Blizzard: Fast, Cloud-scale Block Storage for Cloud-oblivious Applications
0x00 基本设计
Blizzard是微软开发的一个块存储的系统,Blizzard对外表现就是一个SATA磁盘。Blizzard构建在Flat Datacenter Storage (FDS)上面。由FDS来实现基本的数据存储和副本机制等,这样Blizzard就会简单很多。FDS是一个Blob的存储系统,Blizzard也就构建在FDS的Blob的抽象之上。Blizzard在Paper中提到的第一个设计选择就是条带化,就是将一个虚拟磁盘中一个IO操作分散到多个tractsB上面(Blob的一个组成带为,一般大小为8MB)。这种将方式是很常见的,Paper中这里讲了许多这么做的好处,简单直观的好处就是跟大的带宽,类似于一个软件RAID,另外就是更好的延迟表现,形成热点的概率更低等。一个打散的Tract的集合在Blizzard中称之为一个Segment,基本示意如下图,这里打散的tracts的数量为2。这个数量是可以配置的,Paper中举例使用128的时候,可以提高的带宽超过了1000MB/s。
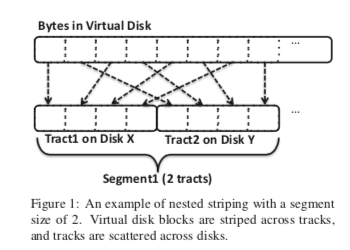
Blizzard提供了多种的写入语义,这里的语义主要和数据的持久化特性和写入操作的执行顺序相关。
- Write-through,是最简单的一种,可以提供在crash时候最小的数据丢失。这种模式下面Blizzard只有在讲数据写入到FDS中,确认数据持久化之后才会发挥给Client ACK写入完成。很显然缺点就是性能会比较低;
- Flush epoch commits with fast acks,这种模式下面,用户的操作会被划分为一个个的flush epoch(以flush操作来划分)。当一个段时间内所有的请求都发送到FDS请求写入时,标志着这个flush epoch被issued,当所有的写入请求的数据都持久化时,标志这个flush epoch已经retired。为了实现这样的逻辑,Blizzard维护一个从0开始递增的epochToIssue计数器,另外还有一个从0开始计数计数器currEpoch。前者记录那些请求已经被发送到FDS进行写入操作,而后者表示客户端已经进行的flush请求的次数。一般情况下currEpoch都大于epochToIssue。写入 or flush操作的时候,Blizzard都会例子返回给客户端成功,然后将请求排队。向FDS请求写入的时候,队列中为epochToIssue的请求会被发送。在一个epoch中的请求都完成的时候,递增这个epochToIssue,然后处理新epoch的请求。这样的时候,flush操作维护的并不是一种持久化的语义,而是一种顺序的语义你,前一个flush的操作必须早后一个的前面完成。
- Out-of-order commits with fast acks,在这种模式下面操作可以时乱序完成的。在这样情况下面为了实现prefix consistency语义,使用了两种机制,第一种就是使用log structure的方式来避免就地更新。以便于在故障发生的时候可以恢复在一个consistent version。另外的一个机制是使用一个确定性的permutation/顺序来决定哪一个log entry,即哪一个 <tract,offset>会接收到写入请求。这样的话在crash之后恢复到一个一致性状态的过程中,这个permutation加上checkpoint就可以起到作用。
0x01 一致性和容错
第三个语义Paper中花来比较长的时间来说明,这里详细一些地总结一下。假设Blizzard中的一个虚拟磁盘有V个Block,每个Block的大小是相等的,具体的大小可以根据业务来调整。这些Block对应到FDS中的P个physical block来保存(P > V)。Blizzard使用log structure的方式来管理这些physical blocks,另外使用一个blockMap来保存physical block到virtual block的映射关系,另外维护一个allocationBitMap来表示那些physical blocks这在被使用。在读取的时候,就需要根据blockMap中保存的映射关系来找到实际保存数据的physical block。处理写入的时候会复杂不少,原理如下,
-
在初始化Blizzard中的一个虚拟磁盘的时候,会初始化一个确定性的permutation,表示后面以log structured方式使用这些physical blocks的顺序。这个排列可以使用线性同余的方式生成,而不用实际保存这个permutation,这样就只需要保存线性同余的三个参数即可,空间复杂度只要O(1)。在接受到一个请求的时候,立即选择permutation中最近的一个没有使用的physical block进行写入。这里不会有等待排队的操作。
-
在发送出写入请求的时候,不会立即去更新allocationBitMap和blockMap。写入请求发送给FDS之后,这个写入会被排队,并且这些排队的写入可以用来回复读取请求,当然可以这些数据是没有持久化的。在一个写入请求完成的时候,根据permutation来确定这个是不是一个flush epoch的最后一个完成的请求。如果是,则递增lastDurableEpoch,并移除相关写入项,然后更新blockMap和allocationBitMap。
-
Blizzard写入的时候,写入的是一个expanded block,也就是这个写入到FDS的block不仅仅包含来来自用户的数据,还包含了virtual block id、epoch和CRC的信息。Paper中特地低了一下非对其写入带来的问题,向一个以及写入部分数据的block的数据写入数据的时候,需要将原来的数据读出来处理之后在写入完成的时候,这个操作对性能的影响比较大。
-
Blizzard的客户端会周期性地将blockMap和allocationBitMap做一个checkpoint。checkpoint的时候使用场景的轮流写入的策略,避免checkpoint进行中故障导致新数据只有部分数据,老数据被部分覆盖,
... checkpoints the blockMap, the allocationBitMap, the four permutation parameters, lastDurableEpoch, and a CRC over the preceding quantities. ... Blizzard does not update the checkpoint in place; instead, it reserves enough space on the FDS blob for two checkpoints, and alternates checkpoint writing between the two locations. -
恢复操作的时候,读取保存checkpoints的两个位置的数据,选择其中一个正常的且lastDurableEpoch更高的。通过按照permutation顺序而roll-forward来处理。这里还要使用到allocationBitMap,因为根据permutation选择使用的physical block会由于被使用了而跳过。这个roll-forward的操作会在两种情况下终止,1. roll-forward操作读取的physical block上面保存的epoch小于lastDurableEpoch,或者是2.一个block 所有副本的CRC校验都失败的时候。如果一个block是正常的话,会更新allocationBitMap和blockMap。处理完成的时候设置lastDurableEpoch。这样用于保证回复到一个点,这个点之前的操作都成功了。
-
由于没有使用nested striping的方式。Blizzard通过线性同余的方式来分散写入。在实际中也能取得很好的效果。
Blizzard提供的上面三种的模式中,从客户端角度看的一致性当然是不同的,
- 在write-through模式中,只有在将数据传输到virtual drive的时候的数据才会丢失。对于客户端crash来,只要数据到了Blizzard,数据还是会被持久化的。客户端只有在数据被持久化的时候才会收到ack。
- 在fast acknowledgment模式中,故障之后根据可以恢复的情况将不同epoch划分为三个部分。假设在epoch R发生了故障,那么R之前epoch写入的数据都是可以恢复的,R epoch中的数据可能恢复部分、全部 or 没有。而R之后的epoch不能恢复数据。三种类型的epoch分别称之为preserved epochs, questionable epoch, 和 disavowed epochs。
- Out-of-order commits with fast acks提供了一种prefix-consistent。实际上另外的两种也满足了prefix-consistent。
除了上面提到的部分,比如checkpoint,Blizzard另外的容错机制基本就依赖于FDS。
0x02 评估
这里的具体信息可以参看[1].
Isotope: Transactional Isolation for Block Storage
0x10 基本思路
Isotope的基本思路是在Block Storage的抽象上面实现事务的功能,另外好像有一个类似的研究是在文件系统的接口上面实现事务的功能。Block Storage的接口还是要比文件系统的结构简单不少,Isotope中提供了这样的一些基本结构块,其特点就是事务相关的部分,
/*** Transaction API ***/ int beginTX();
int endTX();
int abortTX();
//POSIX read/write commands
/*** Optional API ***/
//release ongoing transaction and return handle
int releaseTX();
//take over a released transaction
int takeoverTX(int tx_handle);
//mark byte range accessed by last read/write
int mark_accessed(off_t blknum, int start, int size); //request caching for blocks
int please_cache(off_t blknum);
// 一个使用这些接口的简单例子
isofs_inode_num ino;
unsigned char *buf;
//allocate buf, set ino to parameter ...
int blknum = inode_to_block(ino); txbegin:
beginTX();
if(!read(blknum, buf)){
abortTX(); return EIO;
}
mark_accessed(blknum, off, sizeof(inode)); //update attributes
// ...
if(!write(blknum, buf)){
abortTX(); return EIO;
}
mark_accessed(blknum, off, sizeof(inode)); if(!endTX()) goto txbegin;
0x11 基本设计
Isotope的结构架构如下,主要分为这样的基本部分,1. Isotope使用快照事务中的一些思路来实现事务,这里A用来分发timestamp,决定事务的顺序;2. 事务的运行需要一个日志,对应到组件E;3. 为了高兴查询这个日志上面的数据,B为内存中的一个索引;4. 事务提交大时候会用到组件D来检测事务冲突;5. C为内存中的Buffer,事务进行中的一些数据会保存在这里。Isotope中运行事务的时候,
- 先调用beginTX的接口,Isotope在内存中创建一个 intention record,即记录这个事务读/写集合的一个数据结构。Isotope这里的一个设计特点不是在Block的粒度上面追踪一个事务的读/写集合,而是在更小的16byte的很小的粒度上面。使用一个256bit的bitmap来记录一个4KB的Block中每个16bytes的情况。对于写集合,会有另外的一个4KB的Payload,即写入的数据。这些数据会暂存到内存中。
- 在上面的intention record创建完成之后,可以向A组件申请一个start timestamp。这里申请不会到导致A的计数递增。在调用endTX提交事务之前,一个事务的的执行不会影响到其它的事务,其写入的数据也只会对自己可见,其它的事务不可见这些数据。写入数据Buffer在内存中(是否会在一些情况下带来内存的压力?),也就不会涉及到写入的IO操作。mark accessed用于标记访问的情况,会涉及到标记用的bitmap。
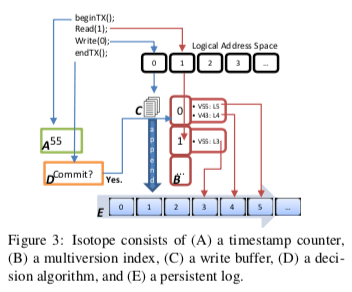
在事务要提交的时候,主要要做的就是检测事务冲突的情况,以及提交数据并持久化。Isotope提供两种不同基本的隔离级别:strict serializability 和 snapshot isolation,在Isotope中实现strict serializability隔离级别的一个简单的思路是事务按照时间戳代表的顺序运行,事务提交的时候会检查这个事务更新的Block是否被其它的事务读取,但是带来的一个问题就是追踪冲突的开销很大,因为Isotope在16bytes的粒度检测冲突情况,这里就需要大量的检查操作。为了解决这个问题,这里使用的做法是维护一个temporal stream of prior transactions,冲突检测类似在这里的一个检测前面的一个冲突窗口内的情况。基本的思路如下图所示。Isotope中两种隔离基本在操作上面的区别就是冲突检测的时候,检测的是一个事务T的冲突窗口内读取(对于strict serializability) or 写入(对于snapshot isolation)的地址是否被已经提交的事务更新了。
• For strict serializability, the transaction T aborts if any committed transaction in its conflict window modified an address that T read; else, T commits.
• For snapshot isolation, the transaction T aborts if any committed transaction in its conflict window modified an address that T wrote; else, T commits.
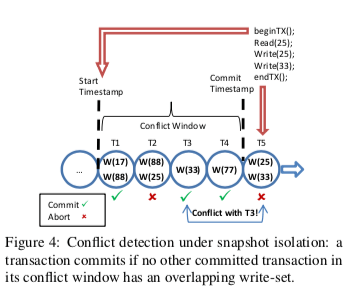
endTX接口被调用的时候,这个事务T的对应的slot中,组成上图中的结构,冲突窗口就是这个事务的start timestamp和commit timestamp中间的部分。如果检测到冲突而需要abort事务,直接就是舍弃内存中的数据,并返回错误。如果决定事务提交,需要将写入的数据先写入到persistent log中,之后就是更新内存中的multiversion index,使得数据只想新版本的数据。这些操作完成之后,事务即可完成提交。这里要注意的问题是更新丢失的问题,因为冲突时在16bytes的粒度上面检测的,这样不同的事务更新一个block不同位置的时候,可能导致后面的写入覆盖了前面的数据,所以这里要将这样的事务之间的更新合并起来写入才行。
0x12 评估
这里的具体信息可以参考[2].
参考
- Blizzard: Fast, Cloud-scale Block Storage for Cloud-oblivious Applications, NSDI ‘16.
- Isotope: Transactional Isolation for Block Storage, FAST ‘16.
- Ursa: Hybrid Block Storage for Cloud-Scale Virtual Disks, EuroSys ’19.
