SocksDirect: Datacenter Sockets can be Fast and Compatible
0x00 引言
在网络编程中,RDMA和传统的Socket的差别是非常大,这两者就是完全不同的两种东西。RDMA的编程使用很麻烦,要处理非常多的问题,受的各种的限制也比较多。而直接裸写Socket也有一些麻烦,还是简单了很多。加上成熟的习惯的库,使用起来很方便。Socket受限制很少。之前也出现过一些用RDMA实现兼容的Socket接口,但是或多或少存在一些问题。这篇Paper的主要内容也是利用RDAM实现兼容Socket接口,从Paper中的描述来看,SocketDirect实现的很不错,
On the latency side, SocksDirect achieves 0.3μs RTT for intrahost socket, 1/35 of Linux and only 0.05μs higher than a bare-metal SHM queue. For inter-host socket, SocksDirect achieves 1.7μs RTT between RDMA hosts, almost the same as raw RDMA write and 1/17 of Linux. On the throughput side, a thread can send 23 M intra-host messages per second (20x of Linux) or 18 M inter-host (15x of Linux, 1.4x of raw RDMA write).
0x01 背景
在网络速度越来越快的情况下,100Gbps及以上的网卡目前认为Linux处理起来还是存在一些问题。所以出现了很多的优化方案,一些事优化Linux本身网络栈的;一部分是将网络栈移入用户空间,直接绕开Linux内核;还有的就是如RDAM之内的不同于Socket的传输方式。下表总结了使用前面的Socket接口存在的开销以及SocketDirect提出的解决/缓解方式。
- 每次操作的开销,1. 系统调用导致的内核态/用户态切换,特别是在Kernel Page-Table Isolation (KPTI)开启之后,会带来更大的开销。2. Socket FD locks,Linux为了保证多个线程/进程并发使用一个Socket的正确性,使用了一个per-socket lock。这个lock也带来了不好的开销。
- 每个数据包的开销,1. Transport protocol (TCP/IP)协议带来的开销,比如TCP中要处理拥塞控制、重传、TCP中很多习惯的Timer等。带来了不少的开销。2. 从NIC中接受处理数据包中,Buffer管理带来的开销。3. I/O multiplexing,分发数据包到对应的连接的处理带来的开销。4. Interrupt handling,使用这段处理一些操作带来的开销。5. Process wakeup,进程/线程在等待IO之后唤醒带来的开销,Paper中发现让出CPU比唤醒进程/线程重新运行快得多,这里主要的开销也就是唤醒进程/线程。
- Per-Byte的开销,这里主要指的就是每次使用read/write接口带来的数据拷贝开销。
- Per-Connection的开销,1. 第一个就是FD allocation,POSIX规定新分配的FD为最小的没有使用的整数这个在分配并发比较高的时候带来了不少开销,这个要求一致被诟病。2. TCP control block (TCB)管理中的锁开销,和Linux中的实现相关。3. New connection,主要就是Linux中处理新连接的开销,这个也在不少Paper中提出了优化方案,比如fastsocket。另外Linux自己也提出了Lock-less Listening来优化。
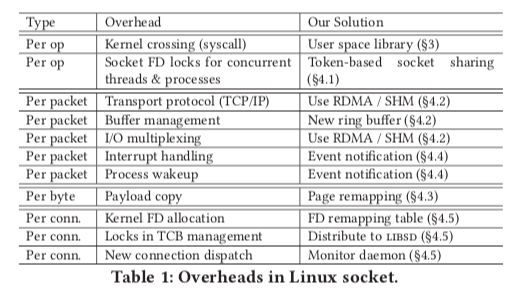
0x02 基本架构
SocketDirect的基本架构如下,整体实现在用户空间中。SocketDirect保持来和Linux Socket接口的兼容性,利用一个libsd hook原来的接口。另外使用一个FD remapping table区分用户空间的Socket还是内核空间的Socket,对于后者会直接转发给内核来来处理。用于在用户空间运行,应用不能被信任。为了隔离一些信息和处理一些全局的资源,比如端口等,这里的解决方式是使用一个Monitor,这个Mintor和应用直接使用共享内存队列进行通信。另外应用直接也可以直接构建基于共享内存的队列来进行通信。一个host上面的进程使用共享内存,不同host上面的进程使用RDMA,这个都是基于降低延迟提高性能的考虑。SocketDirct中每个Socket连接会被映射为一个SHM or RDMA QP,这个SHM or RDMA QP通过一个Token唯一标识。
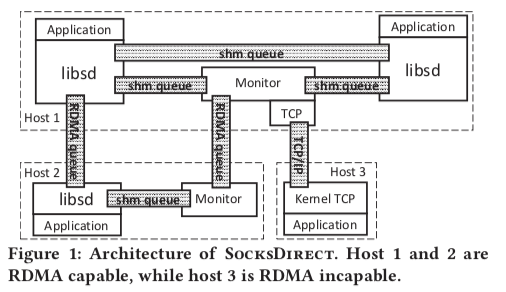
host内通信的时候,首先请求本地的Monitor,这个Monitor会在两个进程之间创建一个SHM queue,然后直接使用这个SHM queue通信即可。在host间通信的时候,本地的Mintor会先尝试和远程的Mintor建立一个一般的TCP联系,确认其是否只是SocksDirect 和 RDMA。如果都支持,则在两个Mintor之间建立一个RDMA queue,之后Mintor之间的通信使用这个RDMA queue。Mintor之间帮助两个应用之间建立一个RDMA queue,然后使用这个RDMA queue通信。如果不支持,则使用一般的TCP通信。
0x03 设计
Token-based Socket Sharing
目前的Linux的实现中,多个线程/进程可以使用同一个Socket,保护这个Socket被并发访问的基本方式就是使用一个Socket Lock。Paper这里则认为使用Lock的方式不利于提高性能,而是使用了一种基于Token的方法。逻辑上,Socket被表示为两个FIFO的队列(应该是TCP的队列,如果是UDP则不能保证先进的先出)。实际上多个线程/进程写 or 读一个Socket是一般很小概率的操作,大部分的情况都是一个线程来处理。SocketDirect为每个socket queue准备一个send token 和 一个receive token。每个token由一个active thread持有,持有这个token的线程才能进行send or recv的操作。另外的线程如果需要发送/接收数据,需要先获取这个token。
- Send/Recv操作,这里的操作方式是,如果一个inactive的线程想要获取一个Socket的token 的时候。它先将一个take over command放入和Mintor的SHM queue中。Mintor会轮询这些队列,在发现了这个command之后,Mintor会通知active线程归还这个token。请求的线程会进入等待状态,在得到Mintor回收了这个token之后,将这个token转发给请求的inactove的线程,这个线程变成active的状态,然后就可以直接发送 or 接收的操作。这个take-over的操作在SocketDirect的实现中大约花费0.6 μs。
- Fork, Exec 和 Thread Creation,在Fork和Exec的操作中,父进程和子进程之间的资源共享问题一直是比较难以处理的。SHM在 fork/exec之后还是一样共享的,但是RDMA相关的DMA memory regions则会产生变化。这里的解决方式是子进程使用之前,会重新初始化RDMA资源,如Protection Domain (PD), Memory Region (MR) 等。重新建立RDMA QP的操作会让对方有两个 or 更多的QP,所以这里使用的是RDMA write verb,不同的QP是等效的。对于FD Space,fork/exec之间的是共享的,而新创建的是独立的。SocketDirect使用remaping table处理这个问题,其保存在heap上,在fork之后为CoW的行为。如果需要在exec之后还能使用,这里就使用复制的方式。
- Container Live Migration,libsd中的信息和mintor的信息会在迁移的时候被迁移过去,这里没多少要处理的问题。要处理的问题就是RDMA不支持live migration,SHM也要进场处理。所以这里需要进程RDMA 和 SHM连接的重新建立操作。
Per-socket Ring Buffer
一般的内核网络栈实现中,都使用ring buffer从NIC中接收数据。一般的NIC只支持有限ring buffer数量,这样的话不同的连接就需要可能需要使用相同的ring buffer。SocketDirect使用per-socket的ring buffer来消除不同的socket操作同一个ring buffer带来的开销。另外,原来的ring buffer设计为在ring buffer中保存指向buffer的指针,而这里直接在ring buffer中保存数据。这个ring buffer在发送端和接收到被保存为两份,同时为了保证其数据和元数据的一致性,SocketDirect使用RDMA write with immediate verb,
In libsd, the sender uses RDMA write with immediate verb to generate completions on receiver. The receiver polls RDMA completion queue rather than the ring buffer. RDMA ensures cache consistency on receiver, and the completion message is guaranteed to be deliv- ered after writing the data to libsd ring buffer
Zero Copy
Zero Copy是很多高性能的网络栈要实现的一个功能。Linux最近的一些版本也支持一些Zero Copy的功能。这里实现Zero Copy的机制是re-mapping,即重新映射应用的虚拟内存页到系统对用buffer的物理内存页。为了支持这个功能,SocketDirect添加了一个kernel module,暴露出相关的接口。但是remapping page本身也是一个有开销的操作,这里的处理方式是只有在16KB以上的数据处理中才会使用zero copy,低于这个数据量的直接使用拷贝的方式。这里还要处理这样的一些问题,
-
Page remapping直接支持页对齐的内存的操作,这里的解决方式是hook一下malloc函数,使其分配的是4K对齐的内存。如果一个数据最后的chunk不是4K大小,直接使用拷贝的方式。对于不会读取数据直接转发的case,这里直接使用unmap操作处理。
-
发送方overwrite buffer的时候,目前的处理方式是使用CoW。但是很多时候发送分都不会care原来的数据,而是作为新的buffer使用,使用 recv or memcpy覆盖写这个buffer。这里的优化就是避免拷贝原来的数据。对于memcpy则重新映射内存页,去掉CoW。对于recv,原来的映射页被received页取代。
-
上面这么处理的原因是保证发送方在发送数据的时候处理buffer,但是一般的情况下都不会这么使用。这里通过一个O_DISCARD_SEND_BUF的flag告诉系统不会这么使用,
So, libsd can map new pages for the send buffer, and the sender do not need copy-on-write. Further, the ownership of pages in send buffer can be transferred to the receiver, and the receiver can read and write the pages directly. -
SocketDirect使用pool的机制来降低分配和释放buffer的开销。
-
……(。・ω・。)ノ
Event Notification
这里主要要解决3个问题,
- multiplex events between kernel and libsd,由于SocketDirect要同时直接用户空间的网络栈和内核的网络栈。两个地方的事件通知需要处理。SocketDirect会创建per-process的epoll thread来处理内核的事件。另外的线程来处理用户空间的事件。
- interrupt busy processes。如何终端一个busy中的进程,这里的处理方式是使用Linux signal。libsd中的signal handler会处理。这里会先查明目前是在运行libsb的代码而是应用的代码,在libsb中的时候不需要处理,如果是应用的代码则转为处理相关事件。
- 在合适的时候使用sched yield操作让出CPU,比如说目前这个线程无事可做的情况下。连续的sched yield这里会让这个线程执行sleep操作。并告诉mintor和其它的线程。
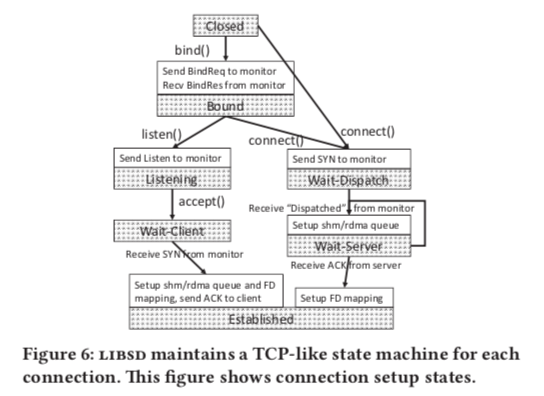
Connection Management
这里的链接管理模仿了TCP的连接管理。而且SocketDirect直接同时使用内核的网络栈和用户空间的网络栈。这里通过一个FD Remapping记录一个FD的属性等信息。链接过程的基本处理方式如下图。为了处理对方不支持RDMA和SocketDirect的情况,但是目前的TCP SYN和ACK包不能带有这些选项信息。这里直接使用raw socket发送带有特殊选择的SYN 和 ACK packet。有一方不支持的情况下,就降级为使用内核的网络栈,建立一个通常的TCP连接。连接之后的FD信息mintor会通过一个Unix domain socket发送给应用。为了处理同时在row socket包和通常的包的时候被RST,SocketDirect通过修改iptables规则来解决。
0x04 评估
这里的具体信息可以参看[1].
参考
- SocksDirect: Datacenter Sockets can be Fast and Compatible, SIGCOMM ‘19.
