FAST: Fast Architecture Sensitive Tree Search on Modern CPUs and GPUs
0x00 引言
这篇Paper是SIGMOD ’10的best paper。Fast Architecture Sensitive Tree(FAST)的出发点是利用现在CPU、OS的一些基本特点来构建一个更加快速的Tree结构。这里的提出的Fast Architecture Sensitive Tree不能说是一种通用的Tree数据结构,因为它的构建是一种在一组排序好的数据上面构建的。而这里主要讨论的是在一个已经排序好的数据集合之上,如何安排数据,达到更好的性能。一些符号:
E : Key size (in bytes).
K : SIMD width (in bytes).
L : Cache line size (in bytes).
C : Last level cache size (in bytes).
P : Memory page size (in bytes).
N : Total Number of input keys.
NK : Number of keys that can fit into a SIMD register.
NL : Number of keys that can fit into a cache line.
NP : Number of keys that can fit into a memory page.
dK : Tree depth of SIMD blocking.
dL : Tree depth of cache line blocking.
dP : Tree depth of page blocking.
dN : Tree depth of Index Tree.
0x01 基本思路
这里的数据带有比较强的假设性,这里假设key和rid都是4-byte大小,如果不是这种数据类型的,或许可以通过一些转化方式转化为这样的tuple,比如这个就是作为另外一个记录数组的index。下图表示来FAST的基本逻辑,既然是在已经排序好的数据上面构建查找树,这里根据SIMD指令宽度、Cache Line大小已经Page的大小来里安排这些数据的位置,称之为一种Hierarchical Blocking的方式。在hierarchical blocking的设计中,从root结构开始,考虑root下面NP个节点的组织。最前面的NK个节点使用breadth-first的方式组织安排,方便SIMD指令处理,接下来的每个(NK + 1)节点用同样的方式处理,用这样的方式组织一个dL深度的sub-tree。这里Cache Line大小的sub-tree在下图c中红色部分的知识。SIMD块在Cache Line块里面。更外面就是Page块,同样的,Page Blocking可以用SIMD块构建Cache Line块一样的方式用Cache Line块构建。Hierarchical Blocking形容的很贴切。
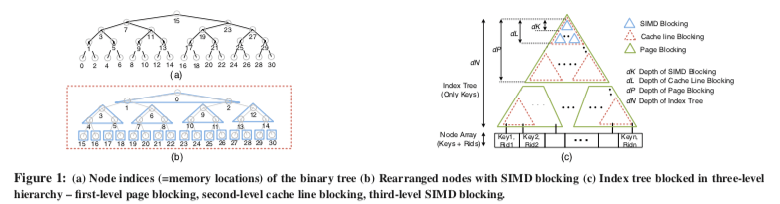
这里构建FAST的主要点就是其在保存位置index的计算,在计算出这个之后,思路比较简单,
// 构建的基本思路
(a) computing the index (say j) of the next key to be loaded from the input tuples.
(b) loading in the key : key′ ← Tj.key (if j>N , key′← keyL).
(c) T△k = key′, k++.
// 查找的基本思路
Step 1: At the start of a page, page_offset ← 0. Vtree ← sse_load(T△ + page_offset).
Step 2: Vmask ← sse_greater(Vkeyq, Vtree).
Step 3: index ← sse_index_generation(Vmask )
Step 4: page_offset ← page_offset + NK ·Lookup[index].
CPU版本的代码示例,
/*
T : starting address of a tree
page_address: starting address offset of a particular page blocking sub-tree page_offset: starting address offset of a particular cache line blocking sub-tree cache_offset: starting address offset of a particular SIMD blocking sub-tree
*/
__m128i xmm_key_q = _mm_load1_ps(key_q);
/* xmm_key_q : vector register Vkeyq, Splat a search key (keyq) in Vkeyq */
for (i=0; i<number_of_accessed_pages_within_tree; i++) {
page_offset = 0;
page_address = Compute_page_address(child_offset);
for (j=0; j<number_of_accessed_cachelines_within_page; j++) {
/* Handle the first SIMD blocking sub-tree (=2 levels of the tree)*/
__m128i xmm_tree = _mm_loadu_ps(T + page_address + page_offset);
/* xmm_tree: vector register Vtree. Load four tree nodes in Vtree*/
__m128i xmm_mask = _mm_cmpgt_epi32(xmm_key_q, xmm_tree));
/* xmm_mask: mask register Vmask. Set the mask register Vmask*/
index = _mm_movemask_ps(_mm_castsi128_ps(xmm_mask));
/* Convert mask register into index*/
child_index = LookUp[index];
/* Likewise, handle the second SIMD blocking sub-tree (=2 levels of the tree)*/
xmm_tree = _mm_loadu_ps(T + page_address + page_offset + Nk*child_index);
xmm_mask = _mm_cmpgt_epi32(xmm_key_q, xmm_tree));
index = _mm_movemask_ps(_mm_castsi128_ps(xmm_mask));
cache_offset = child_index*4 + Lookup[index];
page_offset = page_offset*16 + cache_offset;
}
child_offset = child_offset*(2^dp) + page_offset; }
/* child_offset is the offset into the input (Key, Rid) tuple (T) */
while (T[child_offset].key <= keq_q2)
child_offset++;
GPU版本的更多是如何利用好GPU的并发能力,这里和很多GPU的编程技巧相关¯_(ツ)_/¯。
/* In the GPU code, we process two independent queries within a warp*/
simd_lane = threadId.x %16; // 16 threads are devoted for each search query
query_id = threadId.x / 16; // query_id, either 0 or 1
ancestor = Common_Ancester_Array [simd_lane];
base_index = 2*(simd_lane) – 13;
__shared__ int child_index [2]; // store the child index for two queries
__shared__ int shared_gt [32];
for (j=0; j<number_of_accessed_cachelines_within_page; j++) {
/* Handle the SIMD blocking sub-tree (=4 levels of the tree)*/
page_address = (2^(4*j)-1) + page_offset*15; // consume 2 ops
int v_node = (Td + page_address + simd_lane))); // consume 4 ops
/* This is actually SIMD load. Our SIMD level blocking enables this instruction to be loading 16 consecutive values as opposed to loading 16 non-consecutive values */
int gt = (keyq > v_node);
shared_gt[threadIdx.x] = gt;
__syncthreads();
next_gt = shared_gt[threadIdx.x + 1];
if (threadIdx.x == 7) {
child_index[query_id] = 0;
}
if (threadIdx.x >=7) {
if (gt & !next_gt) { /*resj=1&& resj+1 =0*/
child_index[query_id] = base_index + shared_gt[ancestor];
}
}
__syncthreads(); // consume 2 ops
page_offset = page_offset*16 + child_index[query_id]; // consume 3 ops
}
child_offset = page_offset;
/* child_offset is the offset into the input (Key, Rid) tuple (T) */
While (T[child_offset].key <= keq_q2) child_offset++
0x03 评估
这里的具体信息可以参看[1].
S3: A Scalable In-memory Skip-List Index for Key-Value Store
0x10 引言
这篇Paper是LevelDB和RocksDB上面使用的作为Memtabl的Skip-List Index的优化。S3的基本思路是FAST和SkipList的结合。在Skip List较高的Level查找时候,缓存友好性等较差,而使用FAST替代优化了这个缺点。另外S3还使用Semi-order、多个Memtable情况下使用Multiple Semi-order Skip-Lists来优化查找等思路。
0x11 基本思路
S3的基本思路是FAST和Skip List的几个。在下吗的Semi-order的Skip List中,存在两种entry,一种为data entry,另外一种为guard entry。上面的Index Tree的Node Array会元素会指向gaurd entry。如果下面的Skip List为完全有序的,在这样的结构下面查找和范围查找都是很直观的方式。关于如何选择gaurd entry,Paper中上了一堆的公式,连LSTM网络这样的方式都用上了。两层的index设计不仅仅是提高了性能,而且在并发处理上面也有一些应用方式,假设这里有n个线程和m个guard entries,这里采用了和PALM中类似的思路,即将结构划分为部分,每个部分有一个线程来处理,这样这里就是每个线程处理n/m个guard的范围。同一个范围内的请求都放到一个队列之中,由指定的线程一个个处理。这样并发问题处理得更好,负载均衡又变成了另外一个要处理的问题。
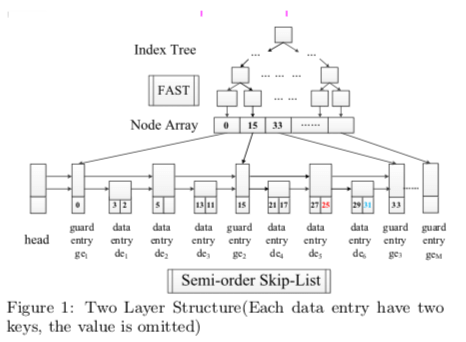
这里的 Semi-order skip-list是一个多层的linked list,存在两种entry类型。两个gaurd entry之间表示了一个entry area。其中的data entry包含了两个属性,一个是key-value pair的数量,另外一个是maxkey。在一个data entry内添加一个key-value时,是直接append操作,而不会进行排序。这样的设置方式提高了添加操作的性能。这样的设计的开销有两个方面,1. 在这个作为Memtable Flush到磁盘上去的时候,要进行排序的操作,不过由于其非有序的范围是有效的,这个开销不会很大。2. 添加性能的提高的一个代价就是查找性能的降低,这里用一个maxkey来降低了这个额外的开销。另外在can操作的时候,也会没麻烦一些。添加操作的伪代码,
key = kv.getkey()
gei = Find guard entry(key)
x,prev = Find less than(key,gei)
next = x.getnext(0)
if next is a guard entry then
if x is not full and x != gei then
insert kv into x
adjust maxkey in x if necessary
return
else if next is not full then
insert kv into next
return
generate new data entry y
adjust pointers using prev
if next is not a guard entry then
redistribute keys and values in y and next
return
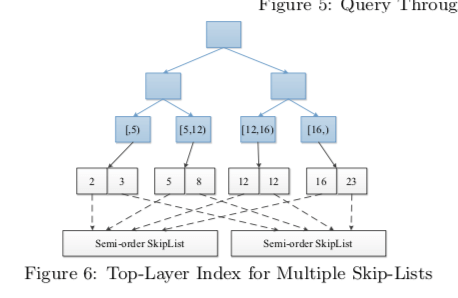
LSM-tree中,内存中通常会保存的多个memtable,这里的一个优化思路就是在多个Semi-order Skip List上面使用一个Index Tree,加速在多个Semi-order Skip List上面查找的性能,
0x12 评估
这里的具体信息可以参看[2].
FloDB: Unlocking Memory in Persistent Key-Value Stores
0x20 基本思路
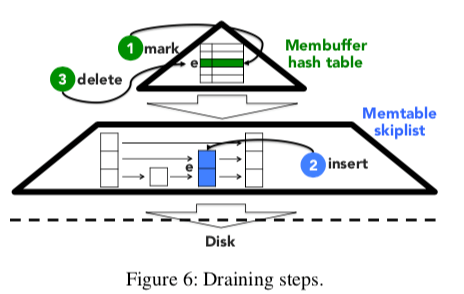
这篇Paper也将的是LSM-tree Memory部分的优化,啰里啰嗦的讲了15页,实际上就是一个思路,在Skip List前面加了一个小一点的Hash Table,数据先添加到Hash Table中然后在批量转移到SkipList中。添加和查找的思路不用说都可以猜到了。转移的做法如下图,这里分为三步,标记,添加到Skip List,最后再去删除。
好了,就是这样,100个字讲完了。
参考
- FAST: Fast Architecture Sensitive Tree Search on Modern CPUs and GPUs, SIGMOD ’10,
- S3: A Scalable In-memory Skip-List Index for Key-Value Store, VLDB ‘19.
- FloDB: Unlocking Memory in Persistent Key-Value Stores, EuroSys ’17.
