EROFS: A Compression-friendly Readonly File System for Resource-scarce Devices
0x00 基本思路
这篇Paper中描述的EROFS在很多相关产品上面已经得到了应用,宣传上面也挺有意思的。这篇Papper中描述的主要是EROFS的两个内容,1. 固定压缩后大小输出的压缩方式,2. 以及在资源受限的设备中(EROFS主要面向的是智能手机,不过感觉现在的智能手机也称不上资源受限了吧(。・ω・。)ノ),如何使用更少的资源,比如内存,来进行解压缩的操作。
- 固定压缩之后大小输出的策略。之前类似的系统采用的策略是固定大小的输出,这样导致的问题是压缩大小是不确定的,另外的一个问题是读取的时候读放大比较严重,而且会消耗的内存比较多。ERFOS使用滑动窗口的方式来压缩原始的数据,每次压缩一个chunk,chunk的大小不固定,但是压缩之后的大小得是固定的。这里要处理的一个问题就是找打这个chunk的大小,知道其压缩之后的大小为4K的大小。
- 压缩之后保存数据之后的文件系统要处理的另外一个问题就是在读取的时候的解压缩策略。EROFS使用了两种策略,cached I/O 和 in-place I/O,前者会将数据先解压缩到inode对应到的一个Page Cache中,在读取的时候直接将请求导向这个Cache的数据即可。而后者的策略是利用了读取请求带有的Buffer,在读取的时候,VFS会先分配一些内存Pages来作为Buffer,EROFS这里就直接利用这些Buffer来保存解压缩之后的数据,避免额外的内存分配。
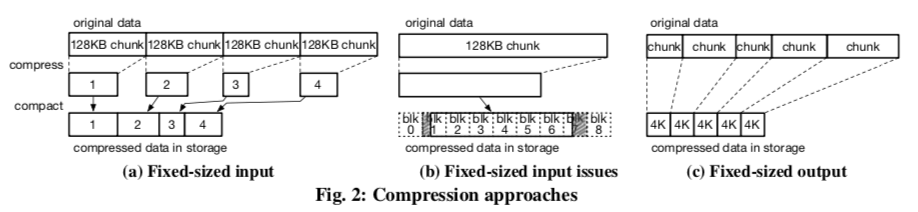
EROFS在解压缩的处理上面也使用了不少优化策略,下图是EROFS,(a)中原始的数据被压缩为两个压缩块,D5在压缩的过程中被拆分。如果是为了读取D3 和 D4。这个操作的步骤如下,1. 读取C0,这里只要解压缩这个C0就可以了,2. EROFS会分配三个连续的Pages来保存D0-D2,而D3和D4会直接利用请求使用的Page Cache,3. 压缩算法要求连续的内存,这里就使用vmap将两段内存映射一段连续的内存,4. 这里在处理的时候,要拷贝C0一次,避免C0在这个过程中被修改,另外C0也是使用Page Cache的Page来保存的,5. 解压缩操作完成之后,就可以vunmap,D0-D2的数据也可以释放。这样的基本策略有两个问题,一个是仍然需要分配物理Pages,另外一个就是使用vmap机制并不十分高效,EROFS有使用了另外的一些优化策略,
-
Per-CPU buffers,在解压缩后的数据不大于4个Page的时候,会将这些数据解压缩到per-CPU buffers中,然后在拷贝到Page Cache中,如下图中的(c)所示。通过重复利用这个per-CPU buffers来减少内存分配的动作;
-
Rolling decompression,这里的基本思路分配一个64KB/16Pages的大小。一些情况下吗在解压缩了64KB之后,可以重新利用这段内存,即一种循环利用的方式,
EROFS uses LZ4 as the compression algorithm, which needs to look backward at no more than 64KB of the decompressed data. ... For example, in Fig. 4, the virtual addresses to store blocks D0 to D15 are backed by the 16 physical pages. The virtual page of D16 can be backed by the same physical page with D0 since each virtual address in D16 is 64KB away from the corresponding address in D0.
0x01 实现
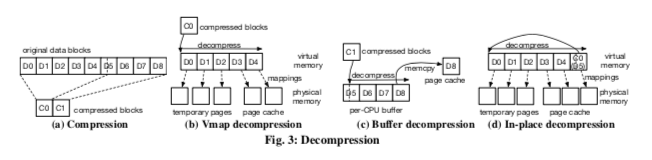
EROFS已经被合入了Linux Kernel主线。目前的实现上,ERFOS使用LZ4压缩算法,这个算法的特点的压缩、解压缩的速度很快。Page的大小为最常见的4KB,一个有特点的地方是ERFOS使用元数据和数据一起保存的策略,基本的结构入下图所示,这样布局的一个优点是更高的局部性。以及文件保存的时候,前面的部分是元数据的部分,后面是文件的数据,中间有一个Block Index,用于记录处理读取请求,记录了压缩块和原始块之间的对应信息。这样读取其中的一些块的时候,可以快速确定是在哪些压缩块包含了,只要解压缩这些块即可。另外在实现的时候EROFS采用的优化方法,
-
一些情况下,很多的原始Blocks被压缩为一个压缩块。而EROFS中原始块和压缩块的对应关系会使用指针,这种方式在这种情况下会消耗不少内存,这里的一个实现上的优化策略是利用VFS分配的最后的一个Page保存压缩块,而对应信息保存在前面的块中,在实际解压缩的时候,就将这些对应信息转移到stack上面,之前的内存用于保存解压缩之后的数据;
-
不使用使用指定线程解压缩的策略,直接使用reader线程;
-
不同线程请求到同样的压缩块的时候,后面的线程可以直接等待前面的线程解压缩完成;
-
EROFS作为一个只读文件系统,典型的应用是写入一次之后就只读。但是EROFS还是提供了一些更新文件的方法,
Instead of modification in-place, image patching places updated data at the end of the EROFS image, and when the corresponding file data blocks are requested, the origin data blocks are firstly decompressed and then the updated data is applied to overwrite the decompressed data in memory.
File System Design for an NFS File Server Appliance
0x10 基本设计
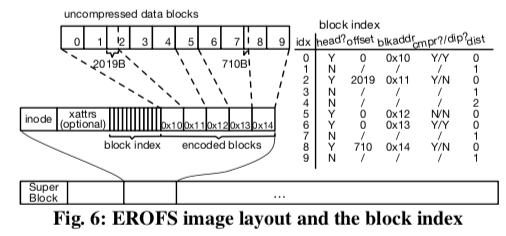
这篇Paper的年代比较久了,描述的是WAFL文件系统的基本设计。WAFL是一个CoW的文件系统,WAFL另外的一个特点是将文件系统的元数据当当做一个文件来保存。将元数据当做一个文件来保存的一个优化是WAFL可以将文件系统的元数据写入到磁盘的任何地方,而不是和FFS之类的系统一样保存在磁盘上面一个固定的区域,这个基本的设计是WAFL名字的来历,即Write Anywhere File Layout。这样设计另外的一个好处是可以动态对文件系统的大小进行调整,在系统中添加一个磁盘的时候,可以直接通过改变元数据文件来实现,而FFS之类的设计在拓展磁盘数量上面就比较麻烦。WALF逻辑结构如下图所示,Block被组织为一个树形的结构,root就是文件系统的root inode,通过root inode就能够找到文件系统中其它的所有的文件、文件夹。系统启动的时候必须一开始就知道root inode的位置,索引WAFL的root inode是保存在固定的地方。WAFL中inode file保存inode,当保存不下需要保存的inode,则引入一个inode file indirect block,用于保存inode file data blocks的位置信息,也是会形成一种树形的结构。对于普通文件的Data Block也是同样的保存思路。WAFL中用block-map file来记录系统中block的使用情况,inode-map file用于记录空闲的inode的信息。和FFS中使用一个bit标记空闲与否不同,WAFL会使用不止一个bit,保存更多的信息。在这个基础上面WAFL的几个设计,
-
使用NVMM来保证File System Consistency,WAFL在90年代就是NVMM来实现更高性能的持久化性能。WAFL通过没几秒钟创建一个特殊的snapshot,consistency point,来实现文件系统的Consistency保障。这个snapshot和一般的不同,它没有名字,对外不可见。在两个consistency point之间,WALF会保证磁盘上面的数据是一致的,这段时间内的操作信息被保存到NVRAM上面的log中,在故障重启的时候,通过重放log中的记录来恢复到一个一致的状态。
WAFL actually divides the NVRAM into two separate logs. When one log gets full, WAFL switches to the other log and starts writing a consistency point to store the changes from the first log safely on disk. WAFL schedules a consistency point every 10 seconds, even if the log is not full, to prevent the on-disk image of the file system from getting too far out of date. -
Write Allocation,这里的具体描述在这篇Paper发表20多年后的一篇Paper中。
这篇Paper中着重将了WAFL的Snapshots功能。WAFL的Snapshots功能就在WAFL的树形的组织结构上面实现,在创建一个Snapshot的时候,WAFL会创建一个新的root inode的副本,这个inode就代表了文件系统的snapshot,在创建的时候,其能够表示的内容和之前的inode是完全一样的。在后面更新文件系统内容的时候,WAFL的CoW功能就和snapshot的实现紧密相关,基本思路如下图。
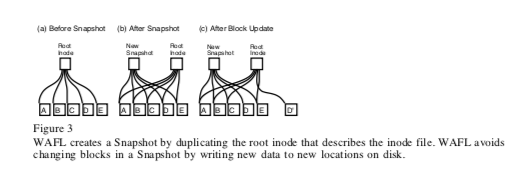
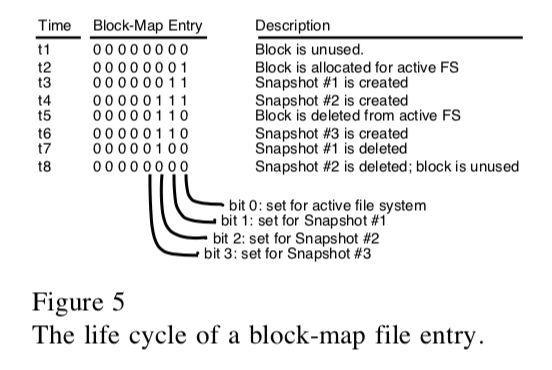
Block-Map File记录了Block的使用情况,WAFL中使用32bit来记录,而不是单个bit。第0个bit记录目前活跃的snapshot是否使用来这个block,第1个记录之前的snapshot使用这个block的情况,依次类推。下图是一个block被使用过程中的操作逻辑。在创建snapshot的时候,WAGL想要保证不能阻塞正常的请求。如果一个新的请求需要改变已经被cache中内存中,但是是属于上一个snpashot的数据,因为这个数据不能变又这个数据没有刷到磁盘上面。所以不能直接修改这个数据。WAFL的做法是对这样的数据标记一个IN_SNAPSHOT,这样的数据在flush到磁盘之前不能更新。如果需要更新这些部分的数据,需要先将其刷到磁盘。为了加速这个flush的操作,WAFL进行来这样的一些优化。
Scalability in the XFS File System
0x20 基本设计
这篇Paper描述的是XFS的基本设计,也是上个世纪90年代的文章。XFS在结构设计上有几个特点:日志式的文件系统,更新操作先记录到日志中然后在实际操作,实现更高的文件系统一执行,已经从Crash中快速回复。使用几个extent的文件空间管理方式,与在FFS之类的系统中基于block,每个block使用bit来标示其使用状态的不同,在XFS中,空闲的空间使用一个B+-tree来管理,这个B+-tree每个entry为一个start-block加上一个length。如果是连续的一个空间,则只需要一个extent,而FFS bitmap的方式需要的bitmap数量和Blocks的数量成正比。除了这个B+-tree之外,XFS中使用另外一个B+-tree来查找空闲空间,这个的Key是extent的长度,在需要分配一定大小的空间的时候会用到。XFS和FFS类似的事引入了AG,allocation group的概念和空间管理方式,这个FFS中的cyclic group类似。XFS中频繁使用到B+-tree,除了空闲空间的管理之外,还在很多地方使用到B+-tree,
-
XFS是一个64bit的文件系统,支持超大的问题。为了更好地支持大文件,同样适用B+ tree来管理一个文件的extent。这个B+ tree中的每个entry包括,这个extent在在文件的offset,这个extent从哪一个block开始以及这个extent的长度。在extent比较大的情况下,这样的管理方式可以有比FFS的方式少得多的文件元数据。同样的,使用B+ tree这样来管理,XFS也支持稀疏文件;
-
XFS使用动态分配inode方式,而不是像FFS那样在磁盘固定的区域分配一个预留的空间来保存inode。XFS每次inode分配以64个为单位。使用一个inode allocation B+ tree来记录这些保存inode的chunk的位置以及一个chunk内inode的使用情况。
-
XFS为了支持很大的目录,也使用B+ tree来管理目录的内容。The directory B+ tree记录目录的内容,其key是文件 or 目录的名字,最大支持255bytes大小。实际使用的时候使用了名字的一个hash值,而将具体的信息和inode number保存在value中的优化方式,
the directory entry names are hashed to four byte values which are used as the keys in the B+ tree for the entries. The directory entries are kept in the leaves of the B+ tree. Each stores the full name of the entry along with the inode number for that entry.
0x21 性能优化设计
Paper中总结了一些XFS性能上面的优化设计,
-
XFS会尽量尝试分配联系的空间。这里引入了延迟分配的技术,XFS中延迟分配的引入比ext文件系统早得多。与在写入到内核buffer cache中就分配磁盘blocks不同,这里只是先将其cache在内核的buffer cache中。XFS会预留出一些blocks来处理这些数据的写入,预留的一般情况下应该用不到。在这些数据实际刷到磁盘的时候,延迟决定了这些数据写入的位置,就能加有了可能将写入的数据保存到连续的空间中。
When the entire file can be buffered in memory, the entire file can usually be to be allocated in a single extent if the contiguous space to hold it is available. For files that cannot be entirely buffered in memory, delayed allocation allows the files to be allocated in much larger extents than would otherwise be possible. -
XFS中extent可以支持几百万基本的blocks大小,将20byte的数据压缩保存到16byte的空间之中(20 bytes (8 for file offset, 8 for the block number, and 4 for the extent length)。
-
这篇Paper中认为虽然XFS很难避免文件系统的碎片化问题。但是XFS的一些设计会缓解这个问题:1. XFS使用两个B+ tree来管理内存空间,加上延迟分配的技术,可以实现更好的best fit的策略。2. XFS可以比FFS有更大的空间,更多的空间更不容易出现碎片化的问题。
-
在读优化上,XFS的策略是使用更大的read buffers和multiple read ahead buffers的机制。这篇Paper描述的时候read buffer在XFS中默认为64KB,读小文件的时候会减小这个buffer的大小。另外的就是比较激进的read ahead机制,在 primary I/O buffer会read ahead几个并发的请求,
XFS uses multiple read ahead buffers to increase the parallelism in accessing the underlying disk array. Traditional Unix systems have used only a single read ahead buffer at a time. For sequential reads, XFS keeps outstanding two to three requests of the same size as the primary I/O buffer. -
写优化上面,XFS使用了一个aggressive write clustering的策略,即将dirty file data缓存在内存中,64K为一个chunk。在写入磁盘的时候,尽量将chunks顺序写入到连续的空间。
-
….等等。
在[4]中提到之前XFS在频繁更新metadata的workload中性能不是很理想,并提到了这个问题的一些优化方式,其中核心的就是Delayed Logging。基本思路是Delayed Logging,即怎么样推迟更新之后的文件系统元数据写入磁盘,实现更少的磁盘写入操作。具体的实现当然不会很简单,在Linux Kernel 的Documentation/filesystems/xfs-delayed-logging-design.txt中有描述。
0x22 评估
这里的具体信息可以参考[3, 4].
参考
- EROFS: A Compression-friendly Readonly File System for Resource-scarce Devices, ATC ‘19.
- File System Design for an NFS File Server Appliance, ATC ‘94.
- Scalability in the XFS File System, ATC ‘96.
- https://xfs.org/images/d/d1/Xfs-scalability-lca2012.pdf, XFS: Adventures in Metadata Scalability.
