Naiad: A Timely Dataflow System
0x00 Timely Dataflow
Naiad这篇Paper是SOSP ‘13的一篇best paper,和很多微软发表的论文一样,看上去做了个很厉害的东西,但是没有啥关注。这里提出的主要是一种称之为Timely Dataflow的模型,一种基于常见的有向图执行的抽象。另外的的一些特点是Timely Dataflow中定点是有状态的,接受和发送的消息会带有逻辑时间戳,而且图中可以包含环,甚至还可以嵌套。Timely Dataflow中的时间戳表示了不同的输入epoch和迭代的周期,顶点还可以在一个特定时间戳标记的数据都处理完成之后受到通知。Timely Dataflow中的一些基本概念,
-
图的基本组成是顶点和顶点之间的联系。Timely Dataflow中输入顶点指的是从外界输入数据的顶点。输入数据会标记上epoch的消息,并且会要通知顶点某个epoch的数据输入完毕。输出顶点指的是输出数据到外部消费者的顶点,这些输出数据也会带有epoch的消息,也可以通知外部的消费者一个epoch的数据输出完毕。在一些情况下,比如所有epoch数据输入、输出完毕之后可以close顶点。
-
另外,Timely Dataflow是支持带循环的图的,这样更好地支持迭代计算。Timely Dataflow这里引入了loop contexts的概念,指的是Timely Dataflow的有向图中的循环相关的结构,循环还可以嵌套。进入loop contexts的通过ingress vertex,而输出得经过egress vertex,另外图中的环的至少包括一个不在内部嵌套循环loop context(s)的feed-back vertex。
-
Timely Dataflow中的时间戳是逻辑上的,它实际上包含了两个字段。第一个字段e表示epoch,而第二个字段c=<c1,…ck>是一个向量,表示了k的嵌套的loop contexts各自循环计数。在处理的时候,不同类似的顶点输入时间戳和输出时间戳的对应的逻辑如下,分别是append元素到c、删除c最后一个元素以及对应c的元素加1的逻辑,
Vertex Input timestamp Output timestamp Ingress (e,⟨c1,...,ck⟩) (e,⟨c1,...,ck,0⟩) Egress (e,⟨c1,...,ck,ck+1⟩) (e,⟨c1,...,ck⟩) Feedback (e,⟨c1,...,ck⟩) (e,⟨c1,...,ck+1⟩)而时间戳的大小比较逻辑是先比较e,再比较c。
-
对于顶点上面的计算。每个顶点会实现这样的两个callbacks,分别用于接收消息和用于通知这个顶点一个时间戳标记的消息已经处理完毕,不会再有。
v.OnRrev(e : Edge, m : Message, t : Timestamp) v.OnNotify(t : Timestamp).另外的两个callbacks,功能和上面的两个callbacks相对,用于输出数据和发送通知。而且Timely Dataflow要求保证这样的一个时序:当t1<= t2时,OnNotify(t2)发生在OnRecv(e, m, t1)后。
this.SendBy(e : Edge, m : Message, t : Timestamp) this.NotifyAt(t : Timestamp).
实现Timely Dataflow一个很重要的内容就是如何实现在正确的时机发送Notify。为了处理这个问题,Timely Dataflow 这里引入了Pointstamp的概念,定于为:Pointstamp : (t ∈ Timestamp, l ∈ Edge ∪ Vertex) . 其中第二个字段表示location。对于SendBy(e, m, t)的操作,对应的Pointstamp是(t, e),而NotifyAt(t)操作,对应的Pointstamp是(t, v)。Timely Dataflow这里定义的Pointstamp也是有着顺序关系的,这里定义一个could-result-in的概念: (t1 , l1 ) could-result-in (t2 , l2 ) 指的是有且仅有图中的一个路径ψ = ⟨l1,…,l2⟩ ,在这条路径上面满足 ψ (t1 ) ≤ t2 ,而ψ (t1 )表示t1只会被路径上面的ingress, egress, or feedback类型的顶点修改,
We say a pointstamp (t1 , l1 ) could-result-in (t2 , l2 ) if and only if there exists a path ψ = ⟨l1,...,l2⟩ in the dataflow graph such that the timestamp ψ (t1 ) that results from adjusting t1 according to each ingress, egress, or feedback vertex occurring on that path satisfies ψ (t1 ) ≤ t2 .
这里将location l1到location l2的时间戳编程称之为path summary。Timely Dataflow中保证l1和l2之间有不止一条的路径,则不同路径产生的summary不一样。其中的一条总是会比其它的产生更早的改变之后的时间戳。如果找到其中的minimal path summary(minimal path summary定义为最早产生改成之后时间戳的?),计为Ψ[l1,l2] 。这样could-result-in就是检测Ψ[l1,l2](t1) ≤ t。一个naive的单线程实现的逻辑,
-
维护一个active pointstamps,每个元素对应到至少有一个还没有处理的event。每个元素对应到两个计数器,一个occurrence count(OC)表示没有处理完成事件的个数,precursor count(PC)表示在could-result-in order顺序下面,前面的active pointstamp的个数。
-
OC和PC的更新逻辑。对于occurrence count(OC),
Operation Update v.SENDBY(e,m,t) OC[(t,e)]←OC[(t,e)]+1 v.ONRECV(e,m,t) OC[(t,e)]←OC[(t,e)]−1 v.NOTIFYAT(t) OC[(t,v)]←OC[(t,v)]+1 v.ONNOTIFY(t) OC[(t,v)]←OC[(t,v)]−1而对于precursor count(PC),在一个pointstamp p 边为活跃的时候,初始化位前面could-result- in p的已经活跃的pointstamps 的计数,同时更新这个p后面的有could-result-in p‘的计数。在一个OC计数变为0的时候,p从活跃的pointstamp集合中移除,同时递减后面有could-result-in关系的PC计数。如果一个p的计数为0 的时候,称之为frontier。
-
系统输出化的时候,在输入节点初始化时间戳为epoch为初始epoch,而loop count都为0,OC初始化为1,PC为0。在epoch e标记为完成的时候,输入节点创建一个对应到epoch为e+1的新的active pointstamp,并删除e对应的pointstamp,并通知下游。而关闭一个输入节点则需要移除所有的active pointstamps。
Paper中这部分将了很多,其核心就是正确通知下游一个epoch的数据完成了。通知应该什么时候发送取决于图的形状和event处理的进度,而OC用于处理图形状问题,而PC用于处理处理进度的问题。感觉这里和一些类似系统中使用的异步快照的思路和作用有不少相同/类似的地方。
0x01 Naiad
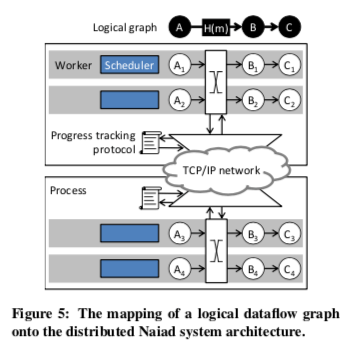
Naiad是Timely Dataflow的一个原型实现。为了更好地实现数据并行话处理。在逻辑上,Naiad将图抽象为逻辑图和物理图。逻辑图指的就是数据流之间的处理垃圾,就是一般对应到程序实现的逻辑。而物理图则是实际运行的时候的图,逻辑图一个顶点可能物理图上面的多个顶点,这样就能更好地实现数据的并行处理。顶点之间的连接抽象为conntector,同一机器上面共享内存,而不同机器上面使用使用TCP的方式。一个顶点发送数据到下一个顶点的时候,可以对数据分区。这里在分布式下面的实现还会有这样的一些要处理,
- Distributed progress tracking,即分布式的进度追踪。在分布式的情况下实现前面单线程的逻辑。这里每个worker维护一个local occurrence count,表示这个worker对global occurrence counts的认识。另外的local precursor count从local occurrence count计算而来,local frontier根据Timing Dataflow中定义的 could-result-in 定义。Worker通过广播的方式将progress updates的信息发送到其它的worker,其它的worker收到信息知乎更根据这些信息更新local occurrence count。这里一个worker的信息发送必须是FIFO,不能乱序,不同worker之间则没有顺序要求。这里机制的正确性证明在另外的一篇Paper中。
- Fault tolerance and availability ,容错。这里两个主要的机制是Checkpoint 和 Restore。系统会周期性地做Checkpoint,在做Checkpoint的时候,worker会暂定工作和信息发送,并将排队的消息持久化保存。Restore操作系统会协调所有存活的worker恢复到最后一个持久化的Checkpoint的,失效的worker处理的图的部分会被重新分配。
- reventing micro-stragglers ,即处理一些慢worker的问题,这里谈论的主要是一些优化策略,比如禁用Nagle算法,设置更低的TCP超时时间。优化数据结构的并发访问以及GC调优等。
用Naiad实现一个简单的Mapreduce程序的demo如下,
// 1a. Define input stages for the dataflow.
var input = controller.NewInput<string>();
// 1b. Define the timely dataflow graph.
// Here, we use LINQ to implement MapReduce.
var result = input.SelectMany(y => map(y))
.GroupBy(y => key(y), (k, vs) => reduce(k, vs));
// 1c. Define output callbacks for each epoch
result.Subscribe(result => { ... });
// 2. Supply input data to the query.
input.OnNext(/* 1st epoch data */);
input.OnNext(/* 2nd epoch data */);
input.OnNext(/* 3rd epoch data */);
input.OnCompleted();
0x02 评估
这里具体的信息可以参看[1].
TensorFlow: A System for Large-Scale Machine Learning
0x10 基本架构
TensorFlow用于Machine Learning,由于这些年AI的大火和Google做爹,TensorFlow收到非常多的关注。TensorFlow的基本抽象也是基于有向图,另外附加延迟执行,对不同GPU、TPU等的异构加速器的统一抽象的基本设计思路。TensorFlow使用保存原始知tensor来作为数据交换的格式,底层一般使用的的就是dense tensor,而spare tensor的用dense tensor来表示。很对类似的系统中都有一个Paramater Server的角色,而TensorFlow中则没有。一个TensorFlow集群的部署表现为分布在一个or多个不同设备上面的一组tasks,有相同的执行结构。其中的一部分用于实现类似Paramater Server,这些tasks称之为PS tasks,另外的称之为worker tasks。
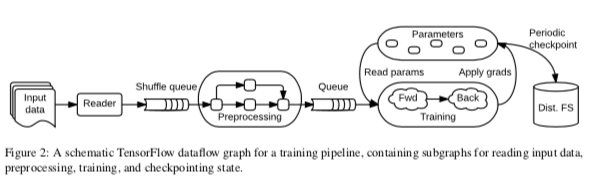
一个TensorFlow的执行流程图大概如上图所示。在TensorFlow中,数据计算、参数以及其更新规则以及输出处理等,都被抽象为数据流图的表示。数据的处理部分被抽象为图的节点,不同节点的通信抽象为图的边。这样不同计算都是独立的,可以个字并行进行。另外,TensorFlow支持在重叠子图上面运行多个并发执行任务,另外单个的顶点可以包含图中不同计算共享的可变的状态。这两点批流系统不同。TensorFlow另外的一些内容,
- TensorFlow认为Paramater Server的核心是一系列可变的状态,TensorFlow中的mutable state机制是的其能够使用模拟Parameter Server的功能,同时还有另外的一些优点[2]。
- 在TensorFlow图中,有这些基本概念:1. Tensors,多维数组的抽象表示,可以设置不同的维度和数据类型;2. Operation,在数据上面的操作的抽象,比如Const, MatMul, or Assign等;3. Stateful operations: variables,variable中为执行中可以被改变的状态。Variable常用的一个功能就是保存训练过程中的参数,实际上就是一块有类型的可以读写的缓冲区,使用reference handle引用这个Variable来进行操作;4. Stateful operations: queues,TensorFlow中包含多种类型的队列的实现,最简单的形式是FIFOQueue ,还包含了支持优先级类似的队列等。队列同样使用reference handle来进行操作。这里队列的使用在上图中也有表示。
0x11 Execution
现在的很多深度学习的核心就是Tensor的计算,典型的计算密集型应用。所以TensorFlow核心之一也就是如何实现高效的计算,处理前面讲的TensorFlow提供GPU、TPU之类的加速器的统一的抽象之外,如何(利用多个设备)并行执行,分布式训练的也很重要,这里Paper中主要提高这样一些内容,
- TensorFlow任务使用有向图来表示,用户编写的TensorFlow程序中,每次TensorFlow API的调用称之为step。TensorFlow可以执行对个step的并行执行,在必要的时候需要同步的操作。上图表示中,一个训练任务被划分为多个的子图,不同的子图可以并行的执行,其之间通过共享的Variables和Queue来进行交互。多个并发step的执行基于输入的批量处理,这个在很多的处理相关任务的思路中采用。
- TensorFlow使用在不同的子计算/subcomputation显式的通信来简化分布式地执行,方便一个Tensorflow的任务的不同部分运行在不同的设备之上,比如CPU、GPU or TPU。这里不同的计算的实现具体根据设备来实现,而且不同的设备还可以使用不同的CPU,这个也是使用一个统计的数据模型表示的好处之一。一般情况下,将什么样的计算任务放置到那个设备上面运行有系统自己使用一种启发式到方式决定个,另外也可以手动指定。
- 动态控制流,迭代执行的支持在例如执行RNN类似的算法是很有用,另外一些计算的条件执行也是有意思的功能,比如在实现LSTM的时候,里面的“门”如果是关闭的,则一部分的计算可以直接跳过。这里对外提高的是map(), fold(), 和 scan() 这样的API,在数据流中可以添加if语句/条件操作和while语句/循环操作。在内部实现的实现,核心的概念是Switch 和 Merge ,前者类似一个demultiplexer,有一个数据输入和一个控制输入,用控制出入决定哪一个输出被最终输出,而后者的功能相反,类似于一个multiplexer,将多个输入转发到一个输出,如果两个输入都是dead value,则输出dead value。条件操作/ conditional operator使用Switch操作,根据运行时的一个bool类似的tensor来决定运行两个分支中的哪一个。而Merge将分支的输出组合到一起。而循环操作涉及到更多的内容,比如Enter, Exit, 和 NextIteration 操作等。
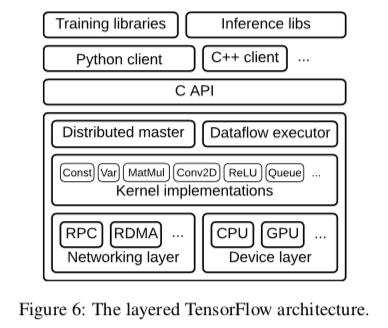
TensorFlow的总体架构如下,从这篇Paper中将的内容来看,也没有太多特别的地方。更多的内容还是在实现上面。
0x12 评估
这里的具体信息可以参看[2].
参考
- Naiad: A Timely Dataflow System, SOSP ‘13.
- TensorFlow: A System for Large-Scale Machine Learning, OSDI ‘16.
