Scaling Distributed Machine Learning with the Parameter Server
0x00 基本思路
Parameter Server(PS)是在很多的机器学习框架中会使用到的工具,这篇Paper发表在14年,在前面的出现过的类似Parameter Server服务上面的继续改进。机器学习的各种问题可以抽象为最小化一个损失函数,这里是称之为Risk Minimization。可以表示为, \(F(w) = \sum_{i=1}^n l(x_i, y_i,w) + \Omega(w).\\\) 处理这个常用的就是一些类似梯度下降之类的数值优化算法,Paper中这里就是将其拓展到分布式的情况下,称之为Distributed Subgradient Descent ,以便能够处理一台机器无法处理的参数的数量。基本的逻辑如下,其基本的逻辑就是将数据分发到多个worker上面,每个work分别计算各自数据部分的梯度。Worker在Load数据就是一个迭代的过程,每次计算处理此事的梯度,如何将其push到Server上面,然后在从Servers上面Pull下来更新之后的参数。对于PS中的Server角色,它要副本保存这个参数数据,并汇总Worker的更新,然后分发给Worker。

0x01 基本架构
PS的基本架构如下图,一个常见的分布式系统的设计。两个核心的角色Worker负责计算任务,一组的Servers负责保存参数的数据。PS同时可以运行多个机器学习的任务。一组的Servers使用一致性Hash来将参数数据进行分区,每个Server保存所有参数的一部分。一致性Hash使得在机器发生故障的时候可以减少数据的移动,这个也是PS容错机制的一部分。PS中参数都使用Key-Value对的形式来表示,这个和类似的一些系统是相同的。在基本的Key-Value抽象的基础之上,PS还提出了一些拓展的功能。PS将参数视为 sparse linear algebra objects,可以在其之上实现训练时常用的一些操作,比如计算向量加分w+u,乘法,计算2-范数以及其它的更加复杂的操作。
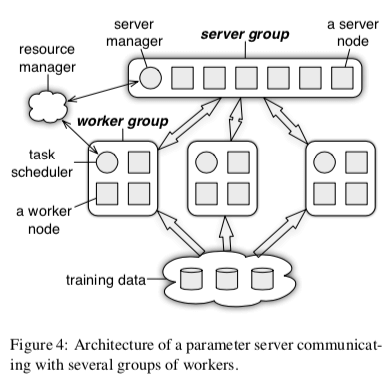
在上面的分布式梯度下降的基本逻辑中,存在Worker和Sevrer之间的数据Push和Pull操作。这种操作下面,批量地处理数据时一个很常见的优化,PS这里将这种优化称之为Range Push、Range Pull。Server节点处理可以执行汇聚Work节点的数据操作之外,用户还可以定义执行的逻辑,user-defined functions,以便用户在其之上实现更加灵活的逻辑。除了user-defined functions,PS中另外一个类似的东西时User-defined Filters,用于控制Worker和Server之间的数据同步。比如在一些情况下,Worker中计算出的结果可以知将会对参数有影响的部分推送到Sevrer,避免一些不必要的数据传输。
- 这种分布式的情况下, Worker和Server之间会有大量的数据交互。如何优化这个操作会对系统的性能有比较大的影响,这里PS提出的方法是异步迭代的方式。Worker在将上一步的结果Push、Pull操作的过程中,就开始计算下一步的梯度计算。这样的优点是将Push、Pull数据传输的过程和梯度计算的过程重叠,提高了性能,缺点就是参数会存在不一致。PS这里还可以定义execute-after-finished依赖逻辑,以便让一个任务的执行只有在其依赖的任务都完成之后才开始执行。
- 异步迭代带来的性能的提升,也带来了一致性的问题,PS这里提出了一些灵活的一执行的处理方式。一些算法对于在上次迭代的结果没有更新而使用旧的参数的时候,可能并没有很大的影响,这样就可以使用最终一致的模型,不同的任务可能同时开始,遇到的不一致的问题可能最严重,适用于一致性不敏感的算法。相反的是顺序一致性的模型,最终模式下面任务为顺序执行,性能差一些,不会有不一致的问题。两种算法之间的Bounded Delay模型,一个任务阻塞到其前t个迭代的任务完成。
0x02 评估
这里的具体信息可以参看[1].
MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems
0x10 基本设计
MXNet是一个用于机器学习的一个框架,是一本有名的开源的关于机器学习书中使用的框架,和前面的PS的作者有很多相同的。MXNet的基本架构如下。包含了基本主要的组件:1. 机器学习算法中很多事BLAS的计算,这里的抽象是NDArray,类似于tensor flow中的tensor,在NDArry上实现向量、矩阵等之间的运输,而Symbolic Expr用于实现MXNet的符号表达式功能,下面是一个用Julia实现的一个使用符合表达式的多层感知机,使用mx.Variable(:data)来声明一个符号:data,类似的语法在其它的一些机器学习的相同中也可以看到。而KVStore则主要在分布式的情况下用于多个设备之间的数据同步,这里的KVStore就是基于前面的Parameter Server实现的一个组件。
using MXNet
mlp = @mx.chain mx.Variable(:data) =>
mx.FullyConnected(num_hidden=64) =>
mx.Activation(act_type=:relu) =>
mx.FullyConnected(num_hidden=10) =>
mx.Softmax()
# NDArray
# while(1) { net.foward_backward(); net.w -= eta * net.g }
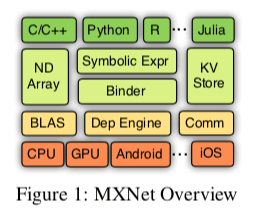
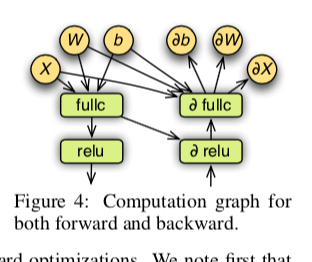
很多类似框架的核心都是高效实现张量之间的运算,以及这些运算之间的逻辑。这里计算的抽象是NDArray,会适配到不同的设备,比如CPU、GPU以及一些移动设备等。逻辑的时间和其它类似的相同的,也是一个基于图的方式。下面是一个简单的例子,同时包含前行传播和后向传播的逻辑。这里还提到了在这里的一些优化策略,比如在一些情况下可以跳过一些计算。一些计算可以被融合起来计算,比如乘法+加法的计算在一些情况下直接使用乘加融合计算。
We note first that only the subgraph required to obtain the outputs specified during binding is needed. For example, in prediction only the forward graph is needed, while for extracting features from internal layers, the last layers can be skipped. Secondly, operators can be grouped into a single one. For example, a × b + 1 is replaced by a single BLAS or GPU call.
MXNet中会将每个source unit(包括 NDArray,随机数生成器 和 temporal space等 )注册到Dep Engine中,用于处理其之间的依赖关系。每个source unit注册的时候带有一个唯一的tag,注册之后,其依赖被满足的情况下,调度器会调度其开始运行。这里还提到将 mutation operations(也就是会改变原来数据的操作)视为一个已经存在的source unit。用于实现一些优化,比如参数更新的时候视为更新之前数组的操作,而不是分配新的内存保存,实现了更好的内存重用。
Ray: A Distributed Framework for Emerging AI Applications
0x20 基本思路
Ray是一种为AI任务设计的分布式执行框架,Paper中主要讨论的是其对强化学习类似的AI应用的良好支持。和前面的相同有比较大的不同。它强调可以低延迟调度百万记的任务,还有简单灵活的Python API。Ray的Python的核心API是几个装饰器和Task、Actor概念。基本的API如下。
| Name | Description |
|---|---|
| futures = f.remote(args) | Execute function f remotely. f.remote() can take objects or futures as inputs and returns one or more futures. This is non-blocking. |
| objects = ray.get(futures) | Return the values associated with one or more futures. This is blocking. |
| ready_futures = ray.wait(futures, k, timeout) | Return the futures whose corresponding tasks have completed as soon as either k have completed or the timeout expires. |
| actor = Class.remote(args); futures = actor.method.remote(args) | Instantiate class Class as a remote actor, and return a handle to it. Call a method on the remote actor and return one or more futures. Both are non-blocking. |
Ray用Task、Actor表示两种类似的计算任务。Task为一种无状态的,其输出只取决于其输入,而Acotr是一种有状态的操作,而Ray将一个本地的应用变成一个分布式计算的任务也很简单。Ray的README.md中给出几个简单的例子,例子如下。在一个普通的Python函数上面添加@ray.remote的装饰器即可实现分布式并行计算。这里的f的输出只取决于其输入,所以是一个Task,其结果用Ray提供的ray.get, ray.wait来获取,
import ray
ray.init()
@ray.remote
def f(x):
return x * x
futures = [f.remote(i) for i in range(4)]
print(ray.get(futures))
而要Actor也在README.md也给出了一个简单的Counter的例子。从这些简单的例子看起来,Ray很有意思。Task、Actor是计算任务的抽象,而任务之间的依赖关系和很多分布式的计算框架一样,也是使用基于图的抽象。Ray支持动态图计算。
import ray
ray.init()
@ray.remote
class Counter(object):
def __init__(self):
self.n = 0
def increment(self):
self.n += 1
def read(self):
return self.n
counters = [Counter.remote() for i in range(4)]
[c.increment.remote() for c in counters]
futures = [c.read.remote() for c in counters]
print(ray.get(futures))
0x21 基本架构
Ray的基本架构如下,Ray目前开发变化迭代挺快的,这篇OSDI‘ 18上面的论文描述的不一定是目前Ray的实现方式,这里讨论这篇Paper中描述的情况。总体上Ray分为System、App两层的架构,其中System负责全局的调度、全局的数据存储。而App层主要用于执行用户的逻辑,
- System层主要的两个组件为Global Control Store (GCS) 和Global Scheduler。GCS保存了全局的状态信息,在下图表示出来的有Object Table、Task Table、Function Table和Event Logs等。GCS本质上是一个支持pub-sub功能的KV Store,通过使用chain replication来实现容错。通过将信息保存在这里,由GCS来实现容错,这样其它的组件更加容易实现为无状态的。有利于容错和这些组件的可拓展。
- App层主要的三个组件是,1. Driver,代表了一个执行用户程序的进程,2. Worker,用于执行任务的进程,是无状态的。Worker由System层启动,任务也有System层分配。而任务的启动由Driver or 其它的Worker触发。Worker顺序执行分配给器的任务。3. Actor,一个由状态的进程,与Worker的差别是其有Worker or Driver实例化,而且会保存状态,其状态会影响到一次执行的结果。
- Ray使用的调度器是一种Bottom-Up Distributed Scheduler。Ray认为中心化的调度器设计无法满足Ray低延迟调度百万记任务的要求。Ray的自底向上的调度器,执行的任务由Worker or Driver提交给Local Scheduler,如果本地可以满足任务运行的需求,则直接由Local Scheduler调度任务执行。在由在本地节点无法满足任务运行的要求的情况下,这个任务会提交给Global Scheduler来处理。这样就形成了Ray的自底向上的两层的调度器设计。能够本地决策的情况下使用本地决策可以实现更低的调度延迟和降低Global Scheduler的负载。
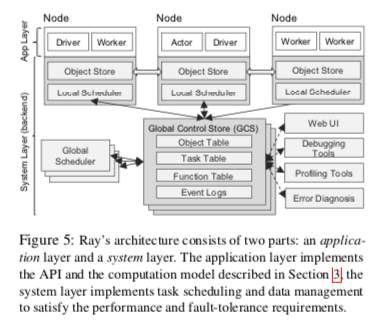
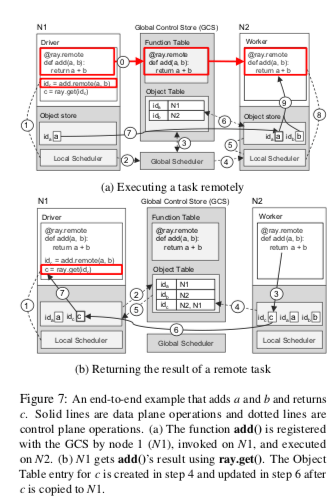
在Ray中执行一个简单的分布式的计算的逻辑如下所示。一个remote装饰的函数会被复制到所有的节点上面保存。在下面的例子中,N1节点提交了一个add的任务给Local Scheduler,由于超出了本地排队任务的阈值,这个任务被转发给Global Scheduler。这里如果没有超过本地的阈值的话,就可以直接在本地执行。Global Scheduler根据一些条件将任务调度到N2节点上面,并且这个节点上面的Object Store中已经保存了add输入的一个参数b,缺少的另外的参数a在N1节点上面有保存,则需要将缺少的参数数据同步过来。然后就可以执行add的操作了。Object Store是一个基于共享内存的保存不可变数据的In-Memory存储系统。N1节点上面的用户逻辑调用ray.get的话,会触发Drvier去查看本地的Object Store有没有add结算结果c,如果没有则去查询GCS。如果此GCS中没有c,则注册一个回调函数,监听c的事件。N2上面任务被执行完毕之后,结果c被保存到本地的Object Store中,也会上传到GCS中,此时触发回调,N1就可以取回结果c。
另外Paper中也给出了利用Ray的API实现简单的强化学习的例子,能基本看出其使用起来的逻辑,
@ray.remote
def create_policy():
# Initialize the policy randomly. return policy
@ray.remote(num_gpus=1)
class Simulator(object):
def __init__(self):
# Initialize the environment. self.env = Environment()
def rollout(self, policy, num_steps):
observations = []
observation = self.env.current_state()
for _ in range(num_steps):
action = policy(observation)
observation = self.env.step(action)
observations.append(observation)
return observations
@ray.remote(num_gpus=2)
def update_policy(policy, *rollouts):
# Update the policy.
return policy
@ray.remote
def train_policy():
# Create a policy.
policy_id = create_policy.remote()
# Create 10 actors.
simulators = [Simulator.remote() for _ in range(10)] # Do 100 steps of training.
for _ in range(100):
# Perform one rollout on each actor.
rollout_ids = [s.rollout.remote(policy_id)
for s in simulators]
# Update the policy with the rollouts.
policy_id =
update_policy.remote(policy_id, *rollout_ids)
return ray.get(policy_id)
参考
- Scaling Distributed Machine Learning with the Parameter Server, OSDI ‘14.
- MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems, https://www.cs.cmu.edu/~muli/file/mxnet-learning-sys.pdf.
- Ray: A Distributed Framework for Emerging AI Applications, OSDI ‘18.
