Ubiq: A Scalable and Fault-tolerant Log Processing Infrastructure
0x00 基本架构
Ubiq是Google实现的一个Log Processing系统,这里的Log是一个应用被使用过程中产生的一系列的事件。这里也将这样连续产生的事件数据也称之为data stream。之前Google有过一个类似的Photon系统,Ubiq这篇Paper还特意比较了和Photon之间的不同。Ubiq的基本架构如下,Ubiq假设事务输入先被写入到一些文件中,这里保存事件的文件创建逻辑、写入逻辑等不在Ubiq的范围之类,Ubiq使用一个Log Data Tracker组件来监控这些文件上面的操作,在有新的创建 or 数据写入的时候可以开启处理数据的逻辑。
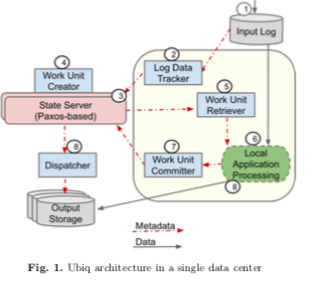
在Log Data Tracker探测到新数据到达的时候,相关的元数据filename 和 目前的offset等被作为元数据写入到State Server保存。State Server是一个基于Paxos的存储系统。持续进来的数据会被Work Unit Cretor打包为一系列的event bundles来处理,这个就是一个批量事件的抽象。之后这里event bundles被Work Unit Retriever拉取,进入业务处理逻辑,在这里数据被特定的业务逻辑处理,输入log数据,输出结果。在业务逻辑处理完成之后通过Work Unit Committer来提交处理的结果。Ubi实现的是exactly-once的语言,使用要在数据输入、业务逻辑结果输出等的地方都有重试和去重的逻辑。所以相关的业务结果如果不是确定性的话需要Work Unit Committer进行提交的操作,有Dispatcher使用两阶段提交的方式完成结果的写入。而如果业务逻辑处理的结果是确定性的,Local Application Processing可以直接将结果写入到Output Storage。
0x01 单数据中心和多数据中心
对于输入文件,Ubiq期望其不同的副本可以达到一个最终一致的状态,byte级别的一致。输入文件有多个副本的情况下,任意时刻这些文件可能是不同,如果两个副本S1、S2其中,S1 size < S2 size,前面S1 size的数据得是相同的。能实现这种保证是很有意思的,不过这篇Paper中没有提到。Ubiq处理的数据起始于输入文件,而Ubiq大部分的组件都是stateless,而存储数据的核心就是State Server,在这其中保存的一般是数据处理过程中的元数据。比如输入数据的哪些已经处理完成了,哪些还没有处理,很多的机制和exactly-once语义相关。对于一个输入文件和其一个offset,可能处理三种状态;1. 还没有作为一个work unit开始处理,2. 已经开始处理,3. 处理完成,结构已经保存到Output Storage。数据保存的时候,用<filename, begin offset, end offset>这样的形式来保存,状态系统的连续的部分会被状态合并。
-
Log Data Tracker,Log Data Tracker组件负责将监控输入文件的增长。新创建的文件和已经存在的文件被追加了数据等情况,相关的input files的信息被保存到State Sever中。Log Data Tracker一般独立部署在和input files同一个数据中心。由于要实现exactly-once的语义,Log Data Tracker重试的操作是难免的,而State Server必须对数据进行去重处理。所以Log Data Tracker的操作方式是重试到State Sevrer确认为止。
-
Work Unit Creator作为State Server中的后台工作线程,它将数据数据打包为一个个event bundles,作为一次处理的一个batch。Work Unit Creator会维护每个input files已经增长到的大小,以及event bundles创建已经达到的offset。Work Unit Creator是使用的时候也有一些优化措施,比如提交最老的没有处理数据的优先级,从input file的多个副本中并发读取等。
-
Work Unit Retriever 和 Work Unit Committer在Ubiq中的位置如上面的架构图。这两个组件的存在将业务处理和Ubiq内部的处理逻辑分割开来,同样也可以理解为将业务处理理解和Ubiq连接起来。Work Unit Retriever从State Server中取回目前还有处理的Work Unit,而Work Unit Committer负责提交结果。Dispatcher主要是为了处理数据处理的结果不是确定性的情况。如果一个数据处理之后的结果是确定性的,则直接有Local Application Processing保存到Output Storage上面即可。但是如果不是的话,要避免结果副本存在不同的情况以及实现exactly once的语义。Dispatcher支持通过两阶段提交的方式将结果写入Colossus文件系统 or Mesa这样的数据仓库中。
-
Garbage Collector。由于要实现exactly once语义,Ubiq必须等到确认结果已经持久化之后才能将输入数据删除。这里引入的组件就是Garbage Collector,
... a background thread in the State Server is responsible for garbage-collecting the work unit and all the metadata associated with it. This thread also garbage-collects input filenames once these get older than a certain number of days (e.g., d days) and they are fully processed.
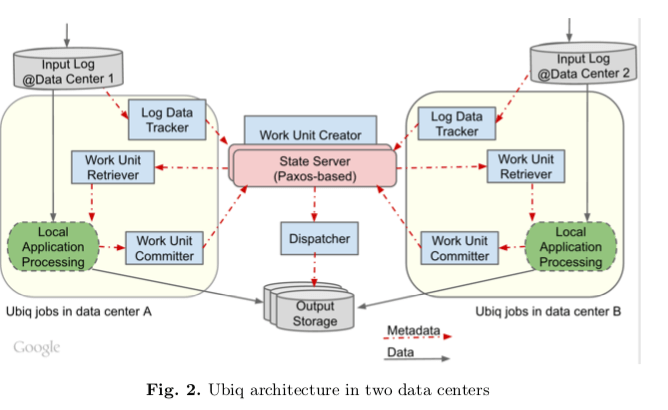
上面的架构图和提交的组件都是在同一个数据中心内的情况。Ubiq得支持跨数据中心部署。Ubiq支持多数据中心数据的核心设计还是在无状态的组件设计和基于Paxos的State Server。Log Data Tracker、Work Unit Creator、Work Unit Retriever 和 Work Unit Committer等的组件都是无状态的,部署在处理的input file的数据中心之内。 Log Data Tracker单独在数据中心内追中本数据中心内的input的数据增加情况,Work Unit Creator unifies则在这些输入数据之上常见全局的Work Unit。具体的做法是在State Sever中保存相关的数据,以Key-Value的方式存储,Key为文件的名字,而Value为input files来自各个数据中心的元数据。如果input files只来自一个数据中心,则倾向于就在input files所在的数据中心内处理。否则的话平均分配这些工作。如果保存了Local Application Processing处理之后的结果的数据中心在这些结果被消费之前就由于某些原因无法使用,就需要Ubiq有一些机制来回滚前面的结果commit,以便于重新生成输出,即重新操作。或者是将结果复制到另外的数据中心。回滚操作在处理结果是确定性的时候是可用的,但是如果不是的就只能使用复制到其它数据中心的方式。
0x02 特性
容错上面,Ubiq的设计主要体现在这样的几点,一个处理State Server之外,其它的组件都是stateless。一个数据中心一个组件对应到多台机器,一些机器的故障不会影响到Ubiq的运行。由于stateless,重启故障机器 or 使用其它机器替代也比较简单。而State Server的容灾主要依赖于Paxos协议。另外一个是处理Local Application Processing的故障,Ubiq会为一个工作估算一个local Estimated Arrival Time,local ETA。Work Unit Retriever从State Server中取回一个Work Unit,State Server通过ETA估算这个Unit什么时候会被完成,一般设置为ETA的几倍的时间。这段时间内,这个Work Unit不会被重新分发,这段时间过后没有收到处理完成的信息就可以重新进行分发。可能存在的重复结果会被State Server去重处理。对于整个数据中心故障的情况,Ubiq将故障的DC从处理流程中去掉,用其它数据中心来提代。对于数据中心部分故障的情况,在local ETA基础之上引入一个data center ETA,处理的思路和local ETA类似,
We give a work unit to one data center by default and set the data center ETA to T minutes. If the work unit is not committed within T minutes, it is made available to another data center. This ensures that if one processing data center goes down or is unable to complete the work within the specified SLA, backup workers in the other processing data center will automatically take over the pending workload.
Google还有另外的一个类似的系统Photon,Paper中特意比较了两个系统之间的差异,Photon处理数据在event-level级别处理,而Ubiq在Work Unit基本,就是一个event bundles;Photon主要作为log joining操作。一个事件输入流会和join其它的事件输入流,得出最后的结果。而Ubiq使用于部分聚合和数据格式转换这样的场景;Ubiq批量处理的方式不需要向Photon一样维护event级别的状态信息。这个节约了不少资源;差别最大的是延迟,Photon的延迟在几秒级别,而Ubiq在几十秒的级别。
0x03 部署方式和评估
这里具体信息可以参考[1].
Trill: A High-Performance Incremental Query Processor for Diverse Analytics
0x10 基本设计
Trill在微软在14年就发表的关Stream Processing的一篇Paper,后面这个系统被微软开源,不过好像影响不大。Trill的设计和前面的Naiad有很多类似的地方,又有不少的改进。和很多的类似系统一样,Trill也是一次处理一个Batch。Naiad在一个Batch是以航的方式处理,而ColumnarDB处理初级以列的方式处理。Trill则结合来两者的设计。数据一个Batch处理,在一个Batch之类,数据用列的方式来组织,这样方法带来了序列化和反序列花的巨大的性能提升。这种设计就直接影响到了 data-batch结构的设计。一个data-batch的数据之内,会有一个bitvector来标记一个对应的数据想存在与否。除此之外还有SyncTime和OtherTime以及数据本身。SyncTime表示时间产生的时间,而OtherTime会例外的含义。用C#表示这样的数据就是,
class DataBatch {
long[] SyncTime;
long[] OtherTime;
Bitvector BV;
}
// 加上数据就是:
class UserData_Gen : DataBatch {
long[] col_ClickTime;
long[] col_UserId;
long[] col_AdId;
}
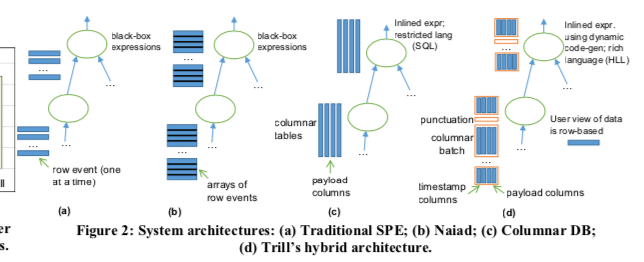
Trill也只是很丰富的算子,比如Where,Select等。Trill说其的一个特点是与高级语言的结合,处理算子的使用和C#现在的一些使用方式类似之外,在实现中也做了很多优化,比如使用在一个Batch之类使用MultiString结构来将Streaing数据紧缩保存,减少语言特性带来的开销。另外的一些优化方式比如内存池等。在Trill中,每个event会被划分到一个data window (or interval)之中,这个和Naiad有些类似。一个Event可能出现在一个interval中,但是也可能出现在不同的interval中,比如一个insert在一个interval,而对应的delete在另外一个interval。SyncTime和Other用于处理interval相关的逻辑,
* When other-time is greater than sync-time, it represents an interval with a data window of [sync-time, other-time).
* When other-time is ∞, it is a start-edge that denotes the insertion of an item at sync-time.
* When other-time is less than sync-time, it is an end-edge that occurs at sync-time and deletes an earlier start-edge that occurred at the previous timestamp (other-time).
与此相关的另外一个概念是punctuation,punctuation作为数据处理到的一个点,可以强制这个punctuation所在时间T之前的数据被处理。系统注入punctuation的频率由用户定义,这个punctuation限制了最大的batch大小。但是punctuation之间可能是多个batchs。
0x11 评估
这里的具体信息可以参考[2].
Drizzle: Fast and Adaptable Stream Processing at Scale
0x20 基本思路
Drizzle本质上还是一个在Spark Steraming上面改进而来的系统。核心的设计基于这样的一个假设/现象:在Stream Processing中,workload和集群的特性改变的频率而很低的,Drizzle通过将数据处理的interval和调度的interval分离开来降低延迟。Drizzle保留来之前的BSP-based模型,即多个workers并行执行一个任务,在一个完成点等待所有workers完成这个任务之后在进行后面的任务的操作的方式。Drizzle主要有话的两个思路就是Group Scheduling和Pre-Scheduling Shuffles,另外还有一些其他的有话。
-
Group Scheduling。Drizzle还是一个从micro-batch模式改进而来的系统。涉及到任务调度的时候,调度会带来调度的延迟。由于Drizzle所说的workload和集群的特性改变的频率而很低的,这里有话的思路就是多个micro-batchs一起进行调度。Drizzle面临的任务中,代表计算逻辑的DAG很大程度上是静态的,而且很少改变。这样就可以提前分析这个DAG来进行调度。静态的方式解决了多个micro-batchs一起进行调度增加的延迟。Paper中也说明了这样的设计下,对于容错有额外的一些改动,比如提前做出的决策会由于机器的故障需要重新处理等。关于如何现在调度的group-size,Drizzle使用了TCP中congestion control的思路,使用类似于AIMD策略来动态调整到合适的大小。
-
Pre-Scheduling Shuffles。这个优化是BSP模型下面barrier的有话。BSP下面一个任务完成之后workers会在一个barrier等待所有的workers完成任务。Drizzle通过pre-schedule downstream tasks的方式,即现调度下游的任务。在处理上游任务的时候,调度器可以知道这些上游任务的下游任务在那些机器上面运行。通过将这些任务调度到同一个地方,避免了/减少了后面运行的时候调度器的操作,降低延迟,提高了可拓展性,
First, it scales better with the number of workers as it avoids centralized metadata management. Second, it removes the barrier, where succeeding stages are launched only when all the tasks in the preceding stage complete.
0x21 评估
这里的具体信息可用参考[3].
参考
- Ubiq: A Scalable and Fault-tolerant Log Processing Infrastructure, https://ai.google/research/pubs/pub45805.
- Trill: A High-Performance Incremental Query Processor for Diverse Analytics, VLDB ‘14.
- Drizzle: Fast and Adaptable Stream Processing at Scale, SOSP ‘17.
- Disk Paxos, 2002.
