SplitFS: Reducing Software Overhead in File Systems for Persistent Memory
0x00 核心内容
这篇Paper是将要发表在SOSP ‘19上面的,关于NVMM上面文件系统设计的一篇文章。其核心思路是通过kernel的模块来管理一般的元数据,而数据不同的管理在用户空间完成。因为NVVM load/store操作只在8-byte的粒度上面能过保证原子性。这个给一些操作,特别是覆盖写操作带来了不少的麻烦,所以之前的一些文件采取的是Log-Stuctured的思路,比如NOVA。为了处理这个问题,提出了一个先写入数据然后在relink的思路。SplitFS的基本结构如下。读写操作被转为为在一个内存映射文件上面的load/store操作。Append操作会写将数据写到一个staging文件,然后在fsync的时候通过relink操作“提交”操作。一般的元数据管理在内核层面完成。
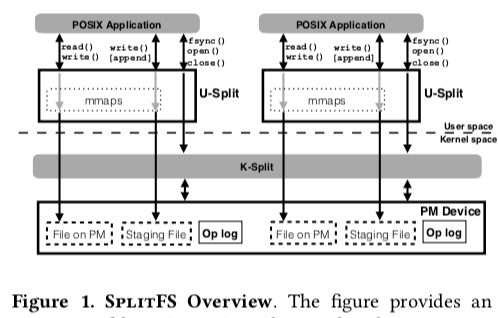
读操作和覆盖写操作使用mmap文件以大约2MB的粒度处理。读操作直接使用memcpy,而写通过non-temporal stores指令完成。SplitFS中,一个逻辑文件的数据可能保存在多个实际的文件中。比如append的文件会先写入staging文件中,这样数据就在staging文件中有,原来的文件中也有。这里通过多个的mmap操作完成文件映射。这里的操作要提一下SplitFS提供了不同的crash-consistency/崩溃一致性的保证:
- POSIX mode。POSIX mode中,SplitFS提供元数据一致性。这种Mode下面,覆盖写操作直接使用同步in-place更新。但是append则不是同步的,想要fsync来保证持久化,且SplitFS保证append操作原子性。但是和POSIX语义不同的一点就是一个文件被访问 or 更新,其元数据不一定立即能过反映处理。这里看起来覆盖写也是不保证原子性的,和一般文件系统覆盖写不保证原子性的区别的地方是,一般的部分写入为Block粒度,而这里应该是8-byte粒度。
- Sync mode。Sync mode为在POSIX Model上面,增加不需要fsync操作的保证而来。这种Mode下面一些操作的原子性不能保证。
- Strict mode。在Sync Mode上面,保证操作的原子性。这里的原子性只能保证单个syscall操作的原子性。
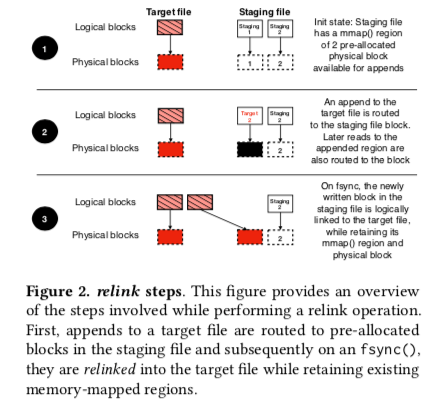
下面是SplitFS操作的基本思路。Append操作和Strict Mode下面的覆盖写操作都是先将数据写到一个staging文件,然后通过relink操作完成最终的写入操作。这里为了避免在relink操作的时候,使用将原来的数据拷贝一份的方式,提出了一个操作relink(file1, offset1, file2, offset2, size)。这里只会涉及到文件元数据的操作。Strict Mode下面,为了保证所有操作的原子性,这里使用了一个Operation Log/OpLog。这里OpLog涉及到一些优化主要就是然后将水clflush操作。
Unix系统中的fork和execve操作给SplitFS的实现也带来了一些麻烦。execve操作由于要求原来的文件描述符可以访问,这里的处理方式是先将相关的数据拷贝到/dev/shm下面的一个文件,以PID命名。execve执行之后在拷贝回来。
// More…
File Systems Unfit as Distributed Storage Backends: Lessons from 10 Years of Ceph Evolution
0x10 核心内容
这篇Paper将的是Ceph 10年以来的一些优化。就立面提到的内容而言,由于Ceph目前已经是一个广泛被使用的分布式存储系统,这些内容已经在Ceph的相关资料中提到了。这个相当于一个官方的总结。这里核心的内容就是亮点,1. 数据的存储如何利用到现在的高速存储硬件设备 or 一些特别类型的存储设置, 比如SMR HDD。Ceph通过一个直接操作裸盘的BlueStore来优化。;2. 如何优化元数据处理的性能,这里使用RocksDB来管理元数据。BlueStore之前直接在本地文件系统上面实现的FileStore存在一下的一些问题,
- 实现有效率的事务很难。一种方法是利用文件系统内部的事务,不过这样的话对文件系统存在很多的假设。另外一种的方法是在用户空间实现WAL,这样的主要有三个问题,1. Read-Modify-Writeb比较慢,2. 操作不幂等,3. Double Writes,写日志和写实际的数据会导致两次写入。
- 快速的元数据操作,主要就是本地文件系统目录操作等的一些性能问题。
- 支持新硬件,比如host-managed SMR磁盘,OpenChannel SSD(可以直接管理FTL)。直接在本地文件系统上面实现的话,由于文件系统的存储,利用这些新硬件的特点比较麻烦。
然后就是解决这些问题的方案啦,就是BlueStore,
-
BlueFS,BlueStore将元数据保存到RocksDB上面。由于RocksDB运行依赖于一些文件系统接口。Ceph就在BlueStore的基础上面实现了一个BuleFS。由于只需要满足RocksDB运行的一些想要,BlueFS是一个很简单的文件系统。一个可能的BlueFS的基本结构如下图,
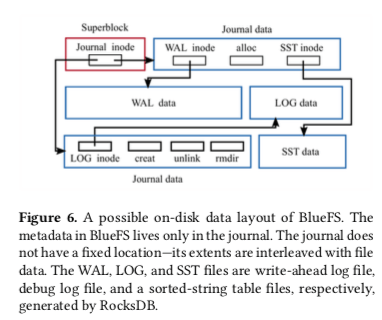
- 将元数据保存到RocksDB上面时,不同类型的元数据通过不同namespace分开。这里实际上就是简单的在key前面加字符而已。比如字符O + object的表示对象元信息。Block分配的信息保存在B namespace,collection元信息保存在C namespace。比如key为C12.e4-6表示在pool 12中,最高的6bit的hash值为e4的信息。这样,对象O12.e532就在这个pool中,而对象O12.e832就不再这个pool中。通过这个方法将objects划分到不同的集合,方便rebalance等的操作。
- BuleStore使用copy-on-write方式。对于大于64 KiB(HDD),16KiB(SSD)的数据,会写入到新分配的空间。而小于这个阈值的会直接保存到RocksDB。一种常见的小对象优化。另外,Clone操作就是直接增加引用计数。
- 空间分配。使用FreeList来管理空闲的空间,这个FreeList会持久化到RocksDB中。第一个版本的实现通过key-value pairs with offset and length的方式,第二个版本是基于bitmap。第二中的优化,是分配中涉及到一些操作对顺序要求更低,这样有利于提高性能。Allocator来进行实际的分配操作,使用FreeList的信息。第一个基于extent,将空间拆分为power-of-two-sized的方式处理,不过存在碎片的问题。第二个版本使用层次化索引的方式(a hierarchy of indexes layered on top of a single-bit-per-block representation to track whole regions of blocks. )。这里具体的细节Paper中没用提高,不过可以找到相关的资料。
- Cache。一个基于2Q缓存替换算法的用户空间的write-through cache。
另外的一些优化方式,和前面的内容一样,只是提到的一些思路,没有提到具体的细节内容,
- 根据实际的IO情况选择合适的checksum block大小。避免设置一个比较小的block带来的checksum过多的问题;
- 覆盖写EC数据的问题。使用EC方式保存的数据之前都支持append和delete操作。为了解决这个问题,BlueStore使用一种2PC的方式。先将原来相关的chunk拷贝一份,在写入新的数据处理好之后在删除。
- 透明压缩。这里谈到了部分覆盖写的问题。BlueStore会先将新数据写入到另外的一个位置,然后更改元数据。在由于覆盖写造成的碎片比较多的时候,在将这些数据读出来,合并操作之后在压缩写入。
- 使用新接口。主要就是类似host-managed SMR,ZNS SSDs 和 KV SSDs之类硬件相关的一些优化操作。
// More…
0x11 评估
这里的具体信息可以参看[2].
参考
- SplitFS: Reducing Software Overhead in File Systems for Persistent Memory, SOSP ‘19.
- File Systems Unfit as Distributed Storage Backends: Lessons from 10 Years of Ceph Evolution, SOSP ‘19.
