ffsck: The Fast File System Checker
0x00 引言
ffsck是一个很有意思的File System Checker实现,通过比较小的改动就实现了非常好的性能提升。像ext2这样的非日志式的文件系统,难免在系统长时间运行之后由于某些异常情况产生数据/元数据不一致的情况,fsck用于发现系统中的这样的一些问题。日志式的文件系统一般情况下fsck的检查会简单一些,但是强制全部检查的话还是会耗费比较长的时间。以e2fsck为例子,e2fsck的检查过程分为这样的几个步骤,
- Superblock,超级快检查。一般检查的是文件系统大小,inode数量,空闲block以及空闲inode数量等。一般前面两个数值的检查能以确认其是否精确,只会大概判断是不是在一个正常的区间;
- Group Descriptor,Group Descriptor检查。Group Descriptor的设计来自于80年代的Unix Fast File System的设计,将磁盘磁道划分为不同的,每组里面包含bitmap之类的信息和数据block。这里会检查空闲的block是不是实际上被使用了,没有被标记为空闲的实际上没有被使用;
- Directory,检查一些这里保存inode是否是正常使用状态的,以及inode number的范围是不是在一个合理的范围;
- Inode,检查inode的类似和分配状态是否是一个正确的状态,以及其引用数是否正确。另外检查inode中指向的数据块号是否合法以及没有被其它的inode引用;
- Indirect Block,Indirect Block是inode用来寻址Data Block的block,fsck同样会检查在Indirect Block保存的block有没有被其它的inode引用,并inode number是合法的。
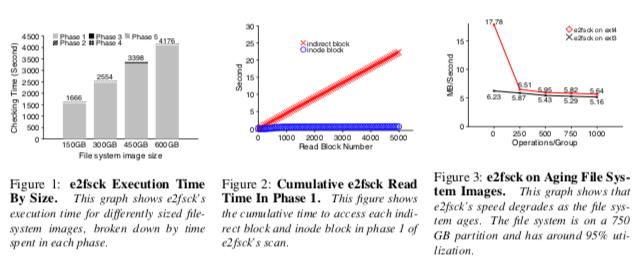
ffsck先是做了一个性能分析,发现fsck的大部分时间都花在了扫描inode和其对应的Indirect Block上面,而且在文件大小增大的情况下这个现象会变得更加明显。ffsck分析认为,ext2、3中Indirect Block和Data Block使用同样的分配策略,分配也都分配在同样的地方。这样的一个设计缺点是可能导致Indirect Block发布在磁盘的分散的地方,在文件系统“老化”的情况下这个会变得更严重。另外一个原因是ext3文件系统中,Indirect Block组成的是一个类似树形的结构,这样访问更低层的Block需要顺序访问树更高层的Block,在前一个原因下面,会造成比较差的数据局部性,
1. First, ext3 uses the same allocation strategies for data blocks and indirect blocks, storing them in a contiguous fashion to facilitate sequential access. However, this design causes indirect blocks to be scattered throughout the disk, growing increasingly further apart as the file system ages.
2. Second, ext3 relies on a tree structure to locate all of the indirect blocks, imposing a strict ordering of accesses when checking a file.
0x01 基本思路
在定位问题之后,ffsck的改进思路其实比较简单。ffsck的基本思路是修改ext3文件系统的layout,将Indirect Block的分配划到一个单独的地方。ffsck在这个Indirect Region放到了Inode Table的后面,前面、后面的结构和ext3的保持一致。对于需要动态分配的元数据,比如indirect block和directory data blocks,总是尽量地从Indirect Region中分配。这样的设计带来这样的一些好处:Indirect 更加靠近前面的元数据,在访问inode之后访问Indirect Block有更加好的数据局部性;另外这样的话Indirect Block是放到一块的,访问Indirect Block的树形结构的时候,就可以在靠近的地方找到下层的Indirect Block;还有就是找到Indirect Block之后的操作一般就是根据Indirect Block去获取Data Block,这样Indirect Region在前面的策略也是的访问更加“顺序”,提高访问性能;还有一个好处就是Indirect Block总是在一个比较小的区域,不会随着文件系统的老化而变得分散。这个Indirect Region不用很大,在Paper中设置的是2 MB。
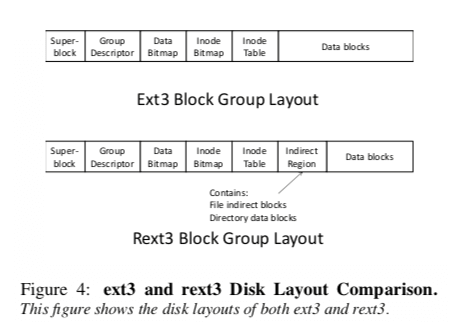
在进行检查的时候,ffsck会通过顺序的操作将文件系统的元数据读取到内存中。对于superblock, block descriptors, inodes, data bitmap, 和 inode bitmap这样的在磁盘固定位置的结构,直接读取就可以了。对于indirect region和directory data blocks是动态的,由于其一般是在Indirect Region中分配,则通过直接读取Indirect Region来获取。另外在实现上,为了避免对ext3文件系统的大的改动,Indirect Region可以就行Data Blocks中划分出来,同时将对应的Blocks在data bitmap中标记为以及使用就可以了,就类似于一个特殊的占用。不会影响到ext3缘由的结构。
0x02 评估
这里的具体信息可以参考[1].
IRON File Systems
0x10 基本思路
这篇Paper主要讨论的是文件系统对待磁盘可靠性的方式,并由此引出来的一些设计。很多文件系统设计的时候假设磁盘是可靠的,而实际上磁盘错误经常发生,由此这篇Paper提出来failure-policy fin gerprint框架,来衡量在磁盘故障情况下面的可靠性。这里将文件系统处理磁盘故障的这种能力称之为 Internal RObustNess (IRON),主要包含故障探测和故障修复相关的技术。磁盘的故障可能可能出现各种各样的错误,这里归类为这样的几种类型,Entire disk failure、Block failure和Block corruption。有些故障时永久的,有些故障时暂时的。Paper中利用Levle来衡量文件系统处理硬件故障的能力,
- 在故障探测方面,分为,1. Zero,不进行故障探测,认为磁盘等硬件时完全可靠的;2. ErrorCode,探测错误并返回一个错误码;3. Sanity,这种Level下面不仅仅能够探测到错误,还能检查文件系统的结构是否是consistent的,类似于fsck做的一些工作;4. Redundancy,进一步的可以利用ECC or 副本等机制来处理block故障的问题。故障探测操作的策略上面,这里范围这样的一些类型,1. lazily,在block被访问到的时候才进行检查,2. eagerly,直接进行全盘扫描检查。
- 在故障恢复方面,这里也分了几个Level,1. Zero,这个Level下面完全没有故障恢复的逻辑,甚至是没有通知客户端有故障的机制;2. Propagate,将错误信息传达给文件系统层,文件系统给应用返回错误信息;3. Stop,停止文件系统目前的工作,这样可以将错误变成一个fail stop错误,避免带来可能的更大的故障;4. Guess,一个block错误发生的时候可以让系统继续运行;5. Retry,重试操作,处理临时错误的时候有一些效果;6. Repair,对一些非一致的情况有修复的能力;7. Remap,在写一个block发生错误的时候,可以remap到其它的block。但是处理不了read的错误;8. Redundancy,副本机制,包括RAID等方式。
另外Paper中讨论了RAID对可靠性的影响,但是RAID也有很多的局限性,比如,1. 很多机器只有一个磁盘,常见的PC就是如此;2. 在磁盘之上的错误无法处理,比如在从磁盘读取处理到应用的过程中的错误;3. RAID系统也不是能够处理所有类型的错误等。
0x11 例子
Paper利用Fault Injection的方式测试了当时常见的一些文件系统,比如ext3、ReiserFS、JFS和NTFS等。总结处理这些文件系统在处理故障时候的一些特点,
-
ext3文件系统处理读取错误的时候会返回错误码,但是写入的时候发生错误很多时候直接忽略了。另外ext3也使用了一些检查的操作,比如superblock和journal blocks,但是很多block没有检查的机制。在恢复处理方面,ext3大部分的处理方式就是传达给应用。读取发生错误的时候会停止journal处理,通常导致的结果是以read only的方式重新挂载。从少数情况下读取错误会重试,比如预取错误的时候会重试读取原来请求的块。Paper中总结了ext3文件系统存在的一些问题,
* First, errors are not always propagated to the user (e.g., truncate and rmdir fail silently). * Second, there are important cases when ext3 does not immediately abort the journal on failure (i.e., does not implement RStop)... * Third, ext3 does not always perform sanity checking; for example, unlink does not check the linkscount field before modifying it... * Finally, although ext3 has redundant copies of the superblock (RRedundancy), these copies are never updated after file system creation and hence are not useful. -
ReiserFS文件系统在读写错误的时候,有更多的处理错误码的操作。另外ReiserFS文件系统在检查内部结构的时候也比ext3文件系统更多。在探测到写入发生故障的时候,ReiserFS倾向于直接引发kernel panic,这样之后一般会引发系统的重启已经相应的恢复操作。ReiserFS这样做的原因是倾向于保持内部结构的正确性。对于读取错误,会返回错误码给应用,在一些情况下会重试操作。ReiserFS也存在不少的问题,Paper中总结如下,
* For example, when an ordered data block write fails, ReiserFS journals and commits the transaction without handling the error (RZero instead of the expected RStop)... * Second, while dealing with indirect blocks, ReiserFS detects but ignores a read failure... * Third, ReiserFS sometimes calls panic on failing a sanity check, instead of simply returning an error code. * Finally, there is no sanity or type checking to detect corrupt journal data; -
JFS在处理读取错误的时候也会防护错误码,但是同样的大部分的写入错误被直接忽略了。检查方面,JFS也只有很少量的检查,比如检查superblock、 journal superblock等,其它的检查也有。在恢复处理方面,JFS对不同的block处理方式有很多的不同,在写入 journal superblock错误的时候,JFS会crash系统,而其它的写入一般就是直接忽略了。对于super block,JFS用副本的机制容错。读取也可能导致系统crash,比如读取 block allocation map和 inode allocation map错误的时候。Paper中也总结了JFS存在的一些问题,
* First, while JFS has some built-in redundancy, it does not always use it as one would expect * Second, a blank page is sometimes returned to the user (RGuess), although we believe this is not by design (i.e., it is a bug) * Third, some bugs limit the utility of JFS recovery; for example, although generic code detects read errors and retries, a bug in the JFS implementation leads to ignoring the error and corrupting the file system.
另外Paper中对非Unix-linke的NTFS也有一些分析。对于这些分析了的文件系统,Paper中总结它们处理硬件故障时候的一些特点,1. ext3采用的都是很简单的办法,倾向于认为硬件时可靠的;2. ReiserFS较少关注磁盘的故障,但是处理了写操作时候发生的问题,另外有不少的检查机制;3. JFS处理有点随意,有时候返回错误码,有时候直接不处理,有时候有专门的应对措施。
0x12 一个IRON FS的基本设计
Paper中在测试了好几个文件系统之后,发现它们或多或少都存在问题。对此,这里以ext3为基础提出了一个IRON文件系统的设计。这个 IRON ext3的设计改动体现在这些方面,
-
Checksum,为Block计算一个chunksum,使用sha-1,先是记录到journal中,然后后面处理的时候保存到最终的位置。Paper中没有具体怎么样保存这些checksum,但是一般会远离block实际保存的位置单独保存。
-
元数据多副本保存,所有的metadata blocks写入到一个额外的replica log中。之后处理这个log,写入到最终的位置,这个位置和原来ext3文件系统保存元数据的位置也会有一些距离。
-
Parity,文件创建的时候,为每个文件额外分配一个parity block。在更新文件的时候,在这个block上更新??
When a file is modified, its parity block is read and updated with respect to the new contents. To im- prove the performance of file creates, we preallocate parity blocks and assign them to files when they are created. -
事务checksum,为journal中一个事务写入的数据也计算一个checksum,会保存到journal commit block中。
这些内容和[1]中提到的内容比较相似。
参考
- ffsck: The Fast File System Checker, FAST ‘13.
- SQCK: A Declarative File System Checker, OSDI ‘08.
