Durability with BookKeeper
0x00 基本架构
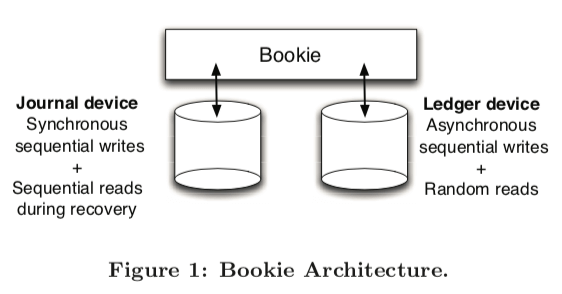
BookKeeper就是一个分布式的journal,多使用顺序写顺序读的方式操作。BookKeeper中几个基本的概念,1. Bookie,即BookKeeper中的的一个存储服务器,在其上保存了ledger fragments;而Ledger 是一个log文件的抽象,保存了一个entry的序列。这里的entry的是BookKeeper的一个基本的数据单元,使用一个sequence id来标识。客户端则是作为应用和Bookie交互的中间角色。BookKeeper中一个Ledger在同一时刻是允许一个客户端写入,可以允许多个客户端读取。而且BookKeeper保证一旦一个Ledger被关闭,所有的客户端读取的entries的顺序都是一致的。在数据的存储上,这里有特点的一个地方是使用两个分离的设备分别保存Bookkeeper的Journal和Ledger,前者为同步写入,没有索引,而后者为异步写入,并添加了索引。
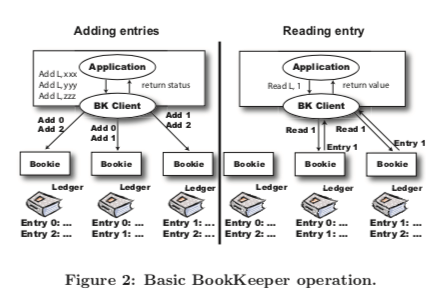
Bookkeeper提供的一些基本操作如下,
• Create a ledger;
• Add entries to a ledger;
• Open a ledger for reading;
• Read entries from a ledger;
• Close a ledger to prevent further writes; • Delete a ledger.
-
Create a ledger;Bookkeeper可以容忍在一个f+1副本中,f个副本失效。应用测试创建一个ledger的时候,客户端负责那些可用的Bookie来保存这个ledger。这些信息被当作ledger元数据的一部分被保存下来。元数据被保存在Zookeeper中;
-
Add entries to a ledger,这里写入的方式客户端将这些写入请求发送到Quorum的成员中,也就是说客户端负责和每个Bookie交互将一份数据写入到多个副本,而不是写入其中的一个副本然后由这个副本复制数据到其它的副本的方式。ledger writer会使用RR的策略来打散写入请求。从一个ledger读取一个entry的时候,客户端通过同样的模式来获取到那f+1个bookie保存了这个entry。这里读取的时候选择其中的一个读取即可。这样就只能读取完成写入的entry,这里完成写入被定义为被成功复制到f+1个副本之上。当客户端通知应用一个entry完全完成写入的时候,这里将样的已经通知了应用的称之为confirmed 。在这篇Paper之外的另外一些资料中,有将一个可用的Bookie集合称之为Bookie assemble,而选择写入一个entri的集合称之为Write Quorum/最小写入数,满足要求数量ack的副本数量称之为Ack Quorum/最小响应数。
-
Close a ledger to prevent further writes。假设一个ledger的已经写入到x+1的位置,但x+1的位置只是部分完成。这样的可能有两个客户端读取的时候一个认为目前写入到了x,另外一个认为写入到了x+1,造成两者之间的不一致。而关闭操作可以解决这个问题。在关闭ledger的时候,会讲最后一个成功写入到entry的信息保存到zookeeper中。这里要处理的一个问题就是这些信息在还没有保存到Zookeeper中客户端就crash掉了。
-
Ledger recovery,ledger recovery机制就是用于处理这样的问题。在ledger的writer crash导致的reader无法确定ledger的最后的一跳记录的情况下。如果reader通过查看ledger的元数据发现ledger的状态没有被关闭,则触发一个recovery 过程。恢复过程为了确认ledger的最后一个entry,会从头开始读取entries,补齐达到合法副本数量但是没有到所f+1的entry的副本的数量。当然这样的速度会比较慢,Bookkeeper会有一些加速的操作,
To speedup recovery, the client sends the identifier of the last entry that has been confirmed along with each add request. The first step of recovery for a given ledger consists of having the reader client asking each bookie in the ensemble for the *last add confirmed* (LAC) field in the last entry that the bookie has processed for the ledger. -
Fencing,在ledger recovery操作的时候,可能存在的一种情况是一个成功写入了一个id更大的entry,这样这个更大的id就会被视为新的末尾。这样通过恢复操作获取的结尾id‘ 和目前被writer更新的结尾id就会不一致,导致错误。解决这种情况通过为ledger添加一个fencing 的标记来避免后面在这个ledger之上的写入操作。这里其实可以看作是一种脑裂的异常情况。
-
Open a ledger for reading,and Reading from an open ledger。从一个已经关闭的ledger上面读取数据是trivial的。另外Bookkeeper还支持从一个没有关闭ledger上面读取。打开正常的没有关闭的ledger读区的时候,不需要出发恢复操作。另外为了避免读区到部分写入的数据,这样读区的时候需要获取LAC的信息,在读区小于这个LAC的entry的情况下就会是安全的。
-
Multiple ledgers。在写入Journal Device的时候,Bookie只有在确认数据持久化的时候才返回ack。这里的Journal被所有的ledger贡献。Journal device有利于写入,而ledger device则更加有利于读取,这里会为每个ledger维护一个entry id到entry log位置的索引。而索引会被缓存在内存中。目前Bookkeeper的使用的策略是将不同的ledger写入到同一个文件中,避免之前使用的不同ledger写不同的文件造成的随机写的问题。这里也可以看作Bookkeeper中一个ledger的entry在物理上面的顺序和逻辑上面的顺序是强耦合的。
0x01 评估
这里的具体信息可用参考[1].
DistributedLog: A high performance replicated log service
0x10 基本架构
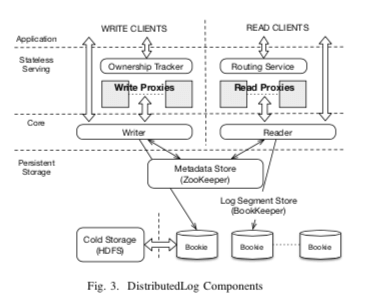
DistributedLog是在Bookkeeper之上构建的一个分布式日志系统,类似的基于Bookkeeper的还有Pulsar。在DistributedLog 中,一个log stream作为操作的基本单元,为一个全局有序、只追加写的log记录序列的抽象。一组的log记录被写入到一个log segment中。Log segment就是一个log stream拆分为段,一个处于in-pregress状态的segemnt用于目前的写入。在这个segment达到Completed的条件的时候,会切换到下一个。这里切换的策略可以根据时间的周期性切换策略,也可以根据segemnt大小的切换策略。在DistributedLog,Log记录被按序写入到log stream中,。每一个记录有一个DLSN标识,这里DLSN中会包含:a Log Segment Sequence Number, an Entry ID (EID), and a Slot ID (SID) 。也就是说记录的顺序有DLSN的决定。另外,这里还有一个Transaction ID的概念,Transaction ID是一个递增的整数ID,用于满足一些application-specific的要求。比如用于标记被添加到log stream的时间戳。DistributedLog的基本架构如下,主要有下面的几个组件,
- 持久化存储组件,包括,1. Log Segment Store,使用Bookkeeper来实现。实现数据持久化和高可用的核心部分;2. Cold Storage存储,使用HDFS。 Log Segment Store中的数据在一段时间之后会被转移到HDFS中;3. Metadata Store,只用Zookeeper,保存log stream和log segemnts的映射关系,以及其它的一些元数据。
- Core。Core组件使用DistributedLog的数据模型和单写者多读者的语义。Writer会讲log记录顺序写入log stream,在同一个时间,一个log stream只会有一个可写/active的log segment。而reader会从一个位置开始(通过DLSN or Transaction ID来决定),顺序地“消费”这些log记录,并可支持exacutely-once语义。
- Serving组件,这里是无状态的。主要就是一个WriteProxy组件和ReaderProxy组件。其中WriteProxy组件用于处理写入,满足写存储层的Log Segment的时候只有一个写入。一个Log Stream在一个时间点最多只会有一个的owner,只有owner才能写入数据。Owner的确定使用的基于Zookeeper的一种租约机制,没有太多特别的地方。owner-ship tracker追追踪log stream的owning信息,并处理WriteProxy的故障。而ReadProxy负责讲读取请求路由到存储层的正确位置(这里使用一致性hash)。并会缓存最近的一些数据。
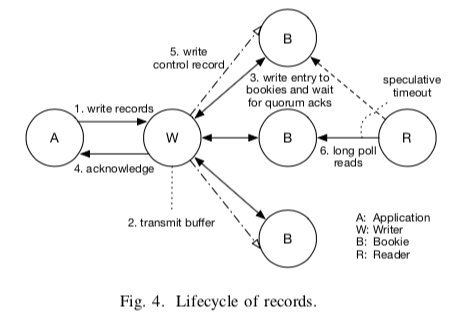
一个Log记录的生命周期如下图所示,
0x11 其它
在这里,补充来在上面的Bookkeeper的Paper中没有详细说明的Bookkeeper的LAC (LastAd-dConfirmed)机制。基本的LAC机制如下,一个批量的记录被追加到log segment中。每个entry会被赋予一个单调递增的entry id/eid。这里eid会在writer请求发送之前决定。然后writer会更新LastAddPushed信息,表面最近的以及被发送出去写请求。这些entries可以被乱序处理,但是ack的时候必须是按照eid顺序来。一个entry被ack持久化了,就会更新LAC (LastAddConfirmed) 的信息。只有在LAC前面的记录才能被reader安全读取。在一段时间内没有写入的话,wirter会自动写入一个control record用于推进LAC,
The control record is added either immediately after receiving acknowledgement or periodically if no application records are added. This behavior is configured as part of the writer’s flush policy. While control log records are present in the physical log stream, they are not delivered by the log readers to the application.
另外,上面一篇只是简单提到的fencing机制在这里也有更加详细的说明。一个基本操作过程图如下,
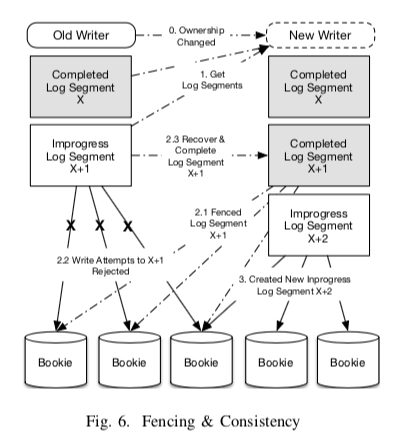
为了更好地支持跨地域复制,DistributedLog引入了一个region的概念。Region被视为一个独立的故障域。全局的元数据使用Zookeeper来实现。另外在数据写入、访问的时候,使用了一种Region-Aware的策略。一个Region内的写客户端通过本地的Write Proxy来获取一个LogStream的Owner信息,实现一个类似路由的效果。Reader会更加倾向于请求本地的Reader Proxy。在持久化数据的时候,可以设置一个minRegionsForDurability参数。只有数据在不小于这个参数值的Region中持久化之后,才能被认为持久化成功。多数情况下,Reader都是从本Region读区,不使用本地的数据的时候,读取另外的Region会优先考虑更近的区域。
0x12 评估
这里的具体信息可以参看[2].
参考
- Durability with BookKeeper, LADIS Workshop ’12.
- DistributedLog: A high performance replicated log service, ICDE ‘17.
