Scalable Database Logging for Multicores
0x00 引言
这篇Paper讨论的也是早多核环境下面的WAL的优化策略。这里的优化的思路主要是消除中心化的日志方式中,为了保存日志顺序写入和Log Buffer中没有空洞而采用的锁。这些锁在多核的情况下面对性能造成了较大的影响。之前的一些系统提出优化策略有非中心化的思路,比如SiloR那样,每个工作线程只会将自己产生的日志写入到自己本地的Log Buffer中,消除这里不同线程之间的差距。这里的思路还是在原来的方式上面优化,
Our efficient implementation of ELEDA is enabled by a highly concurrent data structure, GRASSHOPPER, that eliminates a multicore scalability problem of centralized logging ... Our evaluation showed that ELEDA-based transaction systems improve performance up to 71ˆ, thus showing the applicability of ELEDA.
0x01 基本思路
传统的所有工作线程写入到同一个Log Buffer中的方式,这里将没有空洞日志部分的最大LSN称之为sequentially buffered LSN (SBL)。这里提出的系统称之为Eleda,基本的架构如下图所示,这里的Log Buffer事可以出现空洞的。在Eleda中,主要的角色有这样的一些,1. 数据线程,通过Eleda提供的API获取LSN、拷贝Log到Log Buffer、在Buffer中预留出自己想要的空间。这里并发的Log Buffer的空间分配和日志拷贝不可避免地会产生空洞,如下图表示的一样。2. Eleda工作线程。在事务提交的时候,它必须等到这个事务所有的日志都已经持久化。为了持久化日志,必须先知道哪些日志以及都保存到Buffer中来。即不存在空洞的边界在哪里。为了追踪完全拷贝到Buffer中的日志,这里引入了GRASSHOPPER的数据结构,3. FLusher线程负责将不存在空洞部分的Buffer都刷到磁盘上面。最大的已经持久化的LSN这里称之为storage durable LSN (SDL)。只有那些产生的所有的日志的LSN都小于这个SDL的事务才可以在这个时刻完成提交。
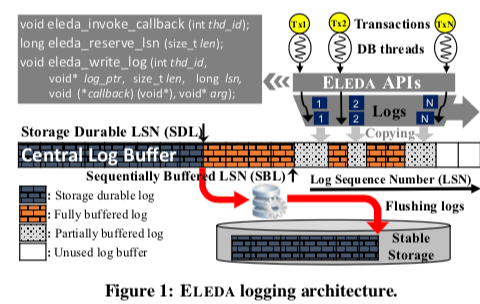
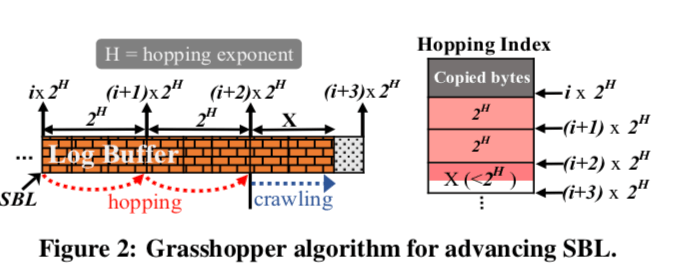
GRASSHOPPER是这里的一个核心的数据结构,主要的作用是用来推进SBL。GRASSHOPPER使用两种方式来推进SBL, hopping 和crawling。前者用于在目前知道的SBL和实际可以到达的SBL差距比较大的时候,后者则用于两者比较近的时候。hopping方式通过引入一个称之为 hopping index (or H-index)的表,来记录一个[i*2^H,(i+1)*2^H)范围内的已经写入Buffer的数据量,如果写入量为2^H,则可以说明这个区间内没有空洞。i这里为划分为区间之后区间的索引,而2^H为区间的长度。而crawling方式通过类似于一步步查看前面情况的方式推进。
为了隐藏IO操作带来的延迟,Eleda这里使用的方式和其它系统使用的思路差不多。都是工作线程在提交了写日志的请求之后,这个工作线程就会处理一个等待状态,在这里状态下面,它是可以继续处理其它事物请求的。在日志都只持久化之后,会通知这个线程,这个线程可以继续完成提交,并将结果发挥给客户端。
0x02 基本设计
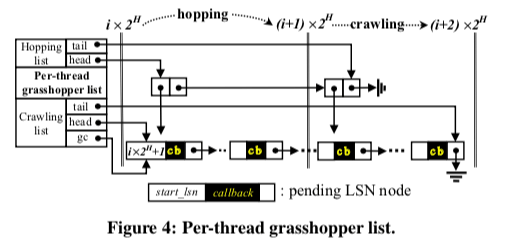
为了推进SBL,Eleda这里使用一些数据结构来追踪系统的运行情况。Grasshopper list,基本的结构如下图所示。用于记录已接写入到Buffer中都是没有持久化的日志。这里将相关的LSNs称之为pending LSNs。这里是每个数据库线程一个,并且和Eleda的工作线程共享。这里List实际上可以看作是一个FIFO的队列。这个list主要有两个部分,一个crawling list (or c-list) 和 一个hopping list (or h-list),c-list有所有的pending LSNs组成,而h-lsit的一个节点表示的是一个范围,如上面定义的一样。另外min-heap称之为LSN-heap,只有Eleda的工作线程占有,有每个grasshopper list中最小的LSN组成。在SBL使用crawling方式推进的时候,如果这个heap的最小值小于了pending LSNs中的最小值,这个heap的最小值就可以移除,添加新的最小值。
-
这里的操作始于添加一个LSN节点。一个数据线程获取到一个LSN之后,使用这个LSN标示一个要写的日志项。在拷贝到Buffer之后,数据线程创建一个新的pending LSN节点到grasshopper list中。如果这个日志项代表了一个提交,就得将相关的事物标记为waiting的状态。1. 这个pending LSN node先添加到c-list尾部,并设置c-list的tail字段,2. 如果这个pending节点的start lsn是一个范围[(i+1)*2^H,(i+2)*2^H)的开始,则还要将其添加到h-list中,3. 在h-index增加对应记录项写入数据的量。
-
为了追踪日志的空洞,这里就是前面提到的两个方式。SBL-hopping算法主要的思路是通过检查h-index中下一个hopping区间里面是否全部的数据都已接写入来决定是否可以推进SBL。在推进了这个SBL之后,就是对这些数据结构的修改操作,
... After the ELEDA worker thread advances the head of the h-list, it deletes all pointer pairs preceding the new head in the list. It is worth noting that the SBL-Hopping algorithm modifies only the head fields of the grasshopper lists,... -
SBL-crawling算法,这里的方式就是通过利用前面的最小堆和每个线程的Grasshopper list,来决定SBL是否可以推进到下一个pending LSN。可以推进之后,也需要修改相关的数据结构,
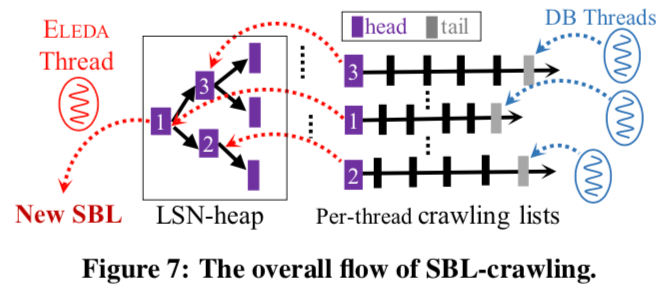
没有空洞部分的Buffer就可以被Flush到磁盘上面。
0x03 评估
Eleda实现在了Shore-MT和WiredTiger存储引擎上面,具体的评估的信息可以参看[1].
Border-Collie: A Wait-free, Read-optimal Algorithm for Database Logging on Multicore Hardware
0x10 引言
这篇Paper提出了一个优化ARIES风格的WAL算法。要明白这篇Paper提出这个算法的原因,可以先了解一些MySQL 8中对其WAL的优化[3],其优化的出发点是类似的:在ARIES-based的WAL算法中,刷Logging一般都是先将日志记录到一个log buffer中,然后再将这个buffer的数据按顺序刷入磁盘中。为了保存LSN是严格递增的,且log buffer中的数据没有空洞,这里常用的方式就是使用一把锁来处理,比如MySQL在8.0之前的处理方式。之前也有不少的Paper提出了各种优化方式,这篇Paper则提出了一种Wait-Free,Read-Optimal的算法,
Border-Collie outperforms the state-of-the-art centralized logging techniques by up to ∼2× and exhibits almost the same throughput with much shorter commit latency than the state-of-the-art decentralized logging techniques.
0x11 基本设计
Paper中假设使用的数据库系统中,发生的事件都有一个标示来表明这些事件的顺序,比如时间戳or 日志的LSN,这里将这些都称之为逻辑时间。这里定义了几个概念,1. Complete Log Set,用LC表示一组日志中,在系统中找不到一个逻辑时间在Complete Log Set表示的逻辑时间范围内的日志项,也就是说在这个所有的在这个时间范围内的日志都已经保存了。2. Maximum Complete Log Set,即系统中满足1条件的最大的一个。设这个Maximum Complete Log Set中最大的逻辑时间为LM_t。3. Recoverable Logging Boundary (RLB),直接由LM_t决定。这个边界代表了完整保存了已经发生事件的一个逻辑时间点。这里得思路就是如果每个工作线程通过表明其工作状态(开始写一个日志,一个日志写完了等),并附上其时间戳,这样就可以通过这些信息来确定已经保存到Log中的部分。一般而言在数据中工作线程数据一般和机器的CPU核心数量差不多,,RLB可以通过观察一个比较固定数据的工作线程状态就可以确定。这里先引入了几个protocols,
-
baseline logging protocol,1. 工作线程在写日志之前,先读取逻辑时钟并标记为black。将这些写入到自己的一个flag中。2. 工作线程读取逻辑时钟,附加到log中并写入buffer。这里满足了一个happen-before关系: FT ⪯ LT , if FC is black.。3. 第2部分完成之后,读取逻辑时钟,标记为white并保存到自己的flag中,这里同样由一个happen-before关系LT ⪯ FT if FC is white。这里会有三个逻辑时间,第二个就是一般WAL中用于决定Log顺序的。第一个和第三个用于用于标记日志的开始和结束,
... a log that has its associated logical clock but has not been stored yet, an on-the-fly log. The baseline logging protocol generates an on-the-fly log in Step L.2. Hence, a black flag informs us that there can be an on-the-fly log and a white flag assures that there is no on-the-fly log generated by the flag owner. -
baseline herding protocol,这个protocol用与探测RLB(tightly pursues the recoverable logging boundary)。也是基本的三步,1. Herding线程读取逻辑时钟,称之为Cutoff Clock,用CT表示,2. 扫描每一个工作线程的Flag,如果一个White的Flag且时间值小于Cutoff Clock的值,则使用Cutoff Clock的值代替,3. Herding线程选择最小值为一个新的Herding Boundary,用HT表示。这里和羡慕HT得出的方式一起理解更好。

以上的操作方式决定了这样的一些特性,
-
baseline logging protocol可以是的一个Work线程在一个时间最多只会有一个进行中的写日志操作。如果有这样一个操作中的日志,那么它的逻辑时间不会小于对应worker的flag中的逻辑时间;baseline logging protocol也保证了,对于一个工作线程Wi,由Wi产生的逻辑时间在$F_{Wi}^T$之前的,都已经保存了。这两个性质使得在每个工作线程Flag中保存的逻辑时间,成为决定RLB的关键信息。
-
使用L表示使用的已经保存的logs,如果$F_{min}^T$为所有工作线程中在其Flag中保存的逻辑时钟的最小值,则是由在这个值产生的日志都在L中。这个性质保证了小于这个值的所有日志是一个complete log set,但是并不一定是一个maximum complete log set。如果这里存在一个长时间的空闲的工作线程,则很可能算出来的$F_{min}^T$就是这个空闲线程保存的逻辑时间,但是可能和实际的maximum complete log set相差比较远了。也会导致保存到这个最小值后面的日志的数据是任意数量的。
-
为了解决上面的这个问题,这里定义个可能的空闲工作线程,即它已经完成了上一个写日志的操作,但是在cutoff clock之前还没有开始一个新的操作。这里说明起来好别扭¯_(ツ)_/¯,这工作线程的集合用W表示,即定义为 \(W^I = \{W_i ∈ W | F_{W_i}^C = white 且 F_{W_i}^T ≺ C^T\},\\ 当遇到可能的空闲工作线程的时候,这里使用Cutoffer Clock,而不是其Logical Clock,即:\\ H^T = \left\{ \begin{array}{ll} \min\{ F_{W_i}^T| W_i ∈ W\}, & W^S = idler,\\ \min\{C^T,\min\{ F_{W_i}^T| W_i ∈ W^N\}\}, & W^s \neq idler \end{array} \right.\) 这里用W^N表示非idler的工作线程集合。Paper中这里用各种符号表示搞的很麻烦。。。
-
HT由上面的baseline herding protocol得出,如果令LC表示为所有逻辑时钟值小于HT的已经保存日志的集合,那么LC就是一个complete log set。如果满足white flag的逻辑时间的值总是大于相应日志记录的逻辑时间的值,那么这里定义LC就是一个在HT时刻的maximum complete log。 由于LC包含的日志都是逻辑时间小于HT的,所以这里有要求white flag的逻辑时间的值总是大于相应日志记录的逻辑时间。
Implications
上面的几个protocol和定义决定了LC和RLB是相同的,所以这里的HT可以安全地作为RLB在写日志中使用。这里可能存在这样的一个问题,会导致后面得出来的HT反而比前面的出来的HT要小。考虑这样的一种的情况,1. 按照上面的protocol,一个工作线程开始写日志,将逻辑时间和颜色信息保存到自己的flag中,2. 在完成写日志之前,由于herding将这个工作线程误判为一个idler线程,herding线程设置了这个线程flag,3. 工作线程完成写日志之后,更新自己的flag,更新之后的逻辑时间比herding线程设置的逻辑时间要早。虽然这个导致了一个奇怪的现象,但是对于算法的正确性是没有影响的。使用这里的解决方式是在前一个HT和当前的HT中选择较大的一个。
0x12 In Action & Recovery
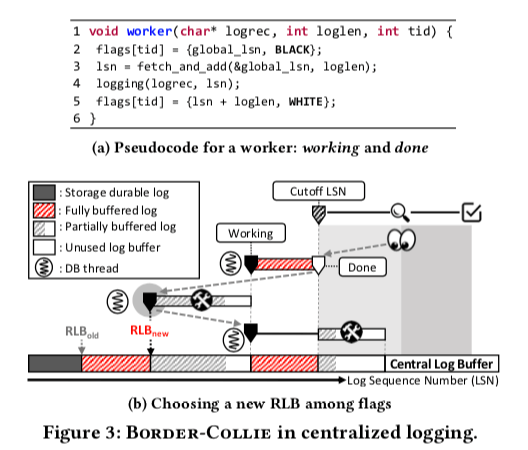
基本的Border-Collie算法如上面的图2所表示的那样。Paper中的设计是将Border-Collie作为一个同样的日志组件,既可以应用到传统的中心化的日志上面,如一般数据系统风格的WAL,另外一种就是现在的一些非中心化,如在SiloR中使用的。这里非中心化的核心思路是将日志写入到多个地方来提高性能。对于一般的 Centralized Logging,这里集成的思路是比较简单的。这里RLB的存在指示了已经完整保存到Buffer中的日志和部分or还没有保存到这个Buffer的日志的一个边界。下图表示的比较清楚。这里可以看出来RLB要解决的问题和前面MySQL 8.0中WAL优化方式要解决的问题是一样的,只是具体的解决方式存在的差别。在下面的伪代码中,标记为黑色的时候使用的逻辑时间使用的就是global的LSN,之后增加全局的LSN,然后使用增加之后的LSN写入日志。在标记为白色的时候,使用的逻辑时间是LSN + 日志的长度。选择一个新的RLB的过程如下,
- 假设有三个工作线程,第一个工作线程一个将日志写入到了Buffer中并设计了自己的flag为白色,第二、三个工作线程在设计自己的flag为黑色之后正在拷贝日志到buffer的过程中。这个时候herding线程首先读取global lsn设置cutoff LSN,然后扫描三个线程的flag。发现第二个工作线程的Flag中的逻辑时间最小且大于之前的RLB的值,所以新的RLB设置为这个值。
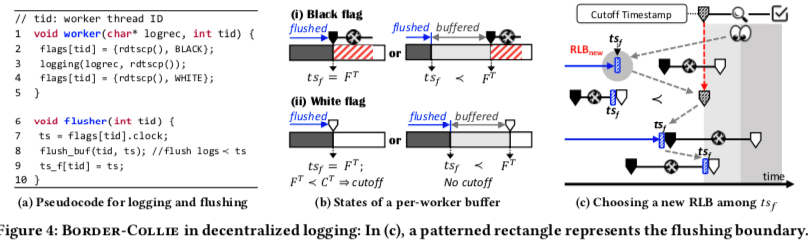
对于非中心化的WAL算法,这里使用硬件提供的指令来读取时间戳来作为逻辑时间。这里不同的是Buffer不是只有一份,很多时候是每个工作线程配置一个自己的Buffer,每个Buffer中的日志由时间戳来决定一个顺序。在这样的环境之中,一个好处就是不会有线程交替地写一个Buffer,也就是不会有Buffer中的空洞。RLB这里的作用是一个决定在此之前的日志都被刷盘的边界。这里算法维护了每个Buffer的flushing boundary (tsf ),保证了在一个Buffer中,小于这个边界的日志已经被刷盘。
- 非中心化的日志中,工作线程的工作方式和中心化的差不多。在Flusher中,处理的时候先读取一个worker的Flag中的逻辑时间,表明小于这个逻辑时间的日志都已经缓存到Buffer中。之后就小于这个逻辑时间的日志刷盘。之后更新tsf标记。这里后面的herding protocol处理的时候处理的是tsf,而不是工作线程的逻辑时间。
- 这里有另外的称之为Hasty Logs要处理。第一个Hasty Logs问题出现在多个线程并发更新一个Page,另外的一个Hasty Logs问题出现在数据库系统使用线程池来处理一个事务。问题如何处理TODO,具体这里参看[2]。
Border-Collie中恢复的方式在中心化的日志系统中没有什么特别的,只是在非中心化的中处理的要处理一些比较麻烦的情况[2]。
0x13 评估
这里在多个存储引擎中应用这个Logging方法,具体的评估信息可以参看[2].
参考
- Scalable Database Logging for Multicores, VLDB ‘18.
- Border-Collie: A Wait-free, Read-optimal Algorithm for Database Logging on Multicore Hardware, SIGMOD ‘19.
- MySQL 8.0: New Lock free, scalable WAL design,https://mysqlserverteam.com/mysql-8-0-new-lock-free-scalable-wal-design/
