MillWheel: Fault-Tolerant Stream Processing at Internet Scale
0x00 核心内容
这篇Paper是Google的关于Stream Processing系统的一篇文章。估计Google内部早已经有相关的替代系统。MillWheel这里提出的几个核心的东西:exactly one delivery(注意exactly one delivery和exactly one procssing还是区别很大的),Low Watermarks等。 MillWheel每条记录用一个key来标识。MillWheel中,系统的运行可以看作是一些computations组成的DAG图,数据在DAG的边中运行。数据的流动抽象为Stream,其中的每条数据是一个三元组<key, value, timestamp>。MillWheel可以做到exactly one delivery,并且实现了数据之间的乱序处理,这些依赖于MillWheel的Persistent State、Low Watermarks和Timers等机制。
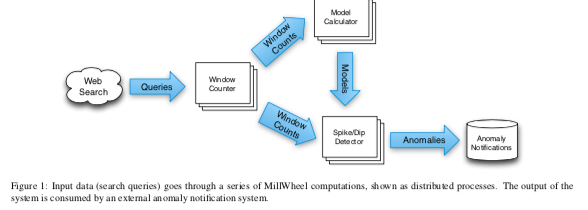
-
Persistent State,要实现exactly one delivery,主要就是要处理两件时间,1. 对于丢失的信息要有重发的逻辑,2. 对于错误重发实际已经被处理的消息要有去重的逻辑。MillWheel会将一个数据的处理状态信息持久化到分布式存储系统上面。Google有着强大的Bigtable和Spanner之类的系统,在这里就直接将State保存到这些系统上面,而不是向Flink之类的得利用其它的机制来实现类似的功能。
在exactly one delivery语义下面,所以处理记录的时候,一般使用这些的逻辑,1. 查询这条记录是否已经重复了,对于重复的数据,丢弃处理;2. 运行用户的处理数据的逻辑;3. 将处理之后的状态持久化到存储系统;4. ack给发送端/上游;5. 将生成的数据发送给下游。Paper中给出了一段代码:
// Upon receipt of a record, update the running
// total for its timestamp bucket, and set a
// timer to fire when we have received all
// of the data for that bucket.
void Windower::ProcessRecord(Record input) {
WindowState state(MutablePersistentState());
state.UpdateBucketCount(input.timestamp());
string id = WindowID(input.timestamp())
SetTimer(id, WindowBoundary(input.timestamp()));
}
// Once we have all of the data for a given
// window, produce the window.
void Windower::ProcessTimer(Timer timer) {
Record record = WindowCount(timer.tag(), MutablePersistentState());
record.SetTimestamp(timer.timestamp());
// DipDetector subscribes to this stream.
ProduceRecord(record, "windows");
}
// Given a bucket count, compare it to the
// expected traffic, and emit a Dip event
// if we have high enough confidence.
void DipDetector::ProcessRecord(Record input) {
DipState state(MutablePersistentState());
int prediction = state.GetPrediction(input.timestamp());
int actual = GetBucketCount(input.data());
state.UpdateConfidence(prediction, actual);
if (state.confidence() > kConfidenceThreshold) {
Record record = Dip(key(), state.confidence());
record.SetTimestamp(input.timestamp());
ProduceRecord(record, "dip-stream");
}
}
Low WaterMark也是MillWheel中一个重要的概念,这里也主要涉及到可以实现数据的乱序处理。而Low WaterMark的存储就是让数据的乱序程度可以有一个访问,即某个数据不能太落后的。 Low WaterMark定义为min(oldest work of A, low watermark of C : C outputs to A),C为A的上游的Computation,如果没有,就是oldest work of A。另外MillWheel中的数据导入称之为Injector,Injector工作的时候也会设置一个估计的Low WaterMark。通过Low WaterMark,可以知道这个时间点的数据都已经被处理了,而后面的数据可能还没有被处理。对于系统中达到的Low WaterMark之前的数据,需要另外的处理方式,比如直接丢弃处理。一个文件Injector的实例,
// Upon finishing a file or receiving a new
// one, we update the low watermark to be the
// minimum creation time.
void OnFileEvent() {
int64 watermark = kint64max;
for (file : files) {
if (!file.AtEOF())
watermark = min(watermark, file.GetCreationTime());
}
if (watermark != kint64max)
UpdateInjectorWatermark(watermark);
}
Timer在MillWheel是一个per-key programmatic hooks,即一个钩子。会在特定的wall time 或者是low watermark value下被触发。Timer在运行中不是必须的,主要用于实现一下额外的功能。 利用Bigtable or Spanner之类高可用的分布式系统系统给了MillWheel实现容灾很大的便利。除此之外,MillWheel实例实现在出现系统崩溃、恢复的情况下,上游发送给下游的数据一致,这里使用了称之为Strong Productions的机制。这种不一致出现的情况比如上游根据wall time累积一段时间内的数据之后在发送给下游,但是这个过程中出现crash。重启在此处理就可能出现发送的数据不一致,这里就是将这些数据做一个checkpoint。如何业务本身有幂等性,可以去除一些处理重复数据的逻辑。
// more
The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing
0x10 核心内容
这篇Paper描述的不是一个具体的Stream Processing系统的实现,而是一种Stream Processing的编程模型。从目前来看,Dataflow以及其开源实现的版本还是很有可能是以后Stream Processing编程模型的最典型代码。Stream Processing编程中,这里提出主要就是这样的几个问题,
– What results are being computed.
– Where in event time they are being computed.
– When in processing time they are materialized.
– How earlier results relate to later refinements.
为了给解决这样的问题的方法一个很好的抽象,Dataflow给出了这样的一些编程模型,1. windowing model,支持按照非对其的event time的windows处理数据,2. triggering model,根据运行时输出的结果来决定输出的情况,支持丰富的触发语义,3. Incremental Processing Model,将数据的retractions和updates整合到windowing和trggering model中。这里event time指事件发生的时间,而processing time则是事件被处理的时间。processing time只可能晚于event time,当然在实际事件被处理的时候,希望processing time越接近event time越好。Window是Dataflow中的核心概念之一,一般有这样的一些window模式,1. fixed,即相连的一段特定时间长度内的集合,2. 而Sliding,滑动窗口,这里主要涉及到这个窗口的大小和每次滑动的距离。如何这两个参数相等,就是fixed模型的window。3. Session模式,一段特定的会话决定的window。
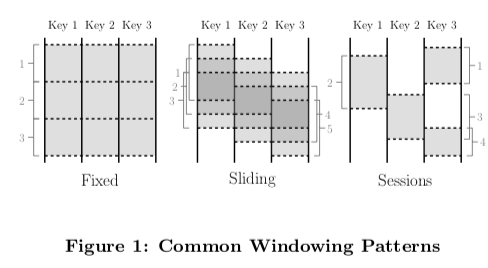
Dataflow两种基本的操作原语式ParDo、GroupByKey,ParDo在一个key-value的集合上面进行并行的transformation操作,具体如何取处理数据有应用的逻辑决定,可以直接应用到无限的stream抽象上面。而GroupByKey是按照根据key进行聚合操作,需要与window结合使用。Window的操作可以拆分为两个相关的部分,1. Set<Window> AssignWindows(T datum),将一个数据分配给一个windows,2. Set<Window> MergeWindows(Set<Window> windows),合并windows。为了支持根据event-time处理数据,在系统中数据被表示为(key, value, event_time, window)这样的四元组的形式,window在数据进入系统的时候被分配。一个简单的API例子。在[3], 《Streaming System》中有更多的例子。
PCollection<KV<String, Integer>> input = IO.read(...);
PCollection<KV<String, Integer>> output = input
.apply(Window.into(Sessions.withGapDuration(Duration.standardMinutes(30))))
.apply(Sum.integersPerKey());
Triggers & Incremental Processing
Dataflow自持非对其的基于event time的窗口。另外还有两个问题要处理,1. 处于兼容性的考虑,还有支持基于processing time的和基于tuple的窗口;2. 由于数据的无序性,需要如何知道一个窗口内的数据是完整的,什么时候可以发送出去这个window的计算结果。对于第二个问题,之前存在的一个解决方式是通过watermarks来处理,不过存在两个缺陷:1. too fast,即watermakr本身推进太快了,造成一些应该在一个窗口内的数据没有被记入一个窗口中。watermark不能保证100%的数据都来了;2. too slow,可以收到某些因素的影响watermark不能推进,造成比较高的延迟。Dataflow认为仅仅是使用watermark不足以处理这些问题。Dataflow这里引入了Lambda架构中的一些思路,在Lambda架构中,数据被分为流式处理处理和批处理的两个部分。而Dataflow一些思路和Lambda架构类似,这里引入的是tigger机制,
In a nutshell, triggers are a mechanism for stimulating the production of GroupByKeyAndWindow results in response to internal or external signals. They are complementary to the windowing model, in that they each affect system behaviour along a different axis of time:
• Windowing determines where in event time data are grouped together for processing.
• Triggering determines when in processing time the results of groupings are emitted as panes.
按照Paper中这里的说法,Windowing机制决定了按照event time,数据在哪里被groupBy然后被处理,而Tiggering支持决定了按照processing time,数据处理之后的结果什么时候被emit。这里主要有三种模型。paper中以一个小整数的stream处理举例说明了,基本的例子,求这个整数的和。这里实际上等到全部的数据到来之后,才能得出最终的结果。这样latency就会比较高,
PCollection<KV<String, Integer>> output = input.apply(Sum.integersPerKey());
-
Discarding,tigger被触发的时候,窗口内的内容被直接丢弃。下面的例子添加一个周期性触发的tigger,使用discarding模型。这样每次计算的是delta值,即每个tigger触发时和的差异值。
PCollection<KV<String, Integer>> output = input.apply( Window.trigger(Repeat(AtPeriod(1, MINUTE))).discarding()) .apply(Sum.integersPerKey()); -
Accumulating,tigger被触发的时候,窗口内的数据被累积下来可以用于后面的操作。下面的例子添加一个周期性触发的tigger,使用accumulating模型,达到周期性更新和的效果。
PCollection<KV<String, Integer>> output = input.apply( Window.trigger(Repeat(AtPeriod(1, MINUTE))).accumulating()) .apply(Sum.integersPerKey()); -
Accumulating & Retracting,tigger被触发的时候,相比于Accumulating模式,可以直接Retracting/回退操作。这里Paper举了一个复杂一些例子,
PCollection<KV<String, Integer>> output = input .apply(Window.into(Sessions.withGapDuration(1, MINUTE)) .trigger(SequenceOf( RepeatUntil( AtPeriod(1, MINUTE), AtWatermark()), Repeat(AtWatermark()))) .accumulatingAndRetracting()) .apply(Sum.integersPerKey());
跟多的用法可以参看相关书籍。
// more
Lightweight Asynchronous Snapshots for Distributed Dataflows
0x20 核心内容
这里就是描述的Flink使用的异步快照的机制。在网上也能找到不少描述的文章。其基本原理是基于Chandy-Lamport算法。可以看出来Flink通过Lightweight Asynchronous Snapshots来实现Checkpointing,和MillWheel不同。Google得益于其强大的基础架构,可以用更加简单粗暴、有效的方式解决,即利用Bigtable or Spanner。这里的Snapshot被定位一个:global snapshot G∗ = (T∗,E∗),T∗和E∗分别代表了所有的任务和Edge的状态。和前面的DAG不同,这里支持迭代算法,运行图中时可能有环的。在无环图的情况下,这个算法执行的流程如下,
- 一个中心的协调器周期性地向上游的Source中注入stage barriers。当一个Source接受到一个stage barrier的时候,对自身的状态做一个snapshot,然后将这个stage barrier广播到其所有的输出端;
- 当一个非Source的task从其一个input接受到一个stage barrier的时候,立即Block这个input,知道从所有的inputs接受到stage barriers。接受到所有inputs的stage barriers时候,对自身的状态做一个snapshot,然后想起outputs广播stage barrier。其Inputs解除Block,继续进行计算处理。一个完整的global snapshot G∗ = (T∗,E∗) 只会有所有的operator states,即 T∗,而E∗为空。
而对于存在环的情况,如果使用上面的思路,会导致一个类似于死锁的结果。所以在存在环的时候一些情况下不能Block输入。这里会先通过静态分析来确定图中的back-edges,L。这里的back-edges是指在有向图中,在DFS搜索中以及遍历过的边。这样如果将L从图中去除,就可以得到一个DAG,用G(T,E \ L)表示。在这个G中,算法按照前面的方式运行。额外要处理的是在处理snapshot期间,想要对back-edges的接受到的记录进行备份。如下图所示,(c)中将back edge的数据保存到了一个地方,
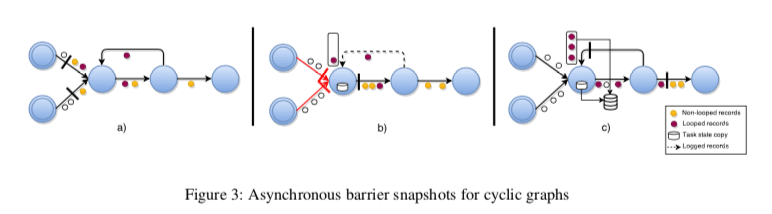
Checkpoint核心的功能就是用于故障恢复。Paper中提出可以有不同的一些故障恢复的模式,一种最简单的思路就是从最后一个 global snapshot开始,重启这个操作。需要,1. 每个任务从持久化存储中恢复这一个snapshot下保存的状态,作为其重启之后的初始状态;2. 从backup logs中恢复,并处理记录;3. 开始处理从其输入channels中输入来的数据。当然还可以有更复杂,效率更好一些的方式。
// more, 对性能影响
Photon: Fault-tolerant and Scalable Joining of Continuous Data Streams
0x30 核心思路
Photon是Google的流式数据上面进行join的思路。在流式数据上面进行分布式的join主要涉及到这样的几个问题,1. 如何将用户行为的信息聚合到一起,这个就是join操作的基本目的;2. 实现exactly-once语义;3. 支持乱序的streams;4. 还有就是总是会说的fault-tolerance,高吞吐和低延迟。流之间的join操作主要涉及到三个组件,dispatcher、EventStore以及joiner,另外的一个核心依赖是一个基于Paxos的IdRegistry。基本执行流程如下,
- dispatcher宗Click Logs中获取Clink事件,通过其click id查询IdRegistry。如果这个IdRegistry已经存在IdRegistry中,则认为这个事件的join操作已经完成,则跳过处理。如果不存在,将这个事件异步发送给joiner,并等待response。joiner失败的情况下会进行重试的操作;
- joiner在接受到事件之后,从其中取出query id。查询EventStore。如果查询没有结果,则返回dispatcher失败信息,dispatcher可以进行重试策略。如果查询有结果,则尝试将clink id注册到IdRegistry。如果clink id已经存在IdRegistry,则认为join操作已经完成。如果没有则向IdRegistry注册这个click id,并向Joined Click Logs中写入结果。
这里存在在注册了click id之后,到写入结果的过程中发送了故障。这个问题出现的原因是:joiner之后在只会在成功将event id(这个例子中和clink id差不多)写入到IdRegistry之后才会将一个event写入到其ouput logs。一旦一个event id被注册到IdRegistry,后面的注册都会失败。但是在写入结果和注册之间没有事务的保证。
- 这种情况出现比较多的情景是IdRegistry操作成功回复joiner的时候,而joiner认为rpc超时了。对于这个问题,Photon采取了一些缓解的方法。在想IdRegistry注册event id的时候,会携带一个全局唯一的token(这个token有joiner server的地址,joiner进程的pid以及timestamp组成。实际上这里的event id也是类似生成的思路,由ServerIP, ProcessID和Timestamp三个部分组成),如果joiner没有在一个设定的timeout时间内收到回复,会以相同的token进行重试操作。这样IdRegistry就可以通过token来区分重试的操作。
- 另外的一种情况是joiner的crash导致的,这里采用的是限制一个joiner进行中的注册event id的请求数量。缓解这种情况。
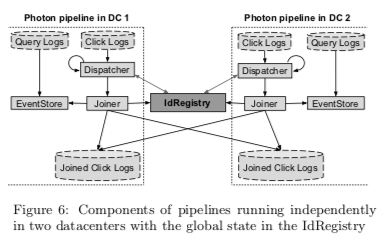
这里的一个核心组件就是IdRegistry了,主要是为了实现exactly-once语义。由于IdRegistry为跨DC,操作的延迟可能比较大,Paper中讨论了比较多的优化方式:1. Server-side Batching,类似于数据库中的group commit,IdRegistry中的一个Paxos Commit也会尝试提交一批的数据,2. Sharding,也是常见的优化方式,根据event id来进行sharding。而且可以根据目前的状态进行自动的调整分区的数据。动态分区是基于timestmap,而这里有利用了Google的TrueTime。3. 定期删除过期的数据。
参考
- MillWheel: Fault-Tolerant Stream Processing at Internet Scale, VLDB ‘13.
- The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing, VLDB ‘15.
- 《Streaming System》, O’Reilly Media.
- Lightweight Asynchronous Snapshots for Distributed Dataflows, arXiv.
- Photon: Fault-tolerant and Scalable Joining of Continuous Data Streams, SIGMOD ‘13.
