KVell: the Design and Implementation of a Fast Persistent Key-Value Store
0x00 引言
这篇Paper中在具体系统的实现上,感觉没有提出什么有新意的东西。Paper的核心内容其实就是一种观点,目前CPU性能的增长主要体现在核心数量的增长上,单核性能增产缓慢。现在的NVMe SSD以及NVM的发展,使得一些存储系统的瓶颈由硬盘转向CPU。这里的KVell主要是针对瓶颈为CPU的环境的一种KV Store的设计。
0x01 基本思路
针对CPU为瓶颈,而存储够用的环境下,KVell的主要的一些设计选择,
- Share Nothing,主要就是内存中的一些数据结构为每个线程独立一份。比如内存的B-tree索引、IO队列、保存磁盘Free Blocks的List以及Page Cache等;
- Do not sort on disk, but keep indexes in memory,数据直接按照写入的顺序写入磁盘,不对数据进行排序操作。索引都保存在内存中。这个实际上很常见,没什么特别的;
- Aim for fewer syscalls, not for sequential I/O,前调为了更少的系统调用,而不是为了实现顺序IO。主要就是batch请求;
- No commit log ,不使用Commit Log;
接口方面,KVell和一般的有序的KV Store提供的结构基本相同。磁盘上面的空间被划分为4KB大小的块,数据项按照4KB的单位被划分为slab,这个和现在很多内存分配器的设计思路一致。这里的划分的粒度更大一些。不同尺寸的数据项被保存在不同的文件中。这里用很多管理内存的思路来管理磁盘空间。磁盘空闲的空间在内存中维护。另外的在内存的主要结构就是索引,还有就是Page Cache,都没有特别的地方。IO方面主要使用了Linux AIO。这里主要就是Client和Worker通过队列来提交请求,设置callback。根据不同的请求以及Page Cache的情况选择请求方式等。特别处理一点的就是更新的情况,更新没有超过一个Page的话可以利用上存储硬件写一个Page的原子性实现in place的更新,而如果是超过了一个Page,则需要在另外的地方写入新数据。
Client thread:
worker_id1 = prefix(k1) % nb_workers
queues[worker_id1].push({k1, GET, callback1})
worker_id2 = prefix(k2) % nb_workers
queues[worker_id2].push({(k2,v2), UPDATE, callback2})
Worker thread:
push I/Os to disk (io_submit async I/O)
int processed_requests = 0;
while(request r = queues[my_id].pop()
&& processed_requests++ < batch_size)
location = [file, index] = lookup(prefix(r.key))
page = get_page_from_cache(location)
switch r.action:
case GET:
if(!location || page.contains_data)
callback(..., page) // synchronous call
else
read_async(page, callback) // enqueue I/O break;
case UPDATE:
file = get_file_based_on_size((k,v))
if(!location)
... // asynchronously add item in file
else if(location.file != file) // size changed
... // delete from old slab, add in new slab
else if(!page.contains_data) // page is not cached
// read data asynchronously first ...
get({ (k,v), UPDATE , callback });
else // ...then update & flush page asynchronously
update cached page
write_async(location , callback)
events = get processes I/O (io_getevents async I/O) foreach(e in events)
callback(..., e.page)
0x02 评估
Paper中给出的书看非常吓人。而且KVell这种不支持事务的系统和支持事务的系统比较性能,这种比较的意义有待商榷。具体内容可以参考[1]。
Splinter: Bare-Metal Extensions for Multi-Tenant Low-Latency Storage
0x10 引言
这篇Paper的主要思路很有意思。KV Store提供的接口都是很简单的,简单的接口也有利于KV Store实现更加高的性能。但是这样的接口在实现负责的任务的时候,就会很麻烦,而且为了在简单的接口上面实现复杂的操作,效率也很低。这里的思路就是将一部分Client的逻辑直接上传的KV Store来执行,有点类似于Redis中的可以执行Lua代码的思路。而直接使用的是Rust。实现这个思路主要要解决这样的一些问题,1. No-cost Isolation,如何在保证隔离的情况下,有高效地执行Client的代码;2. Zero-copy Storage Interface,用于提高性能;3. Lightweight Scheduling for Heterogeneous Tasks,执行逻辑的时候的任务调度;4. Adaptive Multi-core Request Routing,请求路由,减少不同操作的传统,避免热点问题 or 某些核心忙某些核心空闲的问题。
0x11 基本设计
Splinter的基本架构如下。网络栈使用Kernel-Bypass的实现,和客户端通信协议使用基于UDP实现的一种。一个客户端发出的请求会被排队在一个队列中,这个队列有一个指定的线程处理。另外,这个Worker会被分配一个CPU核心,线程在这个CPU核心上面的允许。这种CPU亲和性的设计在类似的一些相同中很常见。这里Client提交的请求作为一个task,Splinter将其视为一个routine,将其运行、调度等,并提供get/put之类的接口给其调用。
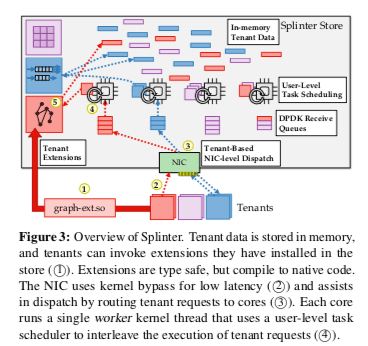
Splinter中当然是不能直接执行从外部来的代码的。Spinter接收到的代码必须经过检查、编译等之后才能执行。为了安全性,Rust的unsafe特性在这里不能使用,另外模块的使用也被严格限制,只有在白名单内的接口才能被使用的。由于能过执行外部来的代码,Splinter攻击面会非常大。这里的安全问题就需要从库、编译器等的多个方面都进行处理。Splinter的内存安全利用了Rust中的Ownership的概念,也通过利用Rust编译器的静态安全检查来处理一些问题(?)。外部代码可以使用这样的一些Splinter提供的拓展接口,
get(table: u64, key: &[u8]) → Option⟨ReadBuf⟩
Return view of current value stored under ⟨table, key⟩.
alloc(table: u64, key: &[u8], len: u64) → Option⟨WriteBuf⟩
Get buffer to be filled and then put under ⟨table, key⟩.
put(buf: WriteBuf) → bool
Insert filled buffer allocated with alloc.
args() → &[u8]
Return a slice to procedure args in request receive buffer.
resp(data: &[u8])
Append data to response packet buffer
部分拓展接口实现的内容,
-
Storing Values。持久化的记录会被Splinter保存到一个table heap中。Spinter可以通过拓展接口来添加数据。这个数据可以是通过网络接收到的,也可以是运行客户端的代码产生的。为了保证每次put的时候都能保证有足够的内存保存这些数据,这里通过先通过alloc接口分配内存,然后使用put接口实际添加数据的方式。alloc接口会指明为那一个table的那一个key分配内存,UAF之类的问题通过Rust的所有权机制来避免。下面是拓展接口一个使用的例子,
fn aggregate(db: Rc<DB>) { let mut sum = 0u64; let mut status = SUCCESS; let key = &db.args()[..size_of::<u64>()]; if let Some(key_lst) = db.get(TBL, key) { // Iterate KLEN sub-slices from key_lst for k in key_lst.read().chunks(KLEN) { if let Some(v) = db.get(TBL, k) { sum += v.read()[0] as u64; } else { status = INVALIDKEY; break; } } } else { status = INVALIDARG; } db.resp(pack(&status)); db.resp(pack(&sum)); } -
Accessing Values。通过get接口获取对应key的ReadBuf。为了性能,这里不需要进行数据的拷贝,这样要解决两个问题。第一个就是GC的问题,这个ReadBuf的引用会在Splinter中记录下载,避免在使用的时候被回收。另外的一个问题就是避免ReadBuf中的数据被更新。get返回的接口是一个不可变的数据,Splinter会避免in-place updates。另外就是一些避免序列化、反序列化的优化。
另外,客户端提交的代码运行时间是不确定的,可能会运行相当长的一段时间。这样就需要Splinter有一些任务调度的机制。请求被处理的时候,对应的任务会被分配一个stackless coroutine 来运行,通过yield操作可以主动让出CPU,让其它的任务运行。待用拓展接口都意味着调用yield操作。为了解决通过类似无限循环的方式占有CPU的问题,Spinter这里引入了一个watchdog thread,如果一个任务在一定的时间内没有调用yield操作,这个watchdog thrad会ping到对应的CPU核心上面,达到和之前的worker thread竞争的效果。然后另外的一个worker线程被创建,被pin在同样的CPU线程上面,将之前的worker thrad的任务窃取过来。
0x12 评估
这里的具体信息可以参看[2].
HyperDex: A Distributed, Searchable Key-Value Store
0x20 基本思路
HyperDex解决的事一个数据分区的一个问题。一般的KV Store分区只能根据Key的来进行hash or range分区。如果分区设计到多个属性,不仅仅是key,处理起来就会很麻烦。HyperDex提出的思路就是将多个属性的映射到一个hyper space中,根据hyper space不同的 区域来进行数据划分。而根据主键/Key来划分可以看作是一维的特殊情况。下面是一个三维空间的例子,由三个属性的hash space组成。图中的例子以查询FistName = ’John‘ 和 Last Name = ’Smith‘为例。在这个Hyper Space中,黄色平面内的数据会复合查询的要求。整个space会被划分,不同的space保存到不同的区域,查找满足上述条件的数据的时候,只要查询由这个平面在的区域即可。
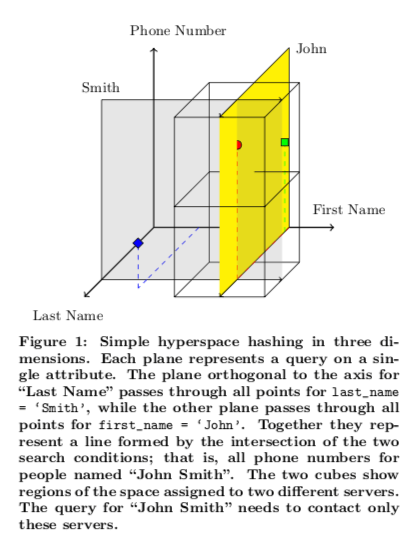
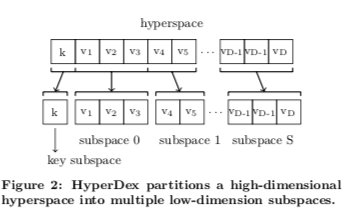
这样也可以看出,当查询条件中涉及到的属性越多的时候,这个涉及到的区域就越少。而查询的条件属性越少的时候,涉及到的属性就越多。Paper中的一个解决方案是将多个属性划分到一个subspace,如下图所示,来降低hyper sapce的空间维数,缓解这个问题。另外,现在的存储系统一般都会保存多个副本,在不同的副本中使用不同的排序规则也许是一个Idea。
参看
- KVell: the Design and Implementation of a Fast Persistent Key-Value Store, SOSP ‘19.
- Splinter: Bare-Metal Extensions for Multi-Tenant Low-Latency Storage, OSDI ‘18.
- HyperDex: A Distributed, Searchable Key-Value Store, SIGCOMM ‘12.
- Performance and Protection in the ZoFS User-space NVM File System, SOSP ‘19.
