Many faces of Hash Function
总结一波各种各样的Hash Function。
0x01 Rolling Hash
Rolling Hash是一个很有意思算法,其解决的问题是在知道了字符串hash知乎,快速地计算出其一些字串的hash值,可以避免重新计算这些字串的hash值。在一个常见的字符串匹配算法Rabin-Karp算法中就用到了一种Rolling Hash。这里的基本思路很简单,用三个式子就可以表示清楚。(1)表示一个字符串从0到i的字串的hash值的计算方式,(2)表示0到j的字串,假设j > i。(3)就表示i到j的字串的hash值的计算方式, \((1). hash[0:i] = s[0]*a^{i-1} + s[1]*a^{i-2} + \cdots + s[i-1]*a^{i-1}. \\ (2). hash[0:j] = s[0]*a^{j-1} + s[1]*a^{j-2} + \cdots + s[j-1]*a^{j-1}. \\ (3). hash[i:j] = hash[0:j]- hash[0:j]*a^{j-i}.\) 这样可以用一个数组记录0到i的hash值,就可以快速计算出其中任意字串的hash值了。这样如果是用于计算一个字符串上面一个固定窗口大小的字串的hash值,可以用如下的思路。w为窗口大小。 \(hash[k-w:k] = (\cdots)\mod m. 已经计算出。\\ hash[k-w+1:k+1]= [(hash[k-w:k] - a^{w-1}*s[k-w])*a+s[k]]\mod m.\) Rolling Hash除了用于字符串匹配之外,另外一个用途是找到两个文件中相同的部分,在deduplication和 delta同步之类的应用中可以使用到。另外一个Rolling Hash的例子就是buzhash,其基本的思路如下,用移位的方式代替了乘法,在很多情况下可以有更好的性能表现。Buzhash使用的是称之为Cyclic Polynomial的思路[2],循环多项式。hash函数h表示将一个字串映射到一个[0, 2^L)之间的一个整数。字符如果是char类型,这样总共就256个值,可以直接使用一个随机数的数组。s表示循环右移,s(10011)=00111,⊕表示xor。则hash值H定义为 \(H=s^{k-1}(h(c_1)) ⊕ s^{k-2}(h(c_2)) ⊕\cdots\) 由一个窗口的hash值H_1往后移动移位计算H_2的逻辑如下,其中c1为窗口移动时候被移去的char,c_{k+1}为移入的char。 \(H_2=H_1⊕s^k(h(c_1))⊕h(c_{k+1}).\)
0x02 Locality Sensitive Hashing
SimHash
SimHash出现的时间也比较晚,02年的Paper[3]中描述了这种类算法。SimHash是一种Locality-Sensitive Hashing,即局部敏感hash。但是[3]中描述的比较难理解,从原理上面分析,emmmm,╮( ̄▽ ̄””)╭。但是从网上找的其它的资料话,SimHash的计算分为5步,
- 对文本进行分词,不同的词会有不同的重要程度,这里对应到的就是不同的词会有不同的权重;
- 对词计算一个hash值。这里对计算hash值的函数好像没有特别的要求;
- 对计算得到的hash进行加权计算,0bit计算为负值,即按照-1乘权重计算,而1计算为正值;
- 将不同词得到上一步的到的向量相加;
- 这里可以看作是第3步的一个逆操作,重新转化为0 1bit的过程。如果一项大于0,计为bit 1,否则为0,得到最终的hash值。
之后两个hash比较的时候比较的是最终hash中不同bit位的数量。具体的原理这里就暂时不分析了,(((o(゚▽゚)o))),
MinHash
MinHash的思路也看上去不是很复杂,其核心是集合中的Jaccard相似度,Jaccard相似读定义为两个集合交的元素数量除以并的元素数量,这样Jaccard相似度的值就在[0,1]的范围。MinHash的操作先把一项数据转化为向量表示。比如存在某个元素,向量对应的位置就为1,否则为0的方式。之后讲这个向量的元素进行随机打乱,类似于这样的操作,这里random_permutation也可以直接使用一个hash的方式代替,
random_permutation = random_permutation_create();// 生成随机的一个排列
foreach v in vectors:
swap(v[i], v[random_permutation[i]])
minHash定义为打乱之后,这个向量第一个不为0元素的位置值,可以证明两个向量minHash相等从概率上就是两个向量的Jaccard相似度。将上面打乱之后取低一个不为0元素的位置值进行n次,这里的n一般远小于向量元素的数量。这样对于每个最初的数据项,有一个n维的minHash向量。计算原始数据想相似度的时候就可以使用minHash向量对应位置相等的比例来表示了。
0x04 GeoHash
GeoHash本质上应该是一种数学上编码的方法,将经纬度的信息编码为一个较短的字符串,而不是一般Hash的那种随意打乱的思路。Geohash最重要的特征是地理上面相邻的部分在编码上也是相邻的。一般情况下,越相近的地方编码之后的的共同的前缀也是相同的。这样就给查询附近的信息带来了很大的便利。GeoHash的编码是一个递归的过程,第一步是开始编码第一次划分经度,这里初始的纬度取值为[-180,180],每次将目前的区间划分为2,如果在数值较大的区间在编码后面添加一个1,否则则添加一个0。第二步是第一次划分纬度,初始的取值为[-90, 90],思路同经度。如果在数值较大的区间在编码后面添加一个1,否则则添加一个0。这样递归进行指导精度满足要求为止。然后将编码之后的0 1序列使用某种编码在编码为字符串,比如使用base32。GeoHash实际上使用下面的编码方式编码位置的一种方式。

这种基本的GeoHash也有一些缺点。上图是维基百科中的一张图,不让图中间的突变的情况,另外就是将地球表面考虑为一个平面,在不同的纬度会有不同的实际距离。另外的一些更加复杂的处理方式能得到更高的效果,比如S2库中采用的方法[5]。
0x05 Rendezvous Hashing
Rendezvous Hashing也称之为Highest Random Weight Hasing。它解决的也是一致性hash要解决的问题。比如一个问题是处理若干客户端的请求如何从多个的后端来处理请求的问题。Rendezvous Hashing的基本思路是对于每一个客户端,每个后端对于其有一个权重,这些权重不同,而且不同客户端是独立的。客户端请求的时候,会选择一个权重最高的请求。当其中的一个后端被移除的时候,只有哪些最高的权重选择这个被移除的才需要进程重新路由的操作。当一个后端被添加的时候,也只有哪些最高权重变为这个后端的需要进行重新路由的操作。从基本思路来说,Rendezvous Hashing,要比常见的一致性hash简单不少。
0x06 Maglev Hashing
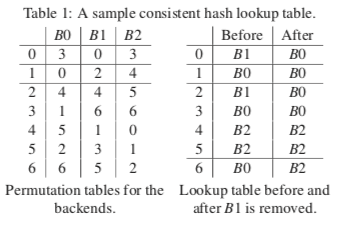
Maglev Hashing是Google在Maglev负载均衡器上面引入的一种一致性hash算法,这篇Paper[7]之前已经看过了,这里更详细地总结一下这里使用的一致性hash的算法。Google发明的另外的一致性hash还有好种。。。。Maglev Hashing的基本思路是填表的方式,在决定转发的时候就是查表的操作。一个例子如下图,有三个backend,有找各自的permutation,可以使用下面的算法生成,当然使用随机的方式也是可以的,
offset ← h1(name[i]) mod M
skip←h2(name[i]) mod (M−1)+1
permutation[ i ][ j ] ← (offset + j × skip) mod M
在生成permutation之后,就是填表的操作,在Before一列,B0第一个为3,Lookup Table的第三项为3,其它的类推。后面的被前面的占用了空间的时候往后顺移即可。一致性hash最重要的还是减少在backend数量变化的时候的映射改动,After一列为删除B1之后的重新填Lookup Table的结构,发现大部分的B0和B2的没有变(第6项有变化),原来的B1的被剩余的占据。可以看出Maglev Hashing的基本思路是通过一个permutation填表的操作来映射到一个位置,即使在Backend变化之后,由于permutation一定,这个映射在大部分情况下不会改变。但是在一部分情况下还是会有一些扰动,比如下面的第6项就是一个例子。如果用Rendezvous Hashing的思路去看待Maglev Hashing的话,可以理解为这里的permutation就是Rendezvous Hashing中权重的排序。
0x07 Social Hash: An Assignment Framework for Optimizing Distributed Systems Operations on Social Networks
Social Hash也是一种叫做hash但实现上和一般的hash差别很大的一种方法。Social Hash主要是为了解决Facebook在应用中的如何partition的问题。在Facebook的社交网络中,不同的用户/组访问的资源是有相关性的,如果将资源根据用户的访问特点进行分区,用户访问的时候能够将其访问路由到其相关性更新的分区,这样能够得到性能和资源利用率的提升。 Social Hash Framework的基本架构如下图。静态的分割模式下面。它的输入有,1. 一个context dependent graph,一个根据用户的friendship graph或者是根据用户access logs得出的一个graph,2. 需要分配给用户组的对象的类型,3. 一个目标函数,4. 需要分割的组数量,5. 可以容忍的不平衡性。处理动态分割,Framework中还可以使用动态的分割,动态分割考虑到了目前系统使用的组件的负载。动态分割的模式下面,还会有,1. 目前系统中组件的负载,2. (可能的)组件的最大的负载,3,每个用户组使用资源的历史负载信息。
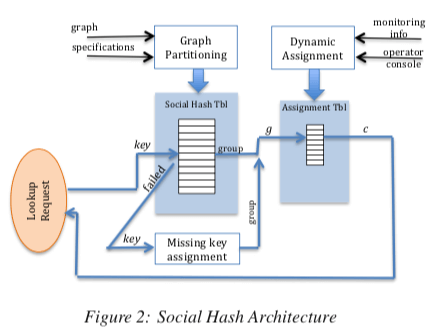
静态的分割策略从一个最初的partition出发,最初的partition可以使用随机partition的方式。这里使用(v, g_v )来表示一个对象v分配给来组g_v,知乎进行重新分配v的操作,分配的选择使得目标函数最小化的group。不同的v计算的时候可以并发进行。动态分割考虑到了组件的负载,这里进行partition的时候主要的考虑因素有,1. 预测的将来的负载,2. 不同纬度的负载,比如CPU、存储等。3. Group Transfer带来的开销,4. 之前分配的历史信息。
参考
- https://courses.csail.mit.edu/6.006/spring11/rec/rec06.pdf
- https://en.wikipedia.org/wiki/Rolling_hash,维基百科.
- Similarity Estimation Techniques from Rounding Algorithms, STOC ‘02.
- https://en.wikipedia.org/wiki/Geohash,维基百科.
- http://s2geometry.io,S2 Library.
- Using Name-Based Mappings to Increase Hit Rates, TOC ‘98.
- Maglev: A Fast and Reliable Software Network Load Balancer, NSDI ‘16.
- Social Hash: An Assignment Framework for Optimizing Distributed Systems Operations on Social Networks, NSDI ‘16.
