End-to-end Data Integrity for File Systems: A ZFS Case Study
0x00 引言
文件系统的数据完整性( Data Integrity)是一个比较难处理的问题,现在的很多文件系统不能保证数据完整性。这篇Paper分析ZFS的端到端的数据完整性。主要设计到几个方面,一个是文件系统持久化部分数据的数据完整性,主要涉及到文件系统的元数据以及文件数据本身,这里导致数据完整性问题的主要原因是存储硬件保存的数据随着时间发送了变化,以及Crash导致的系统的不一致的状态;另外一个就是数据在到达application过程中 or application到文件系统路径上面的数据完整性,这里导致数据完整性的原因是memory corruption,比如DRAM Bit Flip or 软件的Bug导致的内存踩踏。一般理论上硬件出现数据错误的可能性很低,但是实际应用中这个概率不能用理论的值来预测,
In a recent study of 1.53 million disk drives over 41 months, Bairavasundaram et al. show that more than 400,000 blocks had checksum mismatches, 8% of which were discovered during RAID reconstruction, creating the possibility of real data loss.
0x01 On-disk data integrity in ZFS
ZFS持久化数据的数据完整性保证主要使用来checksums和副本的机制。在ZFS中,block pointer是一个基本的结构,ZFS用block pointer来寻找指定的Block。一个block pointer最多包含3个实际的block的位置信息,这些blocks称之为ditto blocks。一个位置信息包含了DVAs (data virtual addresses),dva记录了block在那个磁盘上面的哪一个位置,除了这些基本的位置信息之外,还会保存block的checksum信息。ZFS默认情况下,数据Block使用1个ditto block,一个zpool中file system的元数据使用2个ditto block,而全局的元数据使用3个ditto block。另外,在ZFS中,
-
磁盘上面的blocks通过objects的形式来组织,这里计为dnode。一个dnode也最多包含3个block pointer。这里保存的block pointer指向一个leaf block或者是 indirect block,前者比如data block,后者比如保存其它block位置的信息。这样object将block组织为一个树形的结构。一个dnode会有另外的一些空间来保存其它的一些结构,比如一个文件类型的object会保存一个znode,znode中保存的是数据的属性等的元数据信息。
-
Object sets,一个Object set表示一个object的集合,比如一个文件系统中的文件和目录的集合。相关结构会保存meta dnode的信息、一个ZIL (ZFS Intent Log) header等的信息,
The meta dnode points to a group of dnode blocks; dnodes representing the objects in this object set are stored in these dnode blocks. The object described by the meta dnode is called “dnode object”. The ZIL header points to a list of blocks, which holds transaction records for ZFS’s logging mechanism. -
另外在ZFS中每个 physical vdev设备会使用一个vdev label来描述这个dev和其它的相关的dev,通过两阶段提交来在多个dev上面保存多个副本。一个uberblock会保存在vdev label中,作为一个类似于super block的结构。在查找pool/zpool元数据的时候,通过目前的active uberblock 定位到pool访问级别的元数据,这些元数据的集合称之为Meta Object Set (MOS)。这些元数据会保存三份。然后通过访问MOS中的元素定位到具体file system instance,一个file system instance的元数据会保存两个副本。

Paper中使用了一个错误注入的方式进行注入data corruptions的错误,总结出ZFS在保护On-disk的数据完整性的一些特点,
- ZFS detects all corruptions due to the use of checksums;通过checksum能够检测到 corruption;
- ZFS gracefully recovers from single metadata block corruptions;能够利用副本很好地从元数据block corruption中恢复;
- ZFS does not recover from data block corruptions;不能从data block corruption恢复,因为默认data block只保存了一个副本;
- In-memory copies of metadata help ZFS to recover from serious multiple block corruptions;内存中保存的元数据副本会定期地commit到磁盘上面,这个会覆盖之前的可能的corruption的元数据版本。
0x02 In-memory data integrity in ZFS
文件系统内存的相关的数据主要是元数据 cache和page cache。一个block从磁盘上面读取上来之后,checksums校验通过的话,会被保存搭配page cache中直到被缓存替换算法(ZFS使用ARC算法)驱除出去。如果一个block被更新的话,会在一段时间之内被flush到磁盘上面,比如设置30s的时间。在被flush到磁盘上面的时候,ZFS使用CoW的机制,会选择一个新的位置保存这个block。在保存了这个block之后,会更新其parental block中的位置信息和checksum信息。其parental block的更新有会导致parental block的parental block更新,可能需要更新到root。Paper中发现这里ZFS的主要主题是没有对保存的内存中的数据进行校验,
-
ZFS does not use the checksums in the page cache along with the blocks to detect memory corruptions。ZFS没有处理内存中数据的checksum。
-
the window of vulnerability of blocks in the page cache is unbounded。虽然更新之后的block会在一段时间内被flush到磁盘,但是到从被load到内存到被更新的时间是不确定的。
-
Since checksums are created when blocks are written to disk, any corruption to blocks that are dirty (or will be dirtied) is written to disk permanently on a flush。checksum在被flush的时候添加,如果在内存中的时候数据就已经错误,则这些错误会被永久保存下来。
-
Dirtying blocks due to updating file access time increases the possibility of making corruptions permanent。access time更新在只读的workload也会存在,导致一些数据早读取的workload下面仍然被更新。就可能导致memory数据错误被持久化保存下来。
-
For most metadata blocks in the page cache, checksums are not valid and thus useless in detecting memory corruptions。ZFS meta block很多保存的是block pointer的信息,在磁盘上面保存的时候压缩保存,在读取出来的时候解压缩,所以这些block在内存中的时候checksum用不上。
-
另外还有这些一些特点,
When metadata is corrupted, operations fail with wrong results, or give misleading error messages (E) Many corruptions lead to a system crash (C) The read() system call may return bad data. There is no recovery for corrupted metadata.
0x03 Summary
这里的具体信息可以参看[1].
Recon: Verifying File System Consistency at Runtime
0x10 基本思路
这篇Paper的思路就是在前篇Paper的基础之上,将运行过程中的Consistency也考虑进入,主要就是数据在到达application过程中 or application到文件系统路径上面的数据完整性。Recon的基本思路在改动Block Layer。Recon主要是为了处理元数据的Consistency。Recon考虑了运行时Verifying File System Consistency的基本问题:
-
什么时候其检测Consistency。Recon讨论了两类机制的文件系统,使用shadow paging机制和日志机制的文件系统。基于这两类的文件系统使用一个transactional来保证机制来保证更新文件系统多个地方时候的数据一致性,而事务一般有一个执行操作然后提交的过程。Recon认为事务提交的时候是一个很好的检查的时机,所以其选在在提交之前执行检查操作。对于使用shadow paging机制的系统,事务相关的数据会在commit block写入磁盘之前写入磁盘,比如betrfs中在写入完相关的blocks之后,通过更新superblock(CoW)来进行提交操作,Recon就选在这个更新操作之前操作。在日志式文件系统中,会有更多的操作:
For example, ext3 writes metadata to disk in several steps: 1) write metadata to journal, 2) write commit block to journal, at which point the transaction is committed, 3) write (or checkpoint) metadata to its final destination on disk, and 4) free space in the journal.这里Recon选在在第一步的时候复制metadata blocks一份到一个write cache,然后在commit block写入之前进行检查操作。处理这个之前还会检查checkpointing操作。
-
需要检查哪些信息。这里主要根据的是e2fsck中使用的一百多个的ext文件系统需要保证的特征。这里的检查的内容也就是采用了e2fsck使用的内容。怎么样去检查。在运行时候检查这些需要满足的条件的时候,Recon需要知道某个Block是一个什么样的Block,从而知道其中保存的内容。Paper[2]中描述了去探测Block的类型的方法。在文件系统事务提交的时候会进行检查的操作。检查包括一些不应该变化的字段值是否发生了变化,一些值的取值范围是否在合法的访问之内等等。
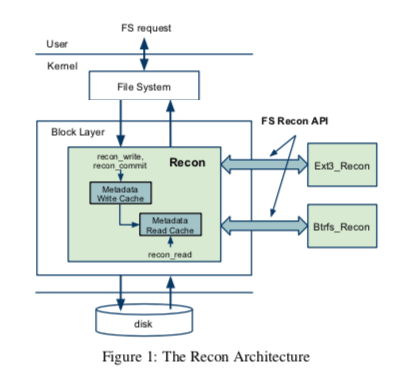
Recon在Linux的Block Layer中添加了一些逻辑。在读取一个metadata block的时候,会被cache在Recon read cache中,在写入到磁盘的时候,写入的metadata block会被cache在Recon write cache中。一般Recon read cache写入的数据会被认为是正确的,因为被校验了,而写入Recon write cache则可能是corruption的。在更新提交的时候,Recon framework要求相关的transaction blocks都在Recon中记录,recon_commit在commit block落盘之前被调用。为了实现在提交之前引入Recon的逻辑,Recon这里有两种方式,一种是在在文件系统的transaction-layer进行改动,加入相关逻辑,这种方式实现更加简单,但是每个文件系统使用的日志逻辑不同,可能要分别适配;另外一个是在block-layer改动,在block-layer改动需要区分出metadata block和data block,Recon区分的逻辑是对于ext3,metadata block会写日志,而data block不会(默认配置下面),对于betrfs根据metadata block会写入到不同的区域。
在检测到corruption的时候,Recon中讨论的处理方式:unmount文件系统,重新启动,可能导致数据丢失但是不会导致文件系统损坏。如果可以创建文件系统snapshot,则可以选择创建一个,隔离原先正常的部分和出问题的部分。Recon的思路实现的话会有非常多的细节问题要处理。
0x11 评估
这里的具体信息可以参看[2].
High Performance Metadata Integrity Protection in the WAFL Copy-on-Write File System
0x20 引言
这篇Paper是WAFL文件系统中Metadata元数据完整性保护的一些措施。由于WAFL文件系统是一个商业产品,这里会更多考虑方法的实际应用的问题。这里认为Recon采用的方法会对性能有比较大的影响。WAFL采用的思路是checksum作为检查方式,关键是选择一个可以实现Incremental Checksum计算的Checksum方法,即更新一部分checksum计算的数据的时候,不需要完整计算全部相关数据的checksum,有更新的信息即可,另外就是利用基于Digest的审计方式。
0x21 基本思路
文件系统运行的时候,Paper中特别提到 Scribbles 导致的元数据顿坏,即软件(不一定是WAFL文件系统,可能是同时运行的其它部分)的bug导致内存踩踏,写坏了正常的数据。这些Bug会比逻辑的Bug更难处理。Paper中描述了WAFL文件系统使用的三种机制,
-
In-memory metadata checksums,前面的第一篇Paper中提到ZFS中在处理数据保存到磁盘上面是,使用了checksum和副本的方式来保存数据完成性,但是没有处理在内存中的时候数据损坏的情况。WAFL在这里则引入了内存中的checksum。WAFL使用的是一种增量式的checksum计算方法。基本的思路如下,假设D为一个n个bytes(D1, D2… Dn)的数据,D的checksum的计算方式如下,
A = (1+D1 +D2 +...+Dn) mod 65521 B = (n×D1 +(n−1)×D2 +...+Dn +n) mod 65521 Adler32(D) = A + B × 65536 // 加入原始的checksum为C,在D的第i个byte被修改时,假设有Di变成Di',则这样重新计算D的checksum。具体的数据原理可以参考相关资料: A = C mod 65536 B = C div 65536 ∆Di = Di'− Di A′= (A + ∆Di) mod 65521 B′= (B+(n+1−i)×∆Di) mod 65521 Adler32Incr(C,Di,Di',i) = A′ +B′×65536这样的计算方式处理避免全部重新计算之外还有一个好处就是更加容易实现Lockless Multiprocessor Updates。一个block的checksum计算可以被split到不同的核心上面计算,每个核心单独计算delta checksums。买入有两个segment C1和C2,则
A = (C1 mod 65536 + C2 mod 65536) mod 65521 B = (C1 div 65536 + C2 div 65536) mod 65521 combine(C1,C2) = A + B × 65536 // 两个核心分别更新Di和Dj的时候,可以通过这样的方式组合, C1 = C2 =0 C1′ = Adler32Incr(C1,Di,Di',i) C2′ = Adler32Incr(C2,Dj,Dj′,j) C′ = combine(C,combine(C1′ ,C2′ ))在一个Block写入到磁盘上面的时候,会重新计算一篇这个Block的checksum,然后和其目前的incremental checksum对比,即探测到一个内存损坏。在检查到损坏的时候,相关的文件系统事务会被abort,之后会重启这个节点。
-
Metadata page protection。前面的方式只是探测到了内存踩踏,但是不确定时哪里造成的。WAFL引入一个metadata page保护机制来处理那些可以复现的Bug。这里利用了page-level protection 机制和x86的 Write-Protect Enable (WP) bit机制。在默认情况下,metadata保存的page被标记为只读,只在需要更新这个page数据的时候才暂时设置为可写。在内存踩踏发生的时候就会导致一个page fault,从而通过stack trace追踪到内存踩踏的根源。这样方式的一个缺点时如果相关的Page被频繁更新,性能会下降很多,WAFL采用的一个缓解方式是Write-Protect Enable (WP) bit机制机制有缓解了这种性能下降。但这种方式也有缺点,
When write protection is disabled on a CPU core, it can write to any address. This ability implies two risks: (1) the metadata modification code itself might scribble, or (2) interrupt handlers that are serviced by the processor during that window might scribble otherwise read-only memory. -
Transaction auditing。与前面的Recon使用的基本fseck的方式不同,WAFL这里使用的审计方式时给予Digest的,摘要。系统中的consistency invariants主要涉及到两种:1. Local consistency invariant,指的是一个metadata block内保存的数据要满足的条件,比如block pointers的值必须在合法的访问内;2. Distributed consistency invariant,不同的metadata blocks之间的consistency,比如一个block被从一个 indirect block中删除的时候,标记这个block为空闲的位置必须得标记上。Paper中以这个为例子解释了一下原理,比如一个indirect block中64bit大小的block numbers B1,B2,…,Bn,其中的Bi、Bj、Bk被一个事务更新为Ni、Nj和Nk。则关于free block的计算与个digest,分配了的计算一个,
ΣIndFree = Bi +Bj +Bk +... ΣIndAlloc = Ni +Nj +Nk +... // 在对于的标记空闲的bitmap上面,也计算这样的一个, ΣBitmapFree = Bi +Bj +Bk +... ΣBitmapAlloc = Ni +Nj +Nk +... // 检查的时候检查: ΣIndFree == ΣBitmapFree ΣIndAlloc == ΣBitmapAllocPaper中也总结了这样方式的优缺点。处理这个例子之外,文件系统中还包括了其它的部分要检查的内容,
Description of Equation 1 Each inode tracks a count of all blocks to which it points. The file system also maintains a total count of all the allocated blocks. Their deltas much match. 2 The bitmap uses a bit to track the allocated state of each block in the file system [37]. The file system also maintains a total count of all allocated blocks. The delta of the latter must equal the delta of the number of bits that flipped to 1 (i.e., allocated) minus the number of bits that flipped to 0 (i.e., free). 3 The inode metadata tracks the allocation status of each inode. The file system maintains a total count of all allocated inodes. The delta of the latter must equal the number of inodes that changed state from free to allocated minus the number of inodes that changed state from allocated to free. 4 The inode metadata tracks deleted inodes that are moved to a hidden namespace awaiting block reclamation [37]. The current file system maintains a total count of these hidden inodes. The delta of the latter must equal the number of inodes that were deleted (i.e., moved into the hidden namespace) minus the number of inodes that were removed from the hidden namespace after all their blocks had been reclaimed. 5 The refcount file maintains an integer count to track all extra references to each block; WAFL uses this file to support de-duplication. The file system maintains the physical space that is saved by de-duplication as a count of blocks. Their deltas much match. 6 Each inode tracks a count of physical blocks that are saved by compression. The file system maintains the physical space that is saved by compression as a count of blocks. Their deltas must match.
0x22 评估
这里的具体信息可以参考[4].
参考
- End-to-end Data Integrity for File Systems: A ZFS Case Study, FAST ‘10.
- Recon: Verifying File System Consistency at Runtime, FAST ‘12.
- SQCK: A Declarative File System Checker, OSDI ‘08.
- High Performance Metadata Integrity Protection in the WAFL Copy-on-Write File System, FAST ‘17.
- IRON File Systems, SOSP ‘05.
