Ziggurat: A tiered File System for Non-Volatile Main Memories and Disks
0x00 基本思路
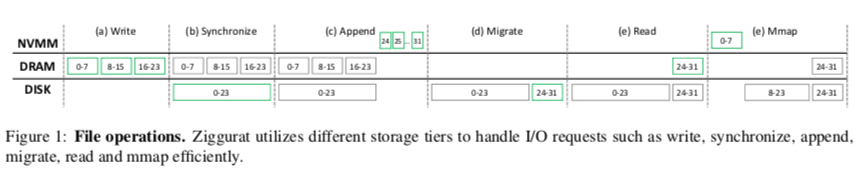
Ziggurat是在NOVA上面的分层存储的一个文件系统。对于这样的NVMM,SSD,或者还有HDD的设计,其中两个主要的问题就是,一个是决定将元数据、数据保存到哪里,比如将总是将元数据放在访问最快的地方,数据写入的时候也是总写入最快的地方;另外一个是目前保存的位置被认为不可理的时候,怎么将这些数据搬迁到合理的地方。Ziggurat在这些问题的解决方案上面的考虑如下,1. 不总是写入访问速度最快的地方,Ziggurat认为将较小的写入、同步的写入操作写入到NVMM中,而大块的、异步的数据写入可以写入更慢的地方。这里引入了一个synchronicity predictor来分析每个文件的写入行为,并预测未来写入到特点。2. Ziggurat迁移数据的时候,不是以整个文件为单位。而是只会迁移“冷文件”中冷的数据部分。迁移数据的时候,也尽可能地去批量迁移操作,小文件组织到一起顺序写入迁移目的,以获得更高的带宽。Ziggurat会通过应用的读-写操作的模式,动态地决定需要迁移数据的一个阈值。下图表示的一个分三次写入了24个块的例子,
- 写入操作的时候,Ziggurat通过synchronicity predictor判断这几个写入操作都是比较大,而且是同步的写入,就决定写入到DISK。写入会先缓存到Page Cache中。在fsync操作的时候,这三个块被合并为一个块写入到DISK上面;
- 之后是一个append的操作,而且认为写入的数据量很小,就将数据写入到NVMM中。之后这个问题被判断为边“冷”了,迁移操作将NVMM中append的数据合并为一个块,写入到了DISK中,NVMM中的数据被删除;
- 读取操作的时候,需要将数据从DISK读取到内存中,会使用到Page Cache。在应用使用mmap操作的时候,这里会使用reverse migration的机制,将数据迁移到NVMM,方便应用直接访问这些数据。
- Ziggurat决定写入操作的模式主要包括了两个部分,1. synchronicity predictor,通过统计两次fsync操作之间的时间间隔,如果低于一个阈值则判断为同步写入,设置了O SYNC flag的时候直接认为为同步写入;2. write size predictor,write size predictor不仅仅是判断写入的大小,而且还要注意开始一些较大的写入之后是不是在之前较大写入大范围内有很多较小的覆盖写入,这些的操作写入到DISK上面会造成碎片化,影响性能。在重写之前的一个写入entry的数据部分的时候,write size predictor会判断是否覆盖了之前写入的一半以上的部分。如果是,则将相关的一个计数器由之前的写入entry转移到新的写入entry,并计数器+1操作,否则将计数器置0。计数器超过4(可调的一个参数)的时候认为是较大的写入。
0x01 数据迁移
从之前的一些相关的系统来看,数据迁移时很难弄的,最容易出现的时使得系统出现抖动。Ziggurat使用basic migration来将在读为主的workload中将数据从DISK中迁移到NVMM中,使用group migration来将NVMM中的数据合并数据转写到DISK中,实现更少的碎片。Ziggurat会维护每个CPU核心,每个存储层一个的cold list来确定一个文件的“温度”。这些lists通过average modification time(amtime)来排序,在更新文件的时候更新这些lists。为了知道一个文件中哪一个block最冷,这里会为一个文件的每个block维护一个mtime(这样估计会引入更多的元数据)。在迁移数据的时候,ziggurat从list中获去到最冷的数据,如果mtime较“旧”,超过了一个阈值,则将整个文件视为冷的。另外迁移操作的时候,ziggurat会考虑到文件不同块的冷热程度,可以将热的块继续保存到NVMM中。Ziggurat决定什么时候进行数据迁移由NVMM利用率的阈值决定,但是这个阈值会有workload的read-write ratio来动态调整,不是固定的。
-
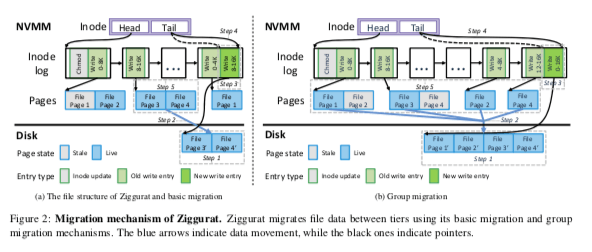
Basic Migration,Basic Migration的操作基本分为在DISK上分配空间、然后拷贝数据,之后在inode-log添加一条记录标记了这些迁移写入的信息。之后更新NVMM中的log tail和DRAM中的radix tree,之后NVMM中的空间就可以释放了。由于Ziggurat从NOVA文件系统改进而来,这个的一些结构对应到NOVA文件系统的对应结构。这些操作中也有不少的细节优化,比如锁的粒度,顺便预热 Page Cache等。这里会有一个Reverse Migration来加速mmap情况下的访问和read为主的workload。Reverse Migration是类似于Basic Migration的一个反向操作,
... reverse migration, which migrates file data from disks to NVMM, using basic migration. Write entries are migrated successively without grouping since NVMM can handle sequential and random writes efficiently. File mmap uses reverse migration to enable direct access to persistent data. Reverse migration also optimizes the performance of read-dominated workloads when NVMM usage is low since the performance depends on the size of memory. -
Group Migration,Group Migration的目的是将小块写入的数据聚合到一起。基本的操作流程是在下一层分配一块足够大的空间,之后在一些顺序写入中将上一层的多个数据块写入到这里,之后写入log并更新log tail,完成操作。之后前面的空间就可以释放了。
-
File Log Migration,在NVMM利用较高的时候,Ziggurat也会迁移file logs。通过周期性的扫描cold lists,来决定将冷的log数据迁移到下层。操作的时候会讲这些数据先读取Page Cache,之后完成在内存中完成数据聚合,在写入到DISK,之后更新元数据,完成操作。
0x03 评估
这里的具体信息可以参看[1].
Orion: A Distributed File System for Non-Volatile Main Memory and RDMA-Capable Networks
0x10 基本架构
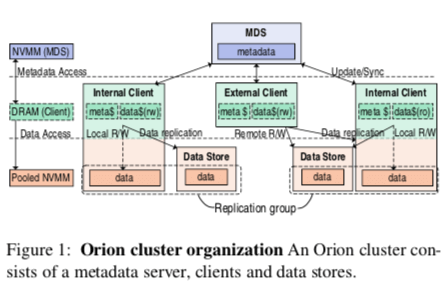
Orion和前面的Ziggurat一样,是在NOVA文件系统上面一些改进。看来NOVA对NVMM文件系统的设计还是产生了很大的影响的。Ziggurat是在NOVA文件系统的基础之上引入了分层的设计,而Orion则是在其基础之上,假设RDMA做成了一个分布式的文件系统。Orion的基本架构如下图所示,也是MDS管理元数据、DS保存数据。Client又分为了External Client和Internal Client,,后者也会负责保存数据的功能,也扮演者External Client的角色。客户端通过RDMA直接和Orion的节点连接。MDS和DS都通过多副本来保证高可用,但是Paper中没有讲太多副本的内容,一般分布式的存储系统中这部分是最重要的部分(之一)。
- Orion提供的也是POSIX结构,文件的组织结构使用了NOVA的方式。每个Orion的inode有一个log关联,即per-inode log的设计。MDS会保存了所有的元数据信息,而每个客户端对于打开的文件,会保存一份保底的inode和inode log的副本。Orion认为通过讲inode的logs拷贝到客户端,可以更快处理元数据。重放log就可以恢复文件的元数据信息。Client可以通过对比本地log的tail和MDS的tail来确定本地数据是否为最新。
- 在分布式的情况下,数据会发布保存在不同的DSs上面,Orion使用global page addresses (GPAs)来定位一个Page的位置,另外GPA还可以用来定位副本组/replication group。读取数据的时候,请求replication group中的任意节点即可。写入操作的时候会使用CoW的方式,同时在文件的log后面添加日志项(write offset, size, 和 the address to the new data block)。Orion一个有特点的地方是Internal Client进行写入操作的时候,会将对应的数据块迁移到本地(空间足够的情况下)。
- 另外客户端也会维护本地的一些缓存数据。
0x11 元数据管理
Orion中元数据的更新实际上都在MDS完成,客户端通过和MDS交互来获取元数据信息、提交元数据更改已经应用其它的客户端已经提交的更改。客户端和MDS之间通过三种方式来交互,1. direct RDMA reads(用户简单的交互请求),比如从MDS拉取文件的元数据;2. 推测性的log commits,客户端通过log commit将本地的元数据更新应用到MDS。客户端首先在本地通过添加log entry到本地的inode log的方式来应用文件更新操作,然后通过log commit将更新应用到MDS,这里通过RDMA Send操作来完成,这里需要一个client arbitration来解决不同客户端更新同一个inode时候的不一致问题;3. RPC(用户复杂的请求),在涉及到对个inodes or 操作会影响到其它客户端的情况下使用。Orion的RPC通过一个RDMA send verb 和 一个 RDMA write来实现。
-
以一个open操作为例子,主要的操作流程如下,
1. For open() (an RPC-based metadata update), the client allocates space for the inode and log, and issues an RPC; 2. The MDS handles the RPC; 3. The MDS responds by writing the inode along with the first log page using RDMA; 4. The client uses RDMA to read more pages if needed and builds VFS data structures;Orion使用RDMA进行操作的时候应用来不少的优化,比如客户端请求的read和MDS发起write都使用直接应用到文件系统的数据结构。
-
Log commits的时候对于每个客户端,MDS留有一个256 KB的Buffer来与其进行交互,一个网络线程负载轮询RDMA completion queues (CQs)发送到这些Buffers中的请求,另外使用一些文件系统系统线程来处理这些请求,MDS中处理请求的时候会将log commit请求赋予更高的优先级。
-
多个并发更新一个inode时候,这种分布式的并发更新会有比较多的麻烦的问题。在这篇Paper中提到的部分是MDS在处理log commit的时候是根据到达的顺序处理,而且原子性地更新log tail。一个客户端可以通过比较MDS上面的和本地的log长度来确定本地是不是最新的信息。如果是就可以执行log commits。如果不是则需要更新本地的数据。客户端会将mismatch的数据更新到本地,如果是MDS以及应用多个的log entries,需要block目前的请求并同步MDS上面的log entries数据,并需要更新本地的DRAM中的数据结构,然后重新执行用户请求。重新构建内存中数据结构会在下面的一些情况下执行,
(1) two or more clients access the same file at the same time and one of the accesses is log commit, (2) one client issues two log commits consecutively, and (3) the MDS accepts the log commit from another client after the client RDMA reads the inode tail but before the MDS accepts the second log commit.
0x12 数据管理
Orion在interl client和data store节点上面有NVMM,这些NVMM作为整个的一个Orion系统的存储池。在进行资源分配的时候,Orion使用了一种两阶段分配的策略,在MDS中维护了一个关于所有的NVMM Pages的bitmap,客户端通过一次性从MDS请求分配一大块的NVMM空间,然后这个客户端自己在这个大块的空间上面进行更加细粒度的分配,这样的话MDS管理的空间分配就会是很粗粒度的,显著地减少了MDS的工作。对于internal client而言,在可能的情况下,总是倾向于使用本地的NVMM资源的。
-
数据访问的方式上面,Orion的策略是访问其它节点上面的数据通过RDMA的one-sided操作。比如读取的时候使用 one-sided RDMA reads来将数据读取到本地,并且可以将数据缓存到本地。在数据写入其它节点的时候,可以使用one-sided写入的操作,操作完成之后在向MDS进行log commits操作。在访问本地的NVMM中,通过DAX的机制来进行。Paper中给出的一个操作的流程,
1. A client can request a block chunk from the MDS via an RPC. 2. When the client opens a file, it builds a radix tree for fast lookup from file offsets to log entries. 3. When handling a read() request, the client reads from the DS (DS-B) to its local DRAM and update the corresponding log entry. 4. For a write() request, it allocates from its local chunk, and 5. issues memcpy_nt() and sfence to ensure that the data reaches its local NVMM (DS-C). 6. Then a log entry containing information such as the GPA and size is committed to the MDS. 7. Finally, the MDS appends the log entry. -
Orion能够保证元数据的一致性,但是对于数据而言,和很多的文件系统一样,不能保证总是一致的。Orion中与数据一致性相关是文件数据更新和log commit之前的操作逻辑。如果是log commit不等到文件更新操作完成,这样就是一种若一致性的保证,类似于ext4文件系统中的write back的模式(ext4的write back模式下面元数据写日志,数据不写日志,而且元数据写日志和写数据之前完成的顺序是不保证的),这样情况下性能更好,但是可能有data corruption的问题。Orion可以选择在完成文件更新的时候在进行log commit来获取更强的一致性保证。
-
另外通过RDMA写NVMM,不能保证数据都持久化到NVMM上面了,这个也给Orion提供更强的一致性带来的困难。Orion这里的做法是先在一个replica group上面分配需要数量的pages,然后使用COW的方式更新。然后并行地进行文件更新操作和提交speculative log commit到MDS。使用RDMA写入数据的时候,会在这个操作中带有一个 page’s global address的信息(通过一个RDMA的功能),DS在完成队列上面看到这个信息的时候,进行一些操作保证数据到写入到了NVMM上面,然后向MDS发送信息,MDS在收到了足够数量的这些的信息时候就可以处理之前提交的log commit。
0x12 评估
这里的具体信息可以参看[2].
LAWN: Boosting the performance of NVMM File System through Reducing Write Amplification
0x20 基本思路
LAWN这篇Paper的思路比上面的两篇要简单一些。LAWN要解决的问题时NVVM文件系统中的写入放大的问题。由于NVMM只支持8byte级别的原子写入(intel的还有原子写入16byte的指令)。如果覆盖写入的话,可以选择的方式就是COW or Log的方式,实际上现在的文件系统实现覆盖写一致性也基本就是这两种方式。不过带来的问题就是写入的放大,原因是显然的。LAWN这里提出的问题是一种交替写入的方式,在文件系统的正常的存储空间之外,预留一些的称之为zone的部分,用于写入最近修改的数据,此时类似于一个Log/Journal的功能,但是LAWN又有另外的特点。LAWN的基本结构如下图所示,在NVMM中预留出一部分zone的空间,这些空间被划分为sub-zone(根据CPU核心数量划分),在更新一个文件的时候,LAWN会先查看更新位置的最新数据在不在zone中。如果在,则直接改写文件本身的部分,如果改写的过程中crash了,则认为是改写失败,继续使用zone中的数据,不会导致一致性的问题。如果改写位置最近的数据不在zone中,则将新数据写到zone中,不能直接更新文件的内容。这样的思路就是两个位置轮流写入的方式,当然一般情况下LAWN将zone设置为一个占用NVMM空间比较小的一个比例。这读取的时候,要查看读取范围内的最新的版本在哪一个位置,将最新的数据聚合起来返回给请求方。使用这里需要一个内存中的数据结构,来高效地回答一个文件一个范围内的数据是不是在zone中。
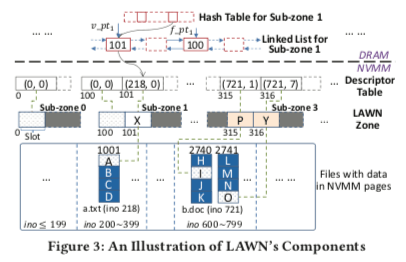
Paper中认为这种方式可以减少写入放大。在就地更新较频繁的情况下,效果挺好的。但是一个缺点是如何经常更新文件的不同部分,导致的一个问题就是文件数据碎片话。LAWN认为NVMM随机性能和顺序性能差别不大,这个不会是很大的影响,而且请求不同的地方还可以并行处理。(如果这里还增加一个后台将zone中的数据写回到文件原来的地方的话,就和很多的先写日志,在日志上面加上一层索引,然后读取的时候处理两个地方的数据。另外后台异步的将日志中的数据写回,减少碎片同时使得可以回收日志的做法很类似来)。
参考
- Ziggurat: A tiered File System for Non-Volatile Main Memories and Disks, FAST ‘19.
- Orion: A Distributed File System for Non-Volatile Main Memory and RDMA-Capable Networks, FAST ‘19.
- LAWN: Boosting the performance of NVMM File System through Reducing Write Amplification, DAC ’18.
