iBTune: Individualized Buffer Tuning for Large-scale Cloud Databases
0x00 引言
这篇Paper是入里利用现在机器学习的一个方法在线调整MySQL Buffer Pool Size的一篇Paper。最近利用机器学习来调优数据库的Paper有不少,这篇Paper聚焦面小一些,主要就是Buffer Pool Size的大小问题。之前看过的微软的一篇Paper是如何自动建立次级索引的,这篇则是关于如何调整Buffer Pool Size。在实际的Large-scale Cloud Databases环境中用的时候,它们会有很多要处理的相同的问题,
... The successful deployment on a production environment, which safely reduces the memory footprint by more than 17% compared to the original system that relies on manual configurations, demonstrates the effectiveness of our solution.
0x01 基本思路
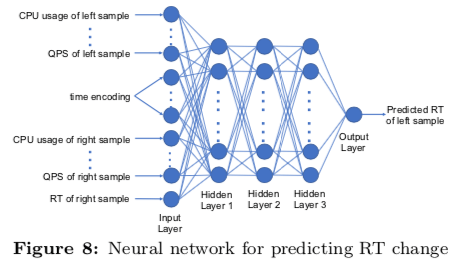
Buffer Pool的大小直接影响到数据库Buffer Pool的命中率,从而直接影响到数据库的性能。很多时候,数据库用户都倾向于使用更大的Buffer Pool来保障性能,但是很多时候这个会浪费内存。在理论上,数据库Buffer Pool的大小和缓存命中率存在一个关系,可以用如下的公式表示, \(\frac{\log(MissRatio) - p_i}{\log(BufferPoolSize)-c_i} \approx -\alpha_i \\\) p_i和c_i和workload特性习惯。根据一些经验值,比如在一些content distribution systems中,αi ∈ (0.6, 0.86),而在一些存储系统中αi ∈ (0.2,1.2)。根据目前的缺失率mr_cur,目前的Buffer Pool Size,bp_cur。以及要调整的目标缺失率mr_target,可以得出如下的公式。这里的一个要处理的问题是如何计算一个数据库实例的αi。这里使用了两种方式,第一种是根据之前使用过的Buffer Pool Size以及得到的Miss Ratio。在没有这些数据的情况下,处理起来要麻烦一些。这里使用一个数据库实例的历史统计学习来估算这个αi,在没有历史信息的情况下,使用αi=1.2。对于一些特殊的值比如miss ratio为0的,实际上会设置为为一个稍大于0的值。 \(\frac{\log(mr_{target})-\log(mr_{cur})}{\log(bp_{target)})-\log(bp_{cur})} \approx -\alpha_i \\\) 在确定了如何根据Buffer Pool Size计算缺失率之后,接下来要处理的事情就是如何确定缺失率。这里如何从降低成本的角度考虑,当然是在满足要求的情况下,这个Buffer Pool Size越小越好。iBTune如何确定这个缺失率的时候,利用了其运行着的几万个数据库实例。通过在众多的数据库实例中寻找相似的实例,来帮助确定缺失率。通过测量在过去4周内的logical read, io read, QPS, CPU usage等指标,来衡量两个实例时间的相似性。在获取来确实率的目标之后,可以根据前面的公式计算出要调整之后的Buffer Pool的大小。但是为了更加准确的衡量调整带来的影响,iBtune以Response Time为指标,使用一个DNN的模型来预测调整之后的Response Time。使用的DNN的基本架构如下,这里的DNN是一种Pairwise DNN,下图中的数据都来自(left, right)两个部分,其中left表示要预测的,而righet为选择的相似的。这个Pairwise DNN中的一些细节可以参看[1]。
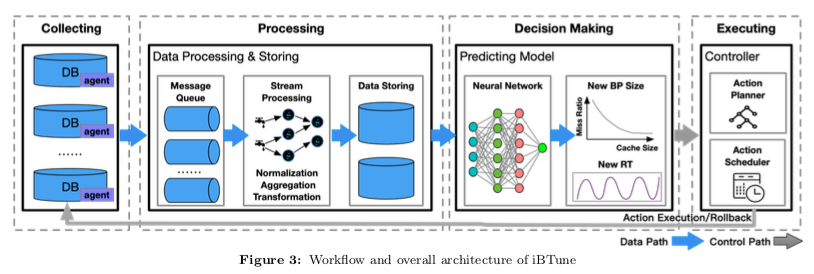
在有了上面的基本思路之后,iBtune系统的架构如下图。系统主要有4个组件,1. Data collection,用于收集数据库的一些信息,2. Data processing,收集的数据会进入MQ,经过Stream Processing System处理,处理之后保存到存储系统中。3. Decision Making,之后,根据数据和算法计算出要调整之后的Buffer Pool Size。4. Execution,执行调整操作。在时间中使用的时候,要考虑更多的事情,要避免错误的决策对线上的允许造成影响。比如微软的自动添加索引的方式选择了在另外一个镜像实例中操作的方式。这里主要是这样的一些措施,1. 使用保守的调整方式,2. 灰度策略,3. 出现问题及时回滚等。
0x02 评估
这里的具体信息可以参看[1].
BestConfig: Tapping the Performance Potential of Systems via Automatic Configuration Tuning
0x10 引言
这篇BestConfig的Paper也是关于如何自动调优的一篇paper。不过BestConfig关注的是一般性的调优问题。可以调优包括数据库、JVM、Apache以及Spark诸多类型的系统。BestConfig的主题思路还是基于搜索的方式。BestConfig的代码是开源的,看了一下,感觉写的有点emmmmm,¯_(ツ)_/¯,不好说。
BestConfig can improve the throughput of Tomcat by 75%, that of Cassandra by 63%, that of MySQL by 430%, and reduce the running time of Hive join job by about 50% and that of Spark join job by about 80%, solely by configuration adjustment.
0x11 基本思路
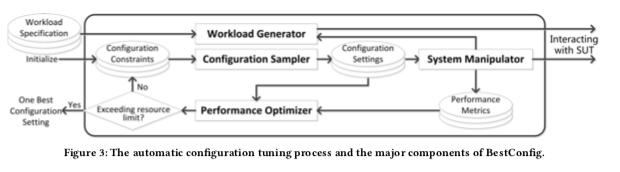
BestConfig的基本架构如下。不过感觉这个图根本就没啥用。总体而言,BestConfig基于搜索的方式,其目标是优化了utility function。比如如何只是为了优化吞吐,可以将这个函数设置为f(x) = x。如果是向提高吞吐,降低延迟,可以将设置为f(xt,xl) = xt/xl。在提高吞吐的同时限制内存的使用量,可以设置为f(xt,xm)=xt × S(cm−xm−5)。cm为使用内存阈值,S为sigmod函数。BestConfig这里主要就是解决两个子问题,1. The subproblem of sampling,采样系统运行时候的数据,2. The subproblem of performance optimization (PO),如何去优化这些参数。为了解决这两个子问题,这里使用的方式是divide-and-diverge sampling (DDS)方法和 the recursive bound-and-search (RBS) 算法。
The subproblem of sampling
Divide & Diverge Sampling,即DDS。采样的问题是如何覆盖高纬度的参数空间。参数空间这里主要的问题就是随着维度增加选择的空间指数级增长的问题。为了将少搜索的空间,BestConfig将参数空间划分为子空间,每个子空间内,随机选择一个值代表这个子空间,
Given n parameters, we can divide the range of each parameter into k intervals and collect combinations of the intervals. There are k^n combinations, thus k^n subspaces and samples. This way of sampling is called gridding or stratified sampling. Thanks to subspace division, gridding guarantees a complete coverage of the whole parameter space.
这样在维度非常高的时候,还是会有搜索空间爆炸的问题。由于资源的限制,最后只针对对性能影响大的参数进行调整。这个在OtterTune之类的系统中也有使用,这样的参数被称之为Knob。而且这里更加关注参数调整时候性能变化,而不是参数值本身。在将参数取值范围划分为k个区间之后,BestConfig避免使用所有可能的组合,
After dividing parameter ranges into k intervals, we do not make a full combination of all intervals. Rather, we take a permutation of intervals for each parameter; then, we align the interval permutation for each paremeter and get k samples.
这里有点模糊╮( ̄▽ ̄””)╭。
The subproblem of performance optimization(PO)
BestConfig通过Recursive Bound & Search,即RBS的方式尝试的出更优的解。如下图,BestConfig将不同参数组合得到的性能可视化为面的方式。在通过前面采样方式得到的最优解中,以及从下图中性能面都是连续的,这里就可以猜想在这个采样取得的周围可以找到更优的解。初始采样得到的点称之为C0,BestConfig会在C0周围的一个bounded space进行采样,取到不同的参数取值。在这些采样得到的之后,进行参数调整,得出性能结构。选择其中最好的点,递归进行上面过程就是这里的方法。
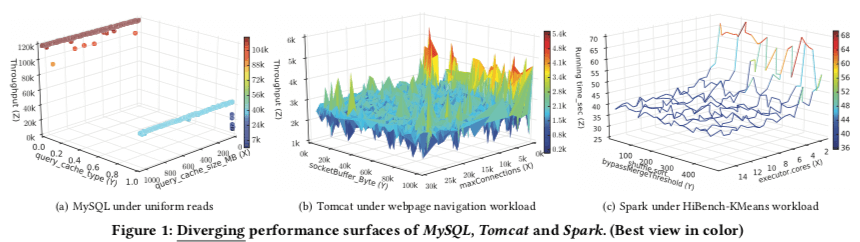
这里要处理的问题就是这个bounded space具体是多大,采样的点数量选择多少合适,以及递归到什么样的程度之后更加合适.
For each parameter pi , RBS finds the largest value pi_f that is represented in the sample set and that is smaller than that of C0. It also finds the smallest value pi_c that is represented in the sample set and that is larger than that of C0. For the dimension represented by the parameter pi , the bounded space has the bounds of (pi_f , pi_c ).
0x12 评估
这里的具体信息可以参看[2].
参考
- iBTune: Individualized Buffer Tuning for Large-scale Cloud Databases, VLDB ‘19.
- BestConfig: Tapping the Performance Potential of Systems via Automatic Configuration Tuning, SoCC ‘17.
