An End-to-End Automatic Cloud Database Tuning System Using Deep Reinforcement Learning
0x00 核心内容
这篇Paper总体很长,但是又具体关于如何利用Deep Reinforcement Learning来进行数据调优的内容只有很少的一点。只是基本讲了利用Reinforcement Learning中的其中一种Deep deterministic policy gradient (DDPG)来进行自动化数据库调优的思路。在环境E下面的t时刻,tuning agent可以获取到一些数据内部的metrics,计为s_t。然后产生一个knobs集合的值,就是一个对性能影响比较明显的集合,其中的参数对应到一个值。根据这个参数调整数据库,然后根据数据的性能表现得到一个奖励,计为r_t。DDPG结合了DQN和actor-critic,这些在网上和相关书籍可以找到很多的接受,Paper中也花了很大的篇幅去介绍,23333。actor-critic中actor的policy function和critic function如下,
\(a_t = \mu(s_t|\theta^Q), \\ Q(s_t,a_t|\theta^Q).\\\)
然后就是Q(s,a),得出下面的式子,
\(Q^u(s, a) = E_{r_t,s_{t+1}∼E}[r(s_t, a_t), γQ^\mu(s_{t+1}, \mu(s_{t+1}))]\\\)
μ(s)为policy,s_{t+1}为下一个状态,r_t =r(s_t,a_t)为奖励函数,γ为折扣因子(discount factor)。之后变成了这样的一个数值优化问题,
\(\min L(\theta^Q)=E[(Q(s, a|\theta^Q)-y)^2], \\ where\ y=r(s_t, a_t)+γQ^\mu(s_{t+1}, \mu(s_{t+1}|\theta^Q).\\\)
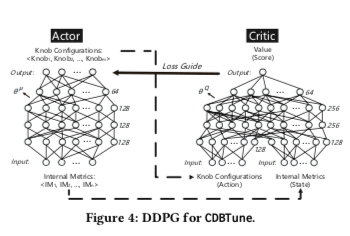
然后还提了奖励函数,这里的r有延迟和吞吐两方面的建立组成。这两个步伐的奖励函数都是根据调整前后的性能变化值和之前的值的比得到。 \(r = \left\{ \begin{array}{ll} ((1+\Delta_{t\rarr0})^2-1)|1+\Delta_{t\rarr t-1}|,& \Delta{t\rarr0}>0, \\ -((1+\Delta_{t\rarr0})^2-1)|1-\Delta_{t\rarr t-1}|,& \Delta{t\rarr0}\leq 0, \end{array} \right. \\\) 最终的r为吞吐和延迟的一个加比例系数的和, \(r = C_T \cdot r_t + C_L\cdot r_L.\\\) // More…
QTune: A Query-Aware Database Tuning System with Deep Reinforcement Learning
0x10 核心内容
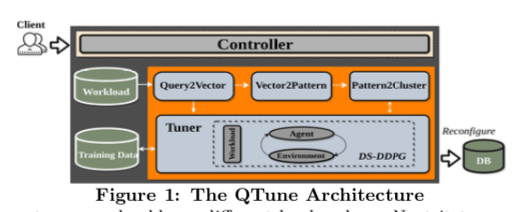
这篇Paper也是一篇关于利用Deep Reinforcement Learning来自动化调优数据库的文章。不过这篇Paper里面讲到实际有价值的内容远比前面的一篇要多。这里提出的主要的方法就是利用Double-State Deep Deterministic Policy Gradient (DS-DDPG)模型,Double-State这里主要是既利用数据的状态,有利用了query的信息。且提供了从query-level,workload-level到cluster-level粒度的调优。Qtune的基本架构如下,客户端通过和Controller交互来发送调优请求。Query2Vector组负责将查找转化为一个vector来表示,有点word2vec的意味。Query2Vector将查询转化为Vector的时候,会利用上数据的查询计划和优化器的信息。Tuner负责设置一个合适的knobs集合的值,数据库在这个配置下面运行。另外Vector2Pattern组件为优化Tuner生成配置信息时候的性能,通过使用一种deep learning model来产生配置的值,也指导Tuner如何改变之前配置的值。Pattern2Cluster负责将查询聚类/分类。
0x11 Query Featurization
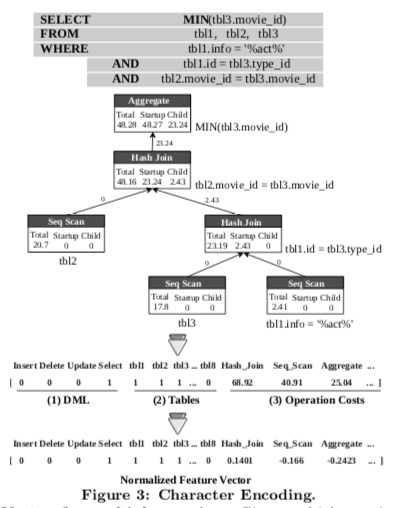
Query Featurization的主要内容就是如何将一个查询用vector/向量来表示。表示这个查询的向量里面要包含这个查询的信息,比如使用到那些tables。另外就是查找的query cost,来自数据库,比如select和join操作的成本。
- 使用4+|T|的方式将查询信息编码为vector,其中4为查询的类型(insert, select, update, delete)。给使用一个标量表示,如果为对应的类型,则对应的标量为1。|T|为参与到tables,参与了的对应的值设置为1。这里编码的时候将查询的字段信息、以及操作信息(比如select的条件信息)编码进去。
- 使用一个|P|长度的vector编码数据库操作(scan, hash join, aggregate)的成本信息。以PostgreSQL的例子,数据库中有38个这样的操作。在查询计划中,操作出现在这个计划树的不同位置,在这里编码这个vector的时候要考虑到由于这个位置不同带来的实际的操作成本的差异;
- 一个简单的查询就是将上面的vector拼接在一起。对于多个查询信息,前面关于参与到的tables的信息就是单个查询的与操作,后面成本信息为和操作计算而来的vector。
一个例子如下图所示,
0x12 Knob Tuning
这节是Qtune的核心内容,涉及到具体调优的算法。总提的模型如下图,Agent也是一种Actor-Critic方法。这个强化学习的模型中的概念映射到Qtune这个调优数据库的情景下面,如下表,
| DS-DDPG | The tuning problem |
|---|---|
| Environment | Database being tuned |
| Inner state | Database knobs (e.g., work mem) |
| Outer metrics | State statistics (e.g., updated tuples) |
| Action | Tuning database knobs |
| Reward | Database performance changes |
| Agent | The Actor-Critic networks |
| Predictor | A neural network for predicting metrics |
| Actor | A neural network for making actions |
| Critic | A neural network for evaluating Actor |
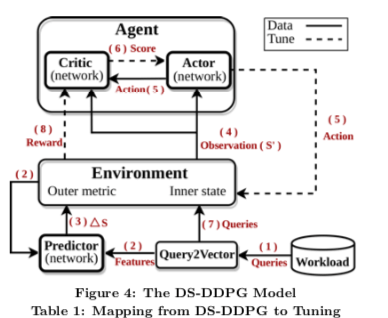
训练这个模型主要涉及到三个部分,Predictor,Actor和Critic,
-
Predictor为一个多层感知机的模型。Predictor用于预测在一个配置下面,数据库执行查询的时候,其metrics是否会改变。训练数据为T_P = {⟨v, S, I, ∆S⟩},v为表示查询的vector,S为输出的metrics,I为数据库内部状态, ∆S为metrics的变化信息。S、I从先数据库中获取,在执行了查找时候去获取∆S的信息。序列的目标是最小化一个error function。基本的算法如下,

-
序列 Actor-Critic模型。这里对于一个workload,会随机挑选其中的一个查询的子集,然后通过Query2Vector将查询转化为vector,再通过Predictor预测数据库的metrics,计为S1′ 。通过Actor将其应用到数据库,这个时候通过一个奖励函数得到一个奖励R1。这样得到一个数据库新的metrcis信息更新S1’,得到S2’。重复这样的步骤。基本的算法如下,这里还有更多的细节[2],

-
奖励函数,这里的奖励函数和前面的CBTune思路一致。不过处理比前面的CBTune更加精细一些,在每个metric的力度上面给出一个奖励。单个r的计算和CBTune一致,最终的奖励为metrics奖励值的和, \(r = \left\{ \begin{array}{ll} ((1+\Delta_{t\rarr0})^2-1)|1+\Delta_{t\rarr t-1}|,& \Delta{t\rarr0}>0, \\ -((1+\Delta_{t\rarr0})^2-1)|1-\Delta_{t\rarr t-1}|,& \Delta{t\rarr0}\leq 0, \end{array} \right. \\\)
然后总的训练思路就是这样啦,
Input: Q: a query set {q1, q2, · · · , q|Q|}
Output: Action A
1 V = Query2Vector(Q);
2 ∆S = Predictor(V );
3 S = Enviorment();
4 A = Actor(S′ = S + ∆S);
5 Deploy A;
6 Run Q;
0x13 Query Clustering
Paper中提到如果workload中同时包含了事务查询和分析类型的查找。如果倾向于提高吞吐,推荐使用query-level的调优方式。如果倾向于降低延迟,推荐使用workload-level的调优方式。对应单独的分析类型的workload,推荐使用cluster-level的调优方式来平衡吞吐和延迟。对cluster-level的调优,这里的两个问题就是,1. 如果对于每个查询找到合适configuration pattern,2. 如何根据configuration pattern,对查询进行聚类。
-
Configuration Pattern,由于直接产生一个konbs集合的值成本很好,这里选择给出值变化的方法。对于每个konb,给出一个在{-1,0,+1}中的值,
... we discretize the continuous values into discretized values. For example, we can discretize each knob into {-1,0,+1}. Specifically, for each knob, if the tuned knob value is around the default value, we set it as 0; 1 if the esti- mated value is much larger than the default value; -1 if the estimated value is much smaller than the default value.另外,通过只选择被DS-DDPG频繁调优的knobs,避免维度爆炸。具体推荐Configuration Pattern的时候,使用一个5层的网络模型。
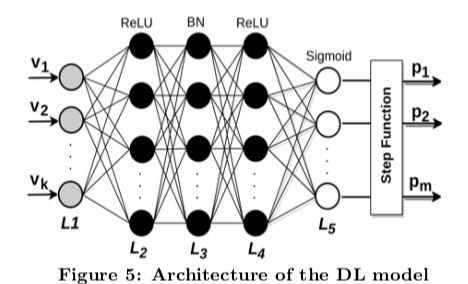
* The input layer takes the feature vector as input and maps it to the target knob space, in order to make the input and output in the same scale. * The second layer is designed to explore the configuration patterns. It is a dense layer with ReLU as the activation function (y = max(x,0), where x is an input feature and y is the corresponding output features, * The third layer is a BatchNormal layer. It normalizes the input vector in favor of gaining discretized results. * The fourth layer has the same function as the second and the value of each feature in this layer’s output vector ranges from 0 to 1. But different from Predictor, the last layer uses a sigmoid activation function最终的结果如果得到到y小于0.5,则为-1,0.5则为0,大于0.5则为1。
-
Query Clustering,简单的根据Configuration Pattern的相似性进行分类。Paper中就是直接使用DBSCAN算法。
0x14 评估
具体的内容可以参看[2].
参考
- An End-to-End Automatic Cloud Database Tuning System Using Deep Reinforcement Learning, SIGMOD ‘19.
- QTune: A Query-Aware Database Tuning System with Deep Reinforcement Learning, VLDB ‘19.
