AnalyticDB: Real-time OLAP Database System at Alibaba Cloud
0x00 引言
这篇Paper是阿里在VLDB ’19上面发表的关于其Real-time OLAP数据系统AnalyticDB的一篇。因为这篇Paper是国内的有名的企业发表的Paper,相关的产品也在阿里云上面有提供,相关的资料还是很丰富。无论是网上的信息还是这篇paper中,都好吃AnalyticDB实现了非常nubility的效果。这篇Paper讲的很“概要”吧。
... It is capable of holding 100 trillion rows of records, i.e., 10PB+ in size. At the same time, it is able to serve 10m+ writes and 100k+ queries per second, while completing complex queries within hundreds of milliseconds.
0x01 基本架构
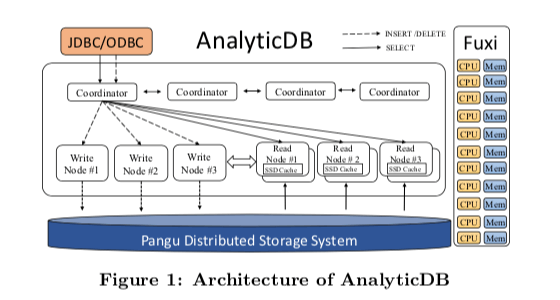
AnalyticDB的基本架构如下。和很多基础架构完善的公司一样,AnalyticDB也是构建在其它的基础服务至上的,这个是和很多的开源的系统的一个很大的区别,开源的系统一般就只能依赖于其它的开源系统 or 基本的操作系统环境。和下面的Procella相比,AnalyticDB的基本架构看上去要简单一些,Coondinator负责处理用户过来的请求,并将这些请求发送给对应的后面的写入/读取节点。这里设计的一个特点是写入和读取的节点是分离的。数据实际保存早Pangu分布式文件系统上面,集群管理使用自己的系统。
对于超大型的表,分区是必然的选择。很多的开源的类似的系统也提高了在建表的时候就指定分区的方式。这里也是类型的方式,AnalyticDB支持两层的分表方式。下面的DDL使用主键的hash作为一级分区方式。二级的subpartition使用时间的方式,可以将同一天 or 同一个周 or 同一年的数据放在同一个subpartition里面,支持指定最大的分区数量,在超过了这个指定的数量之后最老的会被舍弃。
CREATE TABLE db_name.table_name (
id int,
city varchar,
dob date,
primary key (id)
)
PARTITION BY HASH KEY(id)
PARTITION NUM 50
SUBPARTITION BY LIST (dob)
SUBPARTITION OPTIONS (available_partition_num = 12);
AnalyticDB采用读写分离的架构。Paper中的观点是这样的方式能够降低读写操作的冲突,提高性能。在[2]中的对应章节上面有一个表示读写节点启作用的不同组件的图。一个时间内,一个节点被选为写节点,读写节点之间只用zookpper来通信协调。
-
Coordinator会决定数据如何分区,并负责根据SQL识别这个是写请求还是读请求,并将对应的请求发送到对应的节点上面。写节点在接受到请求之后,将接受到的SQL statements保存到内存的buffer之中,并周期性地将其刷入盘古分布式文件系统。在写入完成之后,会返回一个LSN给Coordinators。在盘古上面的数据达到一定量的时候,AnalyticDB启动一个MapReduce任务,将写节点保存的log数据转换为实际的数据和索引。
- 这样的话可以发现,这里从写入到最终能把读节点读取到会存在不少的时间差。这里AnalyticDB引入了一个Real-time Read方式。读节点初始化的时候从盘古存储系统中拉去数据,在后面运行的时候从写节点中拉去log buffer。读节点在本地重放这些log,这些重放的结构不会写入到盘古中。这样这里的写节点起到了一个类似Cache的角色。这这样的工作方式下吗,AnalyticDB将读取分为real-time读取和bounded- staleness读取。前者可以在写入之后立即读取,而后者会存在一个延迟。
- 为了实现real-time的读取,这里使用的方式是version verification机制,每个primary partition的写入节点会分配一个版本信息,当一些的写入请求被刷入盘古中的时候,写入节点递增这个版本号,并将这个信息返回到Coordinators。在查询的时候,带上这个版本信息。在读节点处理的时候,比较本地保存的版本信息和请求带上的版本信息,如果本地的版本信息更小,则向写入节点拉去数据,更新本地的数据。
0x02 存储
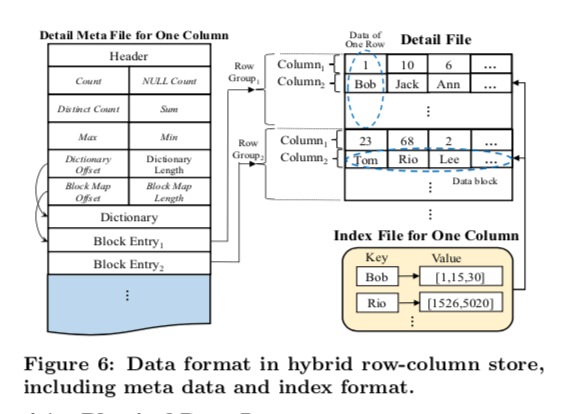
AnalyticDB数据保存使用一种行列混合的方式。处理支持基本的类型之外,还支持入json,vector这样的复杂类型。保存的数据分为Meta文件和Detail文件,前者主要保存的就是一些元数据。数据被按一定数量行分成一组,这里可以看作是按照行来保存的,在这一组被,不同的列被保存到一起,放在单独的block中。这种方式对于简单类似的数据保存不错,对于json这样的复杂类似,这里使用了另外的一种方式。一个DataBlock里面不保存实际的数据,而是保存指向另外的称之为FBlock的的信息,一个FBlock的大小固定为32KB。每个DataBlock里面的行的数据依然是固定的,而所有的FBlock被保存到另外的一个单独的文件之中。
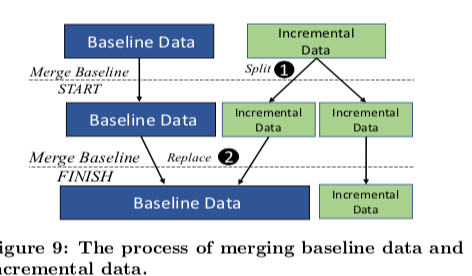
在数据管理上面,AnalyticDB这里使用的是基线数和和增量数据的方式。前者是之前的数据,保存索引和实际的数据,而后者为最近添加的数据,只包含了数据本身。而删除操作也不会立即就执行实际的删除行为,而是将删除的信息添加到一个Delete Bitset中。而Update操作,在AnalyticDB执行的是Delete + Insert操作的组合。在执行查询操作的时候,会同时查询基线数据和增量数据,并将这两个地方的数据合并,合并之后还要减去已经删除的数据,得到最终的结果。执行Insert操作的基本逻辑如下,
Input: SQL statement and version number
/* parse multiple column values from SQL
values = parse(SQL);
/* append values to tail of incremental data
row id = incremental data.append(values);
/* add a new bit to the delete bitset
delete bitset[row id] = 0;
/* create a snapshot of delete bitset
delete bitset snap = create snapshot(delete bitset);
/* put a version-snapshot pair into the map */ snap map.put(version, delete bitset snap);
在增量数据达到一定量的时候,会启动一个MapReduce任务来合并基线数据和增量数据。增量切换到一个新的,如何将之前的基线数据,增量数据和删除信息合并为新的基线数据。
在索引的设计上面,这里没有涉及到很细节的东西。只是说这里传统数据的索引不合适AnalyticDB面临的环境。AnalyticDB默认对所有的列建立索引,如何key就是列的值信息,value为这个值出现的数据的所有的行号。
0x03 查询
主要涉及到几点的内容,
- Storage-Aware Plan Optimization,主要就是一些计算下推和其数据保存方式的一些优化。
- 一个Real-time的采样器。
- 执行引擎基于DGA的执行方式。也利用了一个代码生成的计数。将SQL编译为机器码,并利用avx512之类的指令集优化性能。
TODO
0x04 评估
这里的具体信息可以参看[1].
Procella: Unifying serving and analytical data at YouTube
0x10 引言
这篇Paper是关于YouTube/Google的一个OLAP的系统。Google的这类系统挺多的,为了避免说Procella有重复造了一个轮子和突出Procella的一些优化,这里提出了一些Procella要满足的要求,1. Reporting and dashboarding,2. Reporting and dashboarding,3. Monitoring以及4. Ad-hoc analysis。而现在的系统都不能很好的满足上面的这些要求。
0x11 基本架构
和上面的AnalyticDB一样,Procella其存储也是用了一个分布式文件系统,对于Google当然就是大名鼎鼎的Colossus。估计集群调度用的也是Google的Borg系统,在图中没有表现出来。从基本的架构上来看,Procella的组件要要比AnalyticDB多少不少,复杂了一些。在Procella中,客户端连接到RS,向其发送SQL查询请求,RS执行解析SQL、查询重写以及形成查询计划并执行查询优化操作。为了执行上面的操作,RS依赖于从MDS中获取的Schema、分区和索引的信息。RS的查询计划生产是一个复杂的操作。数据处理有DS负责处理,一个DS可能接受到一个查询操作的部分计划。这个请求可能来自RS,也可能来自其它的DS。这里除了常见的保存到Colossus的数据之外,还利用了RDMA来实现Remote RDMA,加速性能。
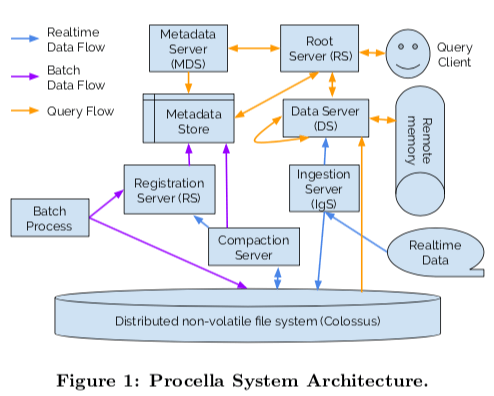
- Procella的数据保存在Colossus上面。数据以table的逻辑保存,同样被分区为不同的partition or tablet。使用一种列格式文件保存数据。
- 同样的,Percella也没有使用Btree的索引。而是实现了另外的更加轻量级的索引结果。比如zone map、bitmap和bloom filters,partition, sort keys 之类的。这些数据信息由MDS来处理,直接说保存到Metadata Store中,这个Metadata Store可以基于Bigtable or Spanner。DDL的SQL 语句由registration server (RgS)来处理,其数据同样保存在metadata store中。
- Batch ingestion为通过类似于MapReduce这样的批处理服务倒入数据。而ingestion server (IgS)为运行的时候实时的向系统中写入数据。在接受到写入请求的时候IgS组织数据为符合表结果的格式,以WAL的形式写入到Colossus中。同时并发地根据分区的情况将这些数据发送到对应的DS。DS中的
- 数据暂时Buffer在内存之中。以WAL的形式写入到Colossus中的数据会周期性地被compaction任务处理。
- Compaction操作就是将WAL数据转化为一般表结构数据的操作。和前面的AnalyticDB类似。不过这里将地这么麻烦干什么。这里在Compaction的时候还可以执行一些SQL的逻辑,可以取出一些可以必须要的数据,减少数据的大小。
Percella的基本架构部分Paper就是这些,后面更大的一部分都是关于优化的。¯\(ツ)/¯。
0x12 优化
Percella讲如何优化的这里话来比较大的篇幅。主要涉及到多个方面的优化。挺多的,2333。
- 缓存,缓存是很常用的优化手段。这里缓存的类似也很多。1. Colossus Metadata缓存,主要就是缓存这个分布式文件系统的一些元数据,避免访问一些Collosus的name serevr的访问。2. Header缓存,这里主要的Columnar文件的元数据,包含了起始offset的信息,Column Size一个最大最小值等信息。3. Data缓存,Percella使用的数据格式Artus可以实现内存和磁盘上面的系统的数据表示,这样方便了将数据缓存到内存中。4. Metadata缓存,MDS将数据保存到metadata store中,同时也缓存到本地。5. Affinity调度,将DS和MDS更加可能地服务于同一部分的数据,提高缓存命中率。
- 数据格式,Artus是Percella使用的新的数据格式,更好地支持快速的lookup和范围扫描。1. Artus使用custom encodings,可以不用使用压缩的方式,避免查找少量数据的时候解压缩带来的开销。但是这里具体如何做没有讲。2. 使用multi-pass的自适应编码方式,通过一些统计信息决定使用一种最好的编码方式。3. 实现一种可以进行二分查找的编码。比如run-length-encoded columns。还有其它的一些编码优化方式[3]。这里讲了很多,但是确实很多有用的细节。也许可以查查相关的资料看看。
- 同样地,Percella也使用了讲SQL编译为机器吗的方式。并针对Cache的特点,和现代CPU SIMD处理的特点进行优化。还利用C++模版元编程的方式进行优化。在代码生成的时候也进行了一些操作的融合,这个在一些查询编译器中也有相同的思路。但是这里怎么做是个更大的问题。
- 分布式操作优化。分布式join优化,1. 对于少量的数据,使用广播的方式,比如国家和日期等。这类型的数据不会很大。2. Co-partitioned,根据parition key讲数据分区到一起。3. 在数据量大有没有Co-partitioned的时候,执行shuffer操作,将数据shuffle到一些中间服务器上面操作。4. 流水线操作。5. 在根据join key分区的一个大的table,和一个根据join 可以分区的table进行join操作的时候,可以直接向join key分区的table数据对应的DS发送RPC请求获取数据的方式。
- 尾延迟优化,这里的主要思路是,1. 在一个操作明显超出了一般的时间后,发送另外一个请求到另外的一个副本进行操作。2. 限制DS的并发请求量。3. 根据数据量大小,将请求分开处理。小数据量的请求优先级更高。
- 查询优化,Data Ingestion,Serving Embedded Statistics。TODO
这两篇Paper的感觉就是写了很多,但是。。。(´・_・`)。
0x13 评估
这里的具体信息可以参看[3].
参考
- AnalyticDB: Real-time OLAP Database System at Alibaba Cloud, VLDB ‘19.
- https://developer.aliyun.com/article/716501
- Procella: Unifying serving and analytical data at YouTube, VLDB ‘19.
