Snap: a Microkernel Approach to Host Networking
0x00 引言
Snap是Google开发的一个用户空间的Networking System。一般的使用网络的应用都是直接使用内核提供的网络栈。但是近年,由于直接使用内核网络栈的一些缺点,比如性能优化、开发新功能都比较麻烦、困难,出现了不少将网络栈从内核中移入用户空间实现的。Snap也是类似的这样一个系统,但是Snap被Google部署在生成环境中多年,其可行性肯定是更好的。和直接使用内核的网络栈相比,Snap能过实现更高的性能,而且提供RDMA的支持,
Our evaluation demonstrates over 3x Gbps/core improvement compared to a kernel networking stack for RPC workloads, software-based RDMA-like performance of up to 5M IOPS/-core, and transparent upgrades that are largely imperceptible to user applications.
0x01 基本架构
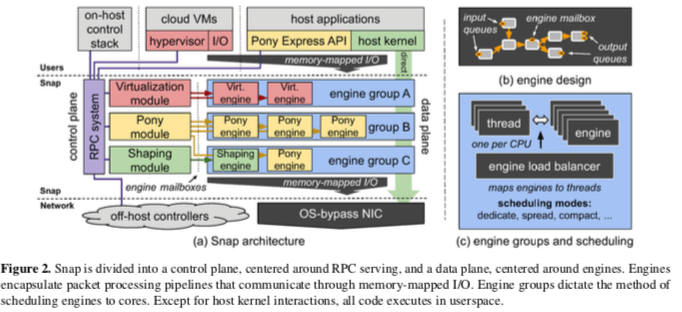
Snap被实现为Linux的一个用户进程,并利用了微内核的一些思想。Snap这里更像是一个网络服务,和其它的用户空间网络栈相比,能过中心化地管理网络资源(其它的很多用户空间网络栈都是作为一个lib,和应用进程运行在一起,这样不同应用进程的网络栈是分开的)。另外Snap由实现避免在内核中开发的麻烦,以及由此带来的性能提升。操作系统授予Snap进程独占访问一些网络资源的权限,但是Snap进程并不运行在特权态。Snap进程和应用进程的通信通过共享内存 or Unix Domain Socket完成。Snap的基本架构如下,总体上,Snap被划为为Control Plane和Data Plane两个部分。RPC System提供Snap Control Plane和其它应用进程、VM等通信,但是Data Plane的通信则是用memory-mapped IO实现的,而中间的Control Plane和Data Plane之间的通信通过engine mailbox,一种特殊的非中心化的RPC机制(a specialized uni- directional RPC mechanism)。另外不同流量由不同的Pipeline来处理。
-
Engine。Engine是一个stateful的单线程的任务。一种Click-style的elements的组织方式,即一种将不同的逻辑处理单元组织为流水线的方式,来处理任务的一种模型。一个engine的可能有多个输入/输出,输入/输出可以是其它的应用进程、guest,或者是内核的pagkets ring buffer,网卡的输入/输出队列,还可以是其它的engine等。为了实现更好的性能,这里一般通过共享内存进行通信,当然也可以通过中断的方式。
-
模块,Snap的Module负责设置Control Plance的RPC服务,实例化Engine,并将Engines设置为Engine Group。另外负责设置好用户的设置。和外部的应用通信通过RPC,而和Engines通信使用Lock-Free的engine mailbox,
To support Snap’s real-time, high performance requirements, control components synchronize with engines lock-free through an engine mailbox. This mailbox is a queue of depth 1 on which control components post short sections of work for synchronous execution by an engine, on the thread of the engine, and in a manner that is non-blocking with respect to the engine. -
Engine可以看作是一种处理网络数据的一种方式。不同的Engin/处理方式要求是不同的,比如有点更需要更大的带宽,有点则更加倾向于更低的延迟,有些多想要实现更好的CPU配置分配的公平性等等。Snap将不同要求倾向的Engines组织为Group。在下图中也有表示。不同的Group可以使用不同调度策略,比如1. Dedicating cores,这种模式使用一个指定的CPU核心来运行。这种方式核心的利用率可能不平衡,在控制总的CPU配额使用和降低延迟方面更适合;2. Spreading engines,这种模式下面,一个engine有一个指定线程运行,只有在收到通知的时候才进行调度;3. Compacting engines,这种模式下面,Snap会尝试尽可能地将任务运行在更少的核心上面。不同的策略有不同的优缺点[1].
-
Pony Express engine主要负责是接收传入的数据包,负责与应用交互,处理一些状态机(应该就是一些传输协议中的状态),以及产出传输数据包的。另外支持RDMA,Pony Express engine 还会处理one-side的操作。这里的很多操作记录轮询的方式,比如轮询NIC的输入队列,以及轮询应用的指令队列等。轮询的时候会设置一个批处理的大小,用于平坦overhead,提高性能。
-
另外,Snap为了实现它的一些调度策略,直接改动了内核的sched class。MicroQuanta的一种调度策略被添加到内核中,能过更好的实现延迟敏感的任务和其它的任务共存。
MicroQuanta is a robust way for Snap to get priority on cores runnable by CFS tasks that avoids starvation of critical per-core kernel threads. The sharing pattern is similar to SCHED_DEADLINE or SCHED_FIFO with real-time group scheduling bandwidth control. However, MicroQuanta schedules with much lower latency and scales to many more cores.
0x02 Pony Express: A Snap Transport
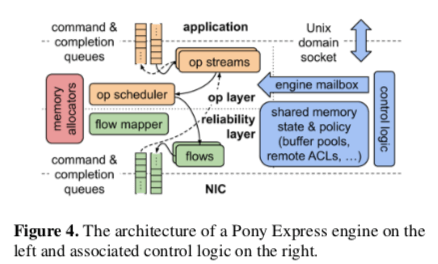
Pony Express是Snap中由于实现传输协议的一种机制。Pony Express不是一个TCP/IP的重新实现,这里Pony Express使用了更加灵活的接口,可以实现更加丰富的传输协议,比如支持RDMA。在Pony Express中,传输的处理在单独的线程中处理,与应用的记录分离开。通过设置线程的亲和性来优化在NUMA节点和NIC的通信开销,另外Pony Express的线程和其它的egines线程、传输处理线程共享CPU而不是应用线程可以实现更少的上下文切换、更好的局部性以及可以通过轮询减少延迟等的效果。Pony Express的基本架构如下,总体上Pony Express分为两层,上层实现应用层面的state machines,而下层实现可靠传输和拥塞控制。下层不会处理重排序、组装以及语义等方面的问题。两层之间的联系会有一个flow mapper,
The lower layer implements reliable flows between a pair of engines across the network and a flow mapper maps application-level connections to flows. This lower layer is only responsible for reliably delivering individual packets whereas the upper layer handles reordering, reassembly, and semantics associated with specific operations.
另外Paper中还讨论了实现上面的一些细节方面的问题,比如支持One-Sided操作,这里主要是RDMA中的One-Sided操作,另外就是Messaging and Flow Control ,以及Hardware Offloads优化。另外Pony Express的升级也是一个有意思的问题。这里总体的设计还是实现上面的一些细节对于实现类似Network as a Service的东西来说感觉很有参看价值。
0x03 评估
这里的具体信息可以参看[1].
Taiji: Managing Global User Traffic for Large-Scale Internet Services at the Edge
0x10 引言
Taiji这个名字怎么感觉就是中文的“太极”的拼音。现在的大型的互联网应用,会有数据中心,也会有边缘节点/Edge。数据一般都保存在数据中心,而边缘节点更加靠近用户,其主要是为了实现用户更快更低延迟的访问。所以在很多时候,边缘节点还是需要访问数据中心,Taiji主要解决的问题是如何路由边缘节点到数据中心的数据,实现数据中心的负载均衡和降低用户延迟。Taiji就是作为一个负载均衡系统的角色,
Taiji has been used in production at Facebook for more than four years and routes global traffic in a user-aware manner for several large-scale product services across dozens of edge nodes and data centers.
0x11 基本架构
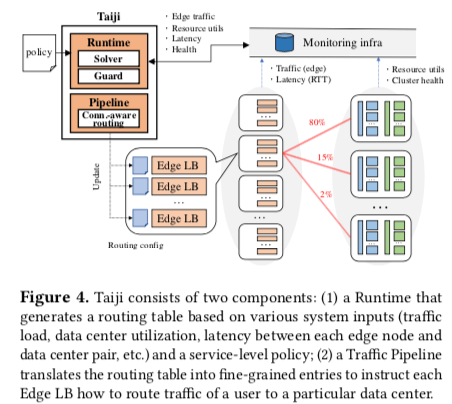
Taiji主要有两个部分组成,Runtime 和 Traffic Pipeline。其中Runtime决定将多少的流量发送给一个数据中心。Runtime输出的就是一个路由表,这个表用于决定流量的趋向。表的决定靠要基于SLO的要求。这里会被当作一个优化问题处理。另外的Traffic Pipeline负责具体的路由工作,这里的考虑主要就是流量之间的关联度,比如将关联性很强的用户的流量发送到同一个数据中心。
-
Runtime。Runtime产生的Routing Table可以简单地表示为
{edge:{datacenter:fraction}}。Runtime产生这样的输出需要数据的输入。这里的输入来自于两个方面,一个是infrastructure的状态,比如边缘节点和数据中心容量、利用率以及健康状况等的信息,另外的一个就是节点的流量大小和边缘节点到数据中心的延迟信息。有了这些信息之后,Runtime将边缘节点到数据中心的路由抽象为一个满足service-specific policy的分配问题。这里的策略主要包含了一些限制/constraints ,比如一个数据中内的资源利用率不能超过一个阈值;和一些目标/objectives,比如不同的数据中心的利用率比较平衡。这里的分配求解的测试主要是一种“best single move” 策略。这种策略会尝试改变单位流量通向的数据中心,找到最合适的一种。这个操作指导不能找打更好的为止。这里实际上是一种近似的策略,Our solver takes advantage of symmetry to achieve minimal recalculation. We compare our solver with an optimal solver using mixed-integer programming. Our solver always generates the optimal results despite using local search because the safety guards (§3.1.3) limit the search space.另外在调度流量的时候,会设置一些safety guards来避免一次性改变太多的流量。另外,这里路由信息会随着具体情况的变化更新。
-
Traffic Pipeline。Traffic Pipeline负责输出更加详细的路由信息,可以简单表示为
{edge:{datacenter:{bucket}}}。这里将用户划为为bucket。这里的划分利用了Facebook之前提出的Socail Hash。Socail Hash根据用户的关系密切程度来划分用户。这里通过Socail Hash计算出的信息来划分流量,这里称之为Connection-aware routing 。这里的划分有两个部分,一个将用户划分为bucket,这里是离线完成的。另外的就是bucket到datacenter的分配,这个得在线实时分配才行。由于这里的流量转发需要请求中用户信息,所以这里的Edge LB 可以分析用户请求中的用户的ID信息,比如通过HTTP Cookie。
0x12 Correctness and Reliability
这部分主要就是保证系统的准确性和可靠性,讨论的是工程上面的问题。主要在测试、容错方面的一些内容,
-
测试。这里发现Taiji的fail-stop bug处理起来是比较简单的,比较麻烦的事语义上吗的错误。一种测试的策略就是在一个独立的环境中,利用之前的历史数据来进行回归测试,这样的缺点就是只能测试已经发现过的问题,属于一种“事后”的测试。另外采用的测试方式是一种在线测试,
When onboarding new services or changing policies, we perform online testing that covers weekly traffic patterns. One common practice is to set conservative safety guards in order to understand Taiji’s behavior in a controlled manner before deploying to production. -
容错,Taiji为了容错,最小化了其依赖。其只依赖于监控的基础设置,而且会对监控的数据进行一些校验的操作,因为监控的数据又时候也会出现问题。另外通过副本的方式处理处理硬件故障,使用ZK来选举一个Leader,一个时间点只会有一个Leader来进行处理。Leader故障之后,会有其它的副本代替。
-
Embracing Site Events ,这里就是处理一些站点事件,比如reliability tests、failure mitigation。这两个个Facebook之前发表了一些Papers来说明。
0x13 评估
这里的具体信息可以参看[2].
参考
- Snap: a Microkernel Approach to Host Networking, SOSP ‘19.
- Taiji: Managing Global User Traffic for Large-Scale Internet Services at the Edge, SOSP ‘19.
- Risk based Planning of Network Changes in Evolving Data Centers, SOSP ‘19.
