OS I/O Path Optimizations for Flash Solid-state Drives
0x00 基本思路
这篇Paper是为性能较好的SSD设计的IO Stack的优化,其基本思路是减少IO操作过程中的Context切换,简化IO Stack的结构,支持多种的IO策略来提高性能。在目前的IO Stack中,基本执行流程如下。在现在的IO Stack中, interrupt service handler routines (ISRs)被拆分为两个部分。目前的设计存在的可能导致一些情况的调度延迟,主要是下图所示的一些可能讲IO thread重新调度到其它的CPU Core的一些问题。

0x01 基本设计
这里设计的IO Stack如下,总体在FS层之下,结构上面比原来的IO Stack要简单很多。基本就是三层。
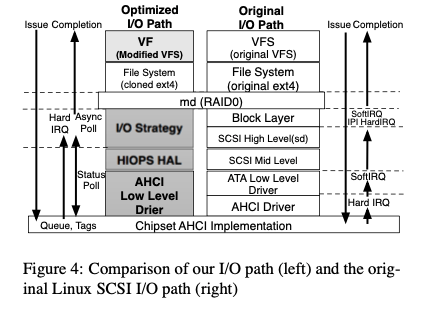
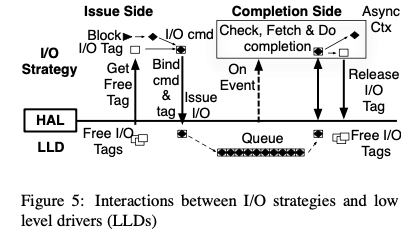
通过这三层的抽象,这里讲一个IO Path中的操作分为这样的一个过程。主要有两个阶段,一个是Issue Side的操作,另外一个是Completion Side的操作。Issue Silde的基本逻辑就是获取一个可用资源,然后发出请求。在Completion Side可以选择如果获取到结构,一般的选择就是中断 or 轮训的方式,估计还可以是hybrid的方式。根据这样抽象,这里讲IO Path执行分为这样一些测策略,
-
Non-blocking I/O,在这种策略下面,没有代表IO请求的IO Contenxt回block在请求资源上面。在请求到达issue side的时候,会被push到一个fifo的queue里面。在资源可用的情况下吗(tag available),相关的请求从queue里面pop出来,发送到设备进行实际的IO操作。这里实际的IO请求的发出会被推迟到资源可用。从下面的图中看出来,这里和传统的Path相比,主要的优化是从那些工作安排方面。
-
Lazy I/O Processing,这里的区别是Post Process有H/W IRQ中转移到了IO线程中操作。另外IO线程这里回在发送请求和wakeup的这段时间内设置一个CPU亲和性,从而实现更好的缓存友好性。
-
Cooperative I/O Processing,这么策略引入了一个cooperative context,用于线程之间的工作协助处理,
For cooperation, completion contexts make fetch event calls to steal I/O processing work from post processing handlers. Issue threads performing non-blocking I/O issues for other I/O threads play another form of cooperation -
Poll Based I/O,这里在前面Cooperative I/O Processing转变是用轮询的机制。
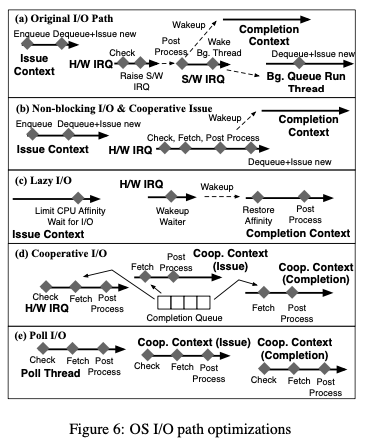
emmmm,具体没怎么弄明白。
0x02 评估
这里的具体信息可以参看[1].
Asynchronous I/O Stack: A Low-latency Kernel I/O Stack for Ultra-Low Latency SSDs
0x10 基本思路
这篇Paper也是Linux IO Stack的一些优化设计,主要是降低在Low Latency SSD上面IO Stack带来的延迟。在Low Latency SSD上面,目前的Linux使用引入Kernel几年的multi-queue block layer。作者针对这个进行一些优化,基本的思路是简化和重叠操作。目前在ext4文件系统上面读取数据的一些优化表示如下,
void buffered_read(file, begin, end, buf) {
for (idx = begin; idx < end; idx++) {
page = page_cache_lookup(idx)
if (!page) {
page_cache_sync_readahead(file, idx, end)
page = page_cache_lookup(idx)
} else {
page_cache_async_readahead(file, idx, end)
}
lock_page(page)
memcpy(buf, page, PAGE_SIZE)
buf += PAGE_SIZE
}
}
void page_cache_readahead(file, begin, end) {
init_list(pages)
for (idx=begin; idx<end; idx++) {
if (!page_cache_lookup(file, idx)) {
page = alloc_page()
page−>idx = idx
push(pages, page)
}
}
readpages(file, pages)
}
void ext4_readpages(file, pages) {
blk_start_plug()
for (page : pages) {
add_to_page_cache(page, page−>idx, file)
lba = ext4_map_blocks(file, page−>idx)
bio = alloc_bio(page, lba)
submit_bio(bio)
}
blk_finish_plug()
}
buffered_read读取数据的时候Page Cache是否存在想要读取的数据,当Cache Miss的时候就想要去SSD上面去读取,读取上面之后想要将其添加到Page Cache里面,这里还需要为Page Cache分配Page来保存数据。另外在FS层读取的时候,如果一个文件的索引信息不在内存中的时候,还想要从磁盘上面读取。在FS层发出的请求中,想要分配bio对象初始化并submit。
0x11 基本设计
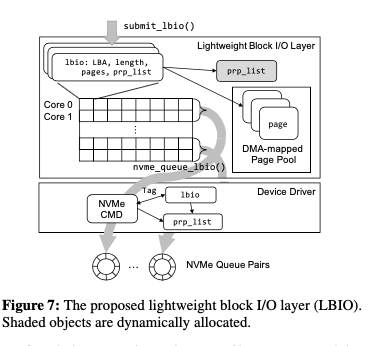
Asynchronous I/O Stack这里的第一个优化是设计了一个更加轻量级的Block Layer。和之前的Block Layer不同,这里主要的结构就是lbio一个结构,即light write block io。这样设计是为了消除bio到request这样的结构转化,另外减少想要内存分配的次数。降低开销提高性能。lbio结构回包含LBA, I/O length, pages to copy-in 和 DMA addresses of the pages等信息。LBIO这样使用了一个二维数组,作为core-nvm queue的一到一的映射,
each lbio array row is one-to-one mapped to each core and two consecutive rows are mapped to an NVMe queue pair. When the number of NVMe queue pairs is equal to the number of cores, lockless lbio object allocations and NVMe command submissions are possible, as in the existing multi-queue block layer.
这里在发出io请求的时候,不会进行任何的io合并和排序的操作。
read path
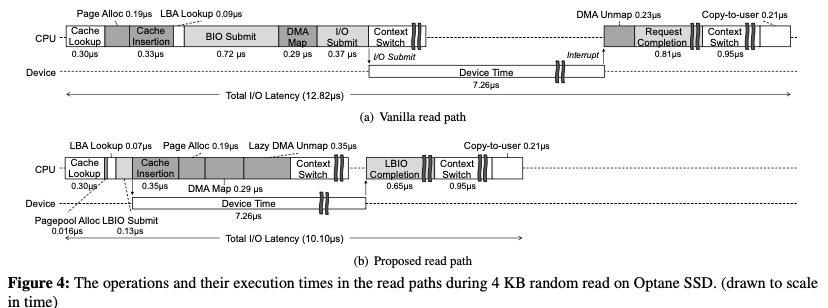
在读取路径上面设计的时候,主要是一些操作的重合,如下图所示。传统的read path实现的时候,基本的流程如下:1. 首先查询Page Cache,如果存在的话,就可以返回数据,如果不存在,则需要接下来的操作,示例图如下:
- 读取数据的时候,如果文件的extent/block索引信息不在内存中,则需要先读取文件的索引来获取文件数据的位置。这样带来的额外开销是很大的。这里的优化是提前地讲这些信息都load到内存。降低需要读取索引信息的可能。缺点是可能带来额外的内存消耗。在Paper中,作者认为带来的额外开销是比较小的,可以接受。
- 另外的一个就是Page分配和DMA映射带来的开销。这里的优化思路是提前的,为每一个CPU核心预留一下已经DMA-mapped 的free pages。
- 另外的一个优化是读取回来数据之后。原来的逻辑中,读取回来的数据需要先添加到Page Cache中之后才能发挥。而这里的优化思路是先发挥数据,然后添加到Page Cache。这样的优化是消除了添加Page Cache带来的延迟,缺点是可能后面的并发操作没有及时看到已经被取回的数据。这里的处理方式是允许这样的情况存在。
- 另外在使用完成之后,DMA映射也需要接触。这里也是用lazy的方式。
write path
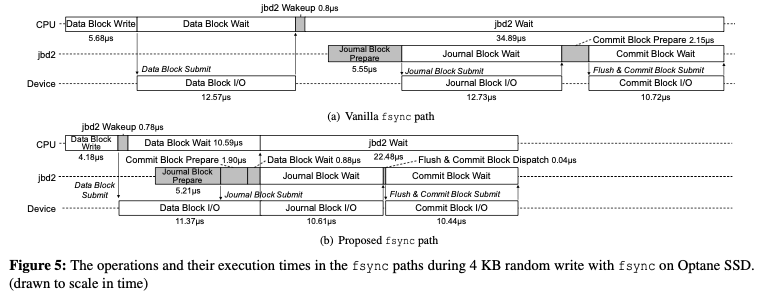
write path的处理逻辑和read path相差很大,所以这里的优化方式也不同。这里重叠的操作主要是数据写入和日志写入的部分。传统的write path的写入数据之后,要准备一个日志提交的操作。这里讲写日志的一些准备操作重叠操作写入数据block的时候。在数据block写入完成之后,在进行日志数据的写入。既维持了原来的语义,另外有降低了处理的时间。
0x12 评估
这里的具体信息可以参看[2].
参考
- OS I/O Path Optimizations for Flash Solid-state Drives, ATC ‘14.
- Asynchronous I/O Stack: A Low-latency Kernel I/O Stack for Ultra-Low Latency SSDs, ATC ‘19.
