据会先暂时保存到P-unit本地,在提交的时候一次性交给T-node来处理;
- Validating,这一部由T-node来实现。在这一步操作的时候,T-node尝试对这个事务tx写集合中的记录加锁,这里也是一个检索写写冲突的操作。如果加锁成功,则在区决定事务释放提交,如果发生了冲突,则需要abort事务。
- Writing/Committing,在前面加锁成功了之后,在没有故障的情况下,这里的写入操作是一定会成功的。写入数据都是创建一个新的数据版本。记录中会先暂时写入这个事务的ID,在写入完成的时候,获取一个commit-timestamp。之后用这个commit-timestamp替代记录中的事务ID。最好释放记录上面的锁。
事务执行逻辑的正确性在Paper上面有证明。由于Compaction的存在,SolarDB处理的时候需要额外考虑一些东西,
-
使用m0个s0代表目前的Memtable和SSTable。在Data Compaction操作的时候,创建一个新的Memtable m1,合并之后的s1包含了来自s0 or m0一个记录的最新版本。使用一个时间戳tdc表示一个data compaction开始的时间戳。在data compaction开始之后,m1负责处理新的写入请求。这个时候一个时候可以往m0写入数据只有在其Validating操作在data compaction开始之前。T-node会等待这样的事务提交。这个时候,S-node拉取m0,进行merge操作。Merge操作的时候,不会进行覆盖写,而是使用COW的方式。进行中的事务会依旧读取s0,在merge操作完成的时候,通知T-node可以删除m0。
-
Concurrency control相关,1. 如果一个事务validation步骤开始在一个Compaction操作之前,则写入到原来的Memtable中。2. 一个Compaction操作只有在那些些validation在这个Compaction操作开始之前的已经abort or获取了commit-timestamp时间戳的情况下,才可以获取tdc。3. Data Compaction实际操作只有在validation操作在小于tdc的事务结束之后进行。4. 如果一个事务tx的validation阶段开始在一个Compaction操作初始化之后,其validation操作只有在Compaction操作获取了tdc之后进行,
The transaction tx validates against both m0 and m1 but only writes to m1. During validation, tx acquires locks on both m0 and m1 for each record in its write set wx , and verifies that no newer version is created relative to tx ’s read-timestamp. Once passing validation,tx writes its updates into m1,after which tx is allowed to acquire its commit-timestamp.
恢复操作的时候也考虑到Compaction。优化思路后面在看。
0x23 评估
这里的具体信息可以参看[3].
LSM-trie: An LSM-tree-based Ultra-Large Key-Value Store for Small Data
0x30 基本设计
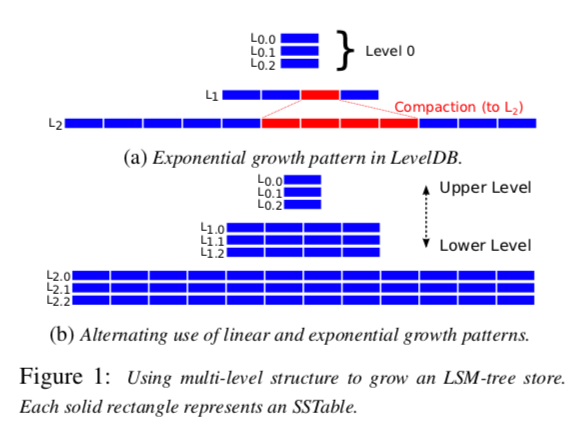
这篇Paper主要为Small Data优化设计,Paper中提出的主要优化思路主要涉及到四五个点。第一个就是Sublevel的设计,本质上还是一种Leveling模式和Tiering模式的结合。在LSM-Tree一个Level的基础之上,每个Level被分为多个的Sublevel。PebbleDB中Leveling模式和Tiering模式结合的方式是将一个Level中的Key Range通过Guard的方式划分开,在不同Guard划分的区间之间,就是Leveling的模式,而一个Guard划分的区间之内就是Tiering的模式。而Dostoevsky中Leveling和Tiering结合的方式是不同的Level使用不同的模式,比如在最大的Level使用Leveling的模式,而在其它的Level使用Tiering的模式。PebbleDB思路更像这个Sublevel的思路。
LSM-trie的另外的基本idea,
-
SSTable-trie,SSTable-trie的思路是LSM-trie称之为LSM-trie的主要原因。这里在选择将数据保存到哪一个SSTable的时候,不是根据Key排序之后的Rank决定的,而是根据Key的一个Hash值决定的,比如SHA-1。这样实际上形成了如下图所示的一种类似前缀树的结构,trie的思路,
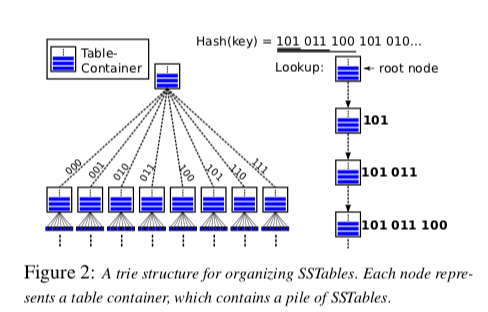
-
Out-of-Core Metadata,LSM-trie强调了为大量的较小的Key-Value设计,特别注意减少元数据的大小。这里Paper中主要涉及到两点,一个是Removing Indices by Using HTables。在HTable中,不同于一般SSTable使用Index Block来作为Data Block的索引,这里一个Data Block更加类似于Hash Table中的Bucket。另外为了避免在HTable引入索引的部分,LSM-trei设计为每个Bucket有固定的大小,每个Block有自己的Bloom Filter。LSM-trie使用来另外的一些思路来解决bucket中数据不均衡的问题;另外一个是Clustering Bloom Filters,基本思路是将Block的Bloom Filter统一保存到一个地方,而不是和Data Block保存到一起。
参考
- SILK: Preventing Latency Spikes in Log-Structured Merge Key-Value Stores, ATC ‘19.
- ElasticBF: Elastic Bloom Filter with Hotness Awareness for Boosting Read Performance in Large Key-Value Stores, ATC ‘19.
- SolarDB: Towards a Shared-Everything Database on Distributed Log-Structured Storage, TOS ‘18.
- LSM-trie: An LSM-tree-based Ultra-Large Key-Value Store for Small Data, ATC ‘15.
