Horovod: fast and easy distributed deep learning in TensorFlow
0x00 基本思路
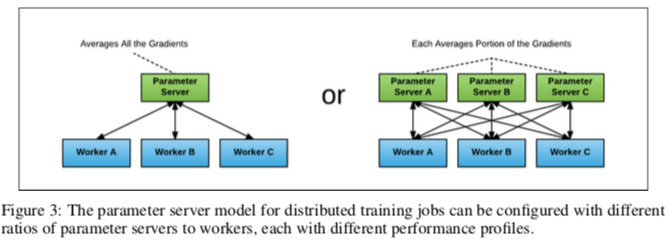
与其说这里的是deep learning中的内容,不如说这里解决的还是分布式计算中的一些问题。之前在天河一号上面跑过的MPI中的程序就有类似的内容。Horovod这篇Paper的内容比较简单,主要就是如何将ring-allreduce应用到TensorFlow中,用于分布式的深度学习训练。Ring-allreduce是百度的一片文章讲述了如何应用到深度学习的训练上去的,不够现在这篇文章的URL打不开了,在网上可以找到其它的描述[1]。在分布式的训练中,每个计算单元只会计算全部计算任务中的一部分,这样就只能得到一部分的结果。需要一种机制来将其它计算单元的计算结果来同步到本机上面,常见的一种方式是Parameter Server的方式,如下图所示。使用中心的一个 or 一组服务器来处理这个合并计算结果并将合并之后的结果分发到各个worker上的任务。这样的一个问题就是,随着系统中节点数据的增长通信成本会增长很快,下图右边就比左边的情况复杂了很多。
这里使用的一种方法就是Ring-allreduce,基本的思路如下图所示。节点组成逻辑上面的一个环,每个节点从其上一个收到数据,并向下一个节点发送数据。这样每个节点只和自己相邻的节点产生交互。工作的时候,每个节点上面的数据被划分为相等数量的chunk,在前面的几步的操作中,每个节点对应位置的chunk按照环的发送“流动”,这样在运行了N-1次之后(N为节点的数量),一个chunk由A流动到了B,在这个过程中,即每次向后流动的时候,会合并这个节点上面对应chunk的节点。当流动到B时,B对应的chunk就合并了所以节点的对应chunk的结果,而前面的节点对应的chunk分配缺失了一步。到这里的操作称之为scatter-reduce。
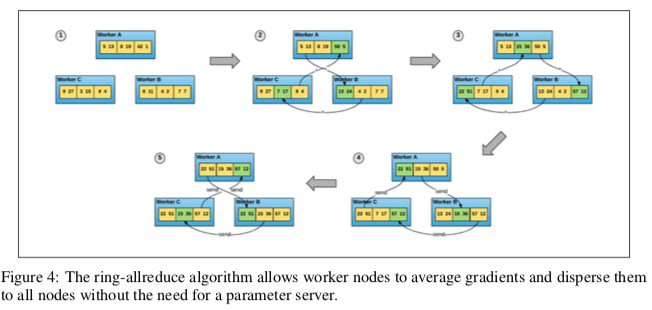
下一个阶段的操作称之为all-gather,目的是将节点没有缺失的部分补齐。基本的操作和前一步骤操作是一样的,不够由于这个时候已经保存了的数据和传输过来的时候可能会有重复的部分,这里需要处理一下。当操作N-1次之后,所有节点都可以获得全部的数据更新。另外[1]中有很详细的解释。
0x01 评估
这里的具体信息可以参考[2].
Blink: Fast and Generic Collectives for Distributed ML
0x10 基本思路
这篇Paper也是解决分布式训练中的通信的问题。前面的Ring-Allreduce没有考虑,在现实中,不同的线路是不一样的。也就是存储异构的情况,比如PCIe和NVLink,它们之间的传输特性相差比较大。这里则考虑优化这样的情况。Blink这篇先从广播的情况出发,即一个节点的数据发送到其它节点(这里表示一个GPU)。广播情况,
-
Blink将目前系统中的节点和连接情况抽象为一个图,问题就转化了图论中的一个directed spanning trees的问题,即有向生成树的问题的一种变体。Blink要做的就是一个图G和一组的spanning trees中,找到通过使得传输速度能最大的一个,同时这样会带有每个边的capacity的限制,即传输连接速度的限制,
... finding the maximal packing of a number of directed spanning trees or arborescences in the graph. Each arborescence Ti originates at the root vertex and follows directed links to span every other vertex. Thus the problem of finding the optimal schedule for broadcast can be solved by finding the set of maximum weight arborescences that satisfy the capacity constraints. -
Blink任务目前解决这个问题的精确的算法复杂度太大了,就提出了一种近似的算法。基本的思路是运行一个迭代过程,每次迭代找到面前的minimum weight spanning tree,最小权重生成树。然后更新这个树上面的对应到图上面的权重,每次改变 ε 的比例。这个算法另外的一个问题会生成很大数量的spanning tree。Blink有使用一种integer linear program (ILP)的方法,即整数线性规划的方法,即在限制为k表示的数量的条件下,同时最大化能得到的最大的w, \(\max\sum_{i=1}^K w_i,\\ s.t. ∀e ∈ E,\sum_i k_i*w_i < c_e, ∀w_i ∈{0,1},\\ where\ k_i = 1, if e∈T_i, otherwise\ k_i = 0;\) emmmm,这里都只是节点的思路,具体算法的细节没有,优点很抽象。
-
上面描述的是one-to-many情况下的操作,在Broadcast操作,和Gather操作(即Broadcast的逆操作),得到很优的方法。在many-to-many的操作情况下面时,Blink利用面前节点之间的连接都是双工的,在一个方向时many-to-one操作,在另外一个方向使用one-to-many操作,
For example, to do an AllReduce operation on the directed graph, we first run a reduce operation to a chosen root vertex using the undirected graph and then do a broadcast operation from the root vertex using the same tree but with links going in the reverse direction. -
在PCIe连接和NVLink这样异构连接存在的时候,一个问题就是目前存在NVLink的时候,NVIDIA的驱动都是自动走MVLink,利用不上PCIE,不过有API禁用NVLink。在这种异构中的情况下,Blink会为PCIe,NVLink分别构建。然后后面的优化目标就是 max(Time of PCIe,Time of NVL)。D开头的表示数据量,BW表示带宽,T表示时间, Tdpa表示关闭NVLink的时间。这样优化目标用下面的式子表示,
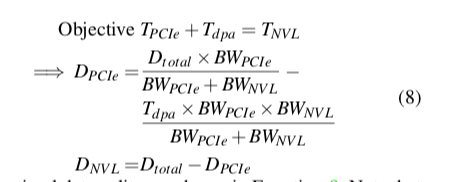
emmmmm,挺模糊,抽象的。在拓展到多个服务器上面时,使用了AllReduce的思路,基本思路如下图所示,第一步时本地的Reduce操作,结果被合并到一个机器中的一个节点上面,然后在第一个广播到其它的机器上面,分别进行聚合操作。第三步在讲聚合的结果广播到本机的其它节点上面。也就是说,在多机的情况下,使用的还是一种AllReduce的方式。
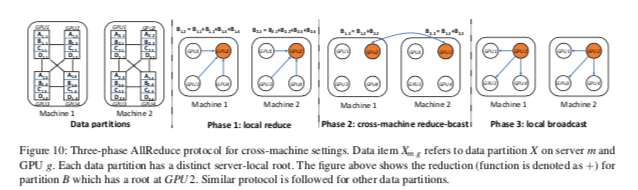
这里的实现也比较有意思,通过目前系统的拓扑情况按照上面的方法求出方案之后,通过使用代码生成的方法生成通信用的代码,然后编译为动态库,然后链接到程序中使用[3]。
0x11 评估
这里的具体信息可以参考[3].
Accelerating Distributed Reinforcement Learning with In-Switch Computing
0x20 基本思路
这篇Paper的脑洞很大,相当于把PS的一些功能放到了交换机中实现。Paper中使用的例子是同步设置情况下的PS,基本思路如下图所示,下图中表示的例子大概是一个节点的结果聚合的过程,表现为多个向量之间的运行,每个输入的向量来自于下面的各个运算节点,聚合之后的结果被分发到这些节点,就是一个很典型的PS的情况。这些计算操作在交换机中实现会有很多的限制,主要有,1. 交换机为转发数据包设计,这里不能影响到这样的正常的功能,2. 交换机的CPU、内存资源都很有限,3. 要求能够适应计算节点数量的调整。
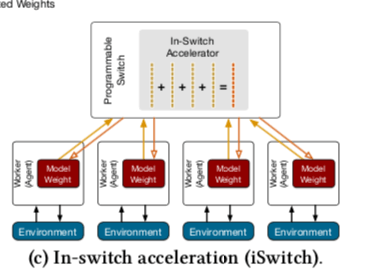
iSwitch利用了IP头中的Type of Service (ToS)字段来标示需要交换机进行特殊处理的数据包。这个字段使用不同的值来表示标识不同类似的数据包,对应到不同的Action。主要包括控制数据包和值数据包两类,值数据包的值会在UDP头部的后面,控制包也会在UDP头部保存控制的一些信息,比如SetH动作会设置有多少个梯度vector。Action的种类如下所示。
Name - Description
Join - Join the training job
Leave - Leave the training job
Reset - Clear accelerator buffers/counters on the switch
SetH - Set the aggregation threshold H on the switch
FBcast - Force broadcasting a partially aggregated segment on the switch
Help - Request a lost data packet for a worker
Halt - Suspend the training job on all workers
Ack - Confirm the success/failure of actions
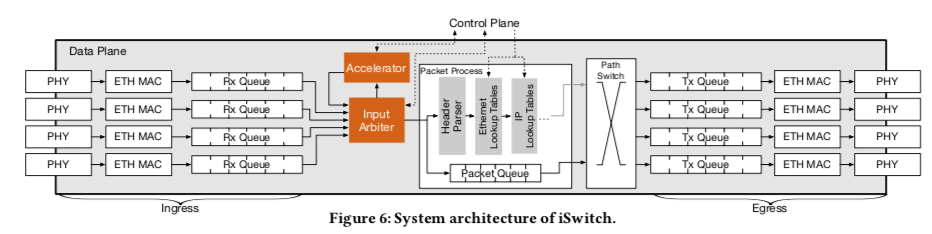
由于交换机的计算资源有限,iSwitch只会用于计算简单的运算。对于向量的聚合运行,数据包中会有一个 8-byte Seg字段,标识对应数据的位置,用于计算的时候对应位置的值进行运算。这个字段后面保存的就是数据,数据都是以原始的浮点数来保存。为了支持iSwitch的处理逻辑,在基本的交换机的结构上面,添加了下图中的两个橙色的部分, Input Arbiter用于检查是否是要特殊处理的包,这些包会被输入Accelerator而不是直接转发到Packet Process中。在Accelerator中,对于要处理的值数据包,会从中提取出Seg字段,对应Seg的值被进行对应的计算。另外会有一个 aggregation counter来统计已经计算了多少次,当到达SetH设置的数据的时候,表示这个Seg运行完成。之后的结果进入转发出去的流程。
脑洞挺大的,233333。不过实际能够应用的可能性不大。
0x21 评估
这里的具体信息可以参考[4].
参考
- http://andrew.gibiansky.com,
- Horovod: fast and easy distributed deep learning in TensorFlow, arXiv.
- Blink: Fast and Generic Collectives for Distributed ML, arXiv.
- Accelerating Distributed Reinforcement Learning with In-Switch Computing, ISCA ‘19.
- A Generic Communication Scheduler for Distributed DNN Training Acceleration, SOSP ‘19.
