Dremel: Interactive Analysis of Web-Scale Datasets
0x00 核心内容
Google的这篇Paper描述了其使用的Dremel的数据分析系统,据说目前Google Cloud上面提供的BigQuery也以此为基础。不过这篇Paper中没有很多有价值的内容,Paper中主要就是2点:1. nested data model,一种挺特别的数据存储模型。nested data model看起来与Proto Buffer结构非常类似。而Proto Buffer在Google被大量使用,估计使用这样的数据模型也有Proto Buffer的原因。2. 另外一个就是其查询语言和查询引擎,Paper中这里只是简单地描述了一下。
Nested Data Model
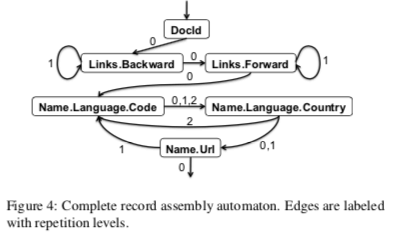
下图是一个nested记录和其scheme的一个实例,和Proto Buffer还是很想的。Dreml用列存的方式保存数据,这样就需要有一种方式将Neated Data Model用列存的方式表示,基本的思路如下图。直接使用一般的普通scheme的方式将列之间拆开不能很好地表示Dremel的Nested Data Model,还需要一些额外的东西。这里Dremel定义了一个Repetition Levels和一个Definition Levels。Repetition Levels表示at what repeated field in the field’s path the value has repeated。比如下图的记录的例子r1中,第一个Name中Language出现了两次, Name.Language.Code一列中,en-us 为第一次出现,Name.Language.Code三层都是没有出现过的,所以r字段为0,下面一个值 en为Language的重复记录,所以r字段为2 。二接下来的 NULL和en-gb值都是Name的重复,在Name.Language.Code定义r 为 1。这样实际上就表示出了Nested Data Model中的嵌套的结构。另外的Definition Levels用于解决how many fields in p that could be undefined (because they are optional or repeated) are actually present,比如r1的记录没有Backward字段的数据,但是Link字段是有的,这样在Links.Backward列中,一条d为1的NULL记录将这个信息就保存了下面。保存的也就是这个记录在那一层/Level为NULL。

在这样的Nested Model Data中读取也是比较麻烦的,
Query Language and Execution
Dremel使用的为一个从SQL改来的,很多是针对Dreml使用Dremel Data Model进行的改动。Paper中给了下面的这个查询的例子,得出的结果,以及其会映射到Nested Data Model的Scheme。

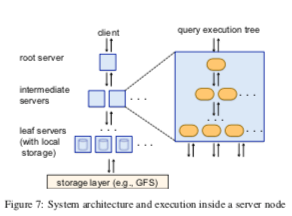
Neated Data Model感觉有点奇怪。不过其查询引擎估计会是有趣的,不过Paper中这里只是简单地描述了一下。主要就是其tree architecture。Dremel使用multi-level serving tree来执行查询。root server接受请求,读取元数据,根据元数据分发请求。leaf servers和存储层交互 or 从本地磁盘读取数据,存储不出意外就是使用Google的GFS/Colossus。root和leaf之间要有intermediate server,可能存在多层的intermediate sevrers。操作在这样的multi-level serving tree下面应该会是流水线方式执行,每层会有对查询的分发、结果聚合等等的操作。实现将查找方法到大规模的机器上面执行,然后返回到root serber结果。
// More…
Processing a Trillion Cells per-Mouse Click
0x10 核心内容
PoweDrill也是Google开发的一个数据分析系统。不过听说这个PoweDrill已经在Google中被舍弃了,败给了其它的系统。和Dremel几大最大的不同,在Paper[6]中提到,PoweDrill是一个columnar in-memory distributed SQL query engine,数据会在内存中处理,适合于执行简单的,容易并行的查询。而Dremel能够支持更大的数据集,对更复杂的查询也更加适合。PoweDrill的这篇Paper更着重说了其数据组织方式,以及在这个上面的优化。
分区
PoweDrill使用记录的一组的fields来进行分区,比如(f1,f2,f3…)。数据会首先根据f1来进行分区,如果根据f1的分区就满足的分区之后的要求,分区完成。否则,在根据f2进行分区,以此类推。这种方式称之为composite range partitioning。一般情况下设置3-5个字段用来分区比较好。在将数据分区为合适大小的chunk之后,并不是简单地将数据都保存到chunk里面,而是使用另外的更加复杂的方式。PowerDrill这里使用了,1. global dictionary,保存了一列数据中所有的不同的值,每个值会对应到一个global id。这个dictionary可以根据值来查询到global id,也可以根据global id查询到值。直接说就是一个排序的了的BiMap。2. 另外的一个chunk dictionary,主要有两个部分,ch。elems记录了数据的chunk id,另外的ch.dict记录了chunk id到global id之间的相互映射,也就是一个BiMap。获取ch.elems中的值记录的思路就是dict[ch.dict[ch0.elems[0]]],即获取chunk 0中的第一个元素/值。这样保存的数据的主要好处在Paper中提到: 方便确定那些chunks在一次查询中是可以直接跳过的;更加利于使用Dictionary encodings,压缩数据,减少内存消耗。全局表中的数据会去重保存,排序之后也更利用压缩。等等。
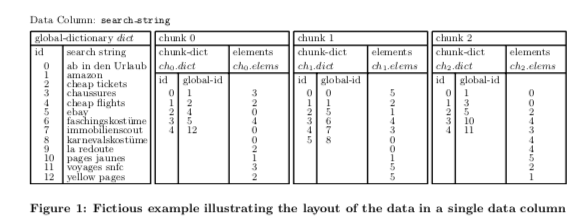
Paper中PoweDrill可以在查询中跳过Chunks,避免一些扫描也是说的一些多余的地方。这里以一个SQL查询为例。下吗这个查询中,要求满足search_string的取值在集合(“la redoute”, “voyages sncf”)中。这样在查询执行的时候,先根据global dict查询到global id,然后执行的时候查询每个chunk的dict,如果没有这些global id就可以直接跳过了,避免了处理一些chunk的数据。Paper中提到这很多情况下,这个可以取得非常好的效果。
SELECT search_string, COUNT(*) as c FROM data
WHERE search_string IN ("la redoute", "voyages sncf")
GROUP BY search_string ORDER BY c DESC LIMIT 10;
Paper中还有一大段是将如何得到这样的数据保存方式,以及其中的一些优化思路和方式。另外的一些在实际系统中使用的一些优化方式/思路:针对包含AND, OR, NOT, IN, NOT IN, =, !=这样的查询,考验跳过一些chunks。这个也是这篇Paper主要说的内容之一。另外对于下面这样的查询,将timestamp物化成为一盒虚拟的列,能够优化查询的性能,
SELECT date(timestamp) as date, COUNT(*), SUM(latency) FROM data
GROUP BY date ORDER BY date ASC LIMIT 10;
为了避免将global dict一次都load到内存,将global dict拆分为sub dict保存。而且在可以使用Bloom-filters来决定一个sub dict是否存在需要的数据。
// More…
Mesa: Geo-Replicated, Near Real-Time, Scalable Data Warehousing
0x20 核心内容
Mesa也是Google一个OLAP类型的系统,可以发现Google在这个上面已经造了很多的轮子。在[6]总多Mesa的基本的特点总结很好,Mesa自身不支持SQL,而是利用F1来支持。主要功能:Mesa is designed mainly for storing and querying aggregated stats tables, with a predominantly delta based low latency (measured in minutes) data ingestion model. 。 Mesa是一个将上游来源的数据,在Mesa系统内做聚合统计等操作,给用户提供查询的功能的系统。Mesa要达到的基本目标对设计影响比较重要的,1. Atomic Updates,要能原子地更新多个数据;2. Consistency and Correctness,要求strong consistency 和 repeatable query;3. Near Real-Time Update Throughput,接近实时的更新;4. Online Data and Metadata Transformation,支持在线Schema变更,且不能影响到正常运行;4. 另外就是常见的可拓展、高性能,fault tolerance等。
数据模型
Mesa使用结构化数据,数据保存在table中,数据会有对应的类型。处理数据列(dimensional attributes)部分外,Mesa的表中还保存了指标列(measureattributes)。这里可以将dimensional attributes称之为key,而measure attributes称之为value,类似于一个特殊的KV模型。这个measure attributes用一个定义的聚合函数计算而来,aggregation function。这个函数要求要满足结合律,在一般情况下满足交换律。下面是基本schema的例子,比如table A中,三个dimensional attributes,两个measure attributes。两个measure attributes分别为Clinks和Cost,都使用聚合函数SUM计算而来。
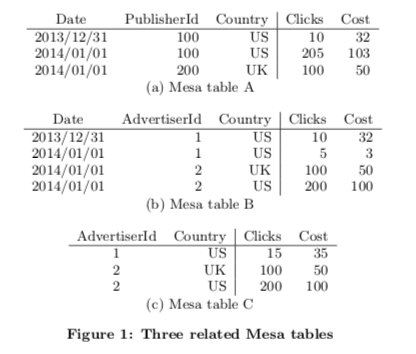
Mesa支持进实时的高吞吐的更新。为了实现高吞吐,更是以批量的方式进行,更新频率一般在小几分钟。Mesa也使用多版本的方式,每次更新的时候会带上一个自增的版本好,而在查询的时候也要带上一个版本号的信息。上面的Schema例子中,Table C为Table B的物化视图,对应下面的查询,
SELECT SUM(Clicks), SUM(Cost) GROUP BY AdvertiserId, Country
在多版本数据的存储上面,Mesa有不少的优化。多版本下面,如果对所有版本独立保存,每次都进行聚合操作,其存储成本和查询的开销都很大。Mesa会预先聚合特定版本的数据,使用deltas的方式保存。这样保存的一个记录会有多行,并带有delta versions。这个和一些数据库中使用的保存MVCC的数据有些类似。Delta数据可以进行归并,比如[V1, V2]和[V2 + 1, V3],可以被归并为[V1,V3],通过简单的每个row keys和聚合values就可以实现。
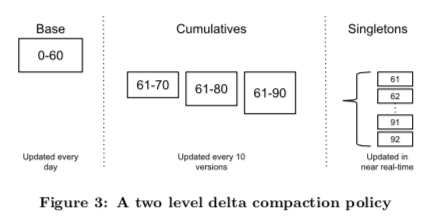
Mesa不会将数据都以Delta的数据保存,而是从一个Base的数据出发,后面记录Delta。所以需要将合适的时候将一些Delta数据进行归并/合并操作。这个操作称之为base compaction。在进行base compaction的时候,会读取一个范围内的所有的delta信息,而这个base compaction操作一般在以天的频率进行操作,一些时候也会有成百上千的delta的信息。Mesa这里使用了一种cumulative deltas的策略来优化这个问题,其基本的思路就是一个记录的delta积累到一定数量时候,进行一次cumulative deltas操作。上图为一个例子,这样就是一个两级的Compaction的过程。最左边饿的为Base,聚合了之前的使用信息,而中间的Cu,ulatives为最近一些更新的cumulative deltas,为每10个进行一次小的Compaction操作。而最右边的为目前最近一些Delta信息,还没有进行任何的Compaction的操作。
基本架构
Mesa的架构范围单DC部署和多DC部署的情况,也依赖于Google自己的Bigtable、Colossus等的系统。单DC部署的情况下,mesa分为两个子系统,Update/Maintenance Subsystem 和 Query Subsystem。两个子系统是分离的,可以分别拓展。Metadata保存在Bigtable中,而数据文件保存在Colossus中。这两个子系统的设计有点读写分离的意思,和AnalyticDB有点类似的地方,
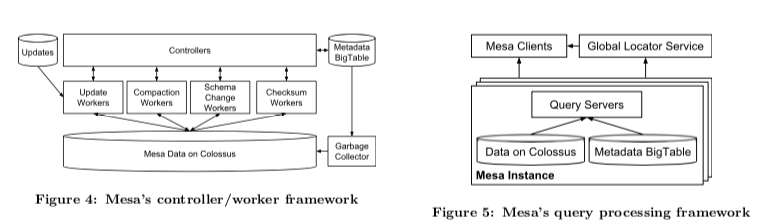
- Update/Maintenance子系统主要执行数据更新、执行Compaction操作、操作Scheme修改和对进程chksum等的工作。这个子系统基本的模式是Controller/Worker的模式,Controller管理表的元数据,以及对worker进行调度,另外Controller会缓存这些元数据。所以在Paper说Controller就是
The controller can be viewed as a large scale table meta- data cache, work scheduler, and work queue manager.。在下图中,表示出worker分为4中类似,分别执行更新操作、Compaction操作、Scheme变更操作以及Checksum操作。对于每种类型的worker,Controller会维护一个queue。Controller将task丢到对应的queue中,Worker使用pull的模式从对应的queue获取任务。 - Query子系统执行就是读的部分。Clients就接受到用户请求支持,查询表的元数据,获取那些数据文件保存了需要的数据。并对对应各个部分查询的结果进聚合操作,然后将结果转化为Mesa内部的格式返回给客户端。Mesa自己支持有些的查询操作,比如filter和“group by”,更加高级的操作有其它的系统完成,比如F1。针对有些查询要求低延迟而涉及到数据量有不大,而有点查询要求高的吞吐,会设计到大量的数据,Mesa会提供一个label的功能,根据查询的label选择不同的执行策略。
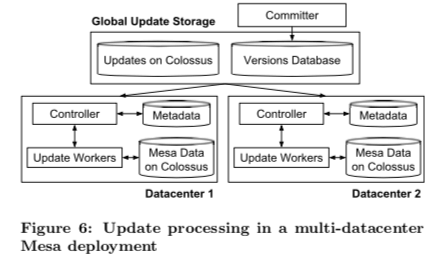
在多DC的部署上面,Mesa在不同的DC中保存数据副本以实现系统的高可用。多DC数据的时候,额外引入了一个Commiter和一个Global Update Storage。其中Commiter作为沟通Mesa和上游数据源系统的桥梁,是statless的。对一个一个批次的更新,Commiter赋予其一个版本号,将所有的相关的元数据保存到一个versions database(e.g., the locations of the files containing the update data)。这个versions database为一个基于Paxos的存储系统。Update/Maintenance子系统中的Controller会监听这个versions database。如果发现有新数据的信息,将其拉取下来,交给对应的woeker进行处理。在处理完成之后回复versions database。Versions database在commit criteria条件满足之后(比如多数副本报告完成),就可以将对应version的更新Commit,然后进行下面的操作。
// More… 一个优化方法和一些经验总结。
Goods: Organizing Google’s Datasets
0x30 核心内容
Goods是一个数据的Catalog。Google用Goods来对其它的各种类型的数据集的元数据做一个大的目录,来方便数据的管理。Goods组织的数据模型基本示意如下。前段的是一些dataset roganizing工具。Goods管理的元数据使用一个Path or Identifier来表示。
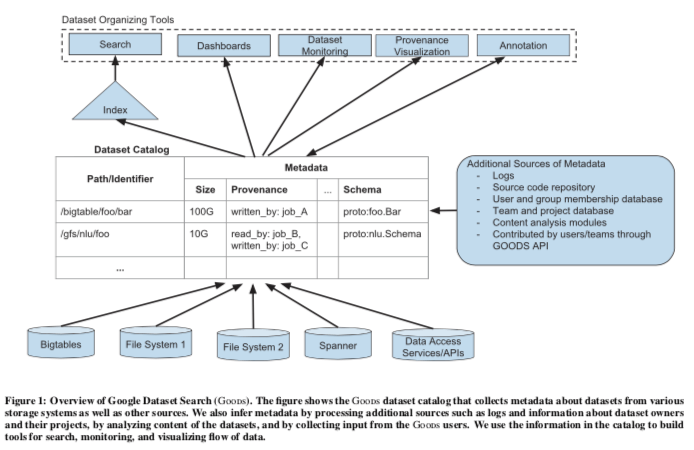
Metadata包括各个方面。Paper中的下面这个表格总结的很好。在管理这样的数据时,Paper总结6个主要的问题,1. 数据集的规模非常大 ,约为260亿;2. 数据种类非常多;3. 目录经常变动;4. 元数据不能完全确定;5. 如何衡量数据集的重要性;5. 如何理解数据集的语义。找到了这些元数据中主要来自于这样的方式,
- 基础元数据,主要保存时间戳、格式所有者和访问权限等的信息,这里直接通过数据爬去获得;
- 来源信息,这里的Provenance信息主要就是数据集如何被产生,如何被消费。以及其依赖于那些数据,那些数据集依赖于它。通过分析production logs来发现那些任务在读取、写入对应的数据集。如果创建一个图来发现数据集之间的依赖关系。
- Schema,大部分的数据集的格式都是自描述的,大量使用Proto Buffer来进行序列化和反序列化。通过在中央代码库中找到的Proto Buffer定义来一个个匹配时一种方法。
- 内容摘要,关于内容的一些摘要信息,比如采样内容发现平凡token。使用HyperLogLog估计一个字段不同值的数量等。另外也通过收集fingerprints来发现数据集之间的相似性。
- 用户注解,让用户来提供一些关于数据集的信息。
- 语义,对于一些使用Proto Buffer格式保存的数据,可以通过分析其源代码、注释等来发现其语义信息。也通过分析数据集的内容,如何通过Google’s Knowledge Graph来匹配相关的信息。
| Metadata Groups | Metadata |
|---|---|
| Basic | size, format, aliases, last modified time, access control lists |
| Content-based | schema, number of records, data fingerprint, key field, frequent tokens, similar datasets |
| Provenance | reading jobs, writing jobs, downstream datasets, upstream datasets |
| User-supplied | description, annotations |
| Team and Project | project description, owner team name |
| Temporal | change history |
这些元数据使用Bigtable来保存。然后就是如何管理更新task、如何保存这些数据等等的内容。
// More….
参考
- Dremel: Interactive Analysis of Web-Scale Datasets, VLDB ‘10.
- Processing a Trillion Cells per Mouse Click, VLDB ‘12.
- Mesa: Geo-Replicated, Near Real-Time, Scalable Data Warehousing, VLDB ‘14.
- Goods: Organizing Google’s Datasets, SIGMOD ‘16.
- F1 Query: Declarative Querying at Scale, VLDB ‘18.
- Procella: Unifying serving and analytical data at YouTube, VLDB ‘19.
