Ursa: Hybrid Block Storage for Cloud-Scale Virtual Disks
0x00 基本设计
这篇Paper很有意思,而且Paper中说的也比较完整。Paper中提到的Workload的基本特点是随机读取很多,局部性比较差,请求的大小一般不会很大。Ursa的基本思路是实现一个SSD-HDD混合的块存储,实现更低成本的同时还可以实现SSD一般的性能。其基本的架构如下。基本架构和很多的分布式存储系统一致,应用通过客户端和Ura的其它部分交互,存储一个中心话的Master节点来提供virtual disk/虚拟磁盘创建、打开、删除以及元数据保存、保存等的功能,还要负责集群的状态监控,处理故障恢复等。Chunk Server负责保存实际的数据,数据使用多副本保存。Ursa通过将主副本保存在SSD上面,其它的副本保存到HDD副本来实现SSD-HDD的混合存储。为了实现和SSD一样的性能,Ursa的基本思路是日志式写入,然后后台replay的策略。对于HDD,journal也会写入到SSD上面,然后repay到HDD上面。
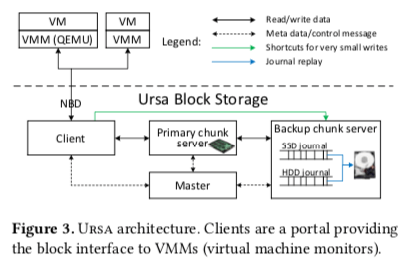
对于读取请求,Ursa都是倾向于使用SSD。对于写入请求,主副本写入到SSD,然后复制到备节点上面,在给客户端返回成功。对于副本来说,由于HDD和SSD时间很大的性能差距,特别是随机的性能。这里就使用日志式的写入方式,写入到一个SSD的journal盘上面,在异步地repay到HDD上面。用于journal的SSD和backup的HDD在同一个机器上面,当一个SSD的journal空间被使用完之后,会转移写入到另外一个负载较低的。如果都满了则写入到HDD。HDD上面写入的journal只会在HDD空闲的时候进行replay。在HDD上面写入journal式类似于一个兜底的操作,实际上Paper中提高在线上两年的部署中都没有使用到过。
- 对于大块的写入操作,这样的思路也许不是最佳的选择,因为HDD的顺序性能也还可以。这种先写journal然后在repay到HDD上面的操作会造成额外的写入,小的写入操作更加合适。Ursa的思路是设置一个阈值(Tj == 64 KB),超过了这个阈值大小的写入会被直接写入到HDD。这样的可能导致的一个问题是journal上面的数据可能是过期的,处理的时候要注意。
- 另外一个的思路是优化很小的写入,小于一个阈值的写入称之为tiny writes(Tc == 8 KB)。对于这样的写入,Ursa的思路是直接同时发送到主副本和备副本。这样在复制和一致性处理上面,都要有对应的策略,在论文的后面部分有讲到。
- Journal Index是Ursa用来处理journal和chunk之间的映射关系,即某个chunk的某个范围内的数据在journal上面作为journal保存。这个Index的Key是{offset,length},value为journal offset,用于查询一个访问内的数据在不在journal中。Ursa进行了一些优化,主要是为了提高访问查询和范围添加的性能:1. ({offset, length} → j_offset)只使用了8bytes,2. 使用一个两层的设计,第一层为红黑树,第二层为一个排序的数组,第一层添加性能更好,第二层查询性能更好。添加的时候先插入到红黑树中,然后异步合并到排序好的数组中。
为了提高性能,Ursa利用了多个层面的并行性,1. Disk内的并发性,SSD并发操作的性能远好于HDD。SSD内部的结构也决定了其可以进行并发的操作。所以Ursa在SSD上面运行多个chunk server。每个chunk server使用一个aio的线程来并发发送IO请求,而对于HDD就是使用单线程的非aio的操作。2. Inter-Disk的并发性,主要的思路是条带化,乱序执行以及乱序完成。Ursa中将一个虚拟的磁盘划分为固定的chunk,条带化将连续的chunk写入到不同的地方。3. 网络层面的并行,流水线处理请求。
0x01 一致性和复制
Ursa提供per-chunk linearizability的一致性保证。其复制协议也是基于 Replicated State Machine (RSM)。每个chunk会维护一个version,在每次写入操作的时候更新。另外chunk servers 和 master节点会维护一个persistent view number,新添加一个chunk server时候更新。
-
在打开一个虚拟磁盘的时候,客户端从master获取view number信息,以及和这个虚拟磁盘相关的chunk servers的信息。在获取到chunk severs信息之后,客户端询问这些chunk server的version number。确认一个有效的version number之后,选择一个chunk副本组中的一个作为master,一般都是选择SSD的节点。
-
Ursa通过租约机制来保证对于一个虚拟磁盘一个时刻只会有一个客户端读写。一般情况下虚拟磁盘都是智慧挂载在一个虚拟机下面使用。如果有多个VM访问的需求,用另外的机制来协调IO请求,
When multiple VMs mount the same virtual disk (which is uncommon in Ursa), we let a single client, which may reside on any machine, serve all the VMs and use a cluster file system (like OCFS) deployed on the VMs to coordinate concurrent I/O requests.
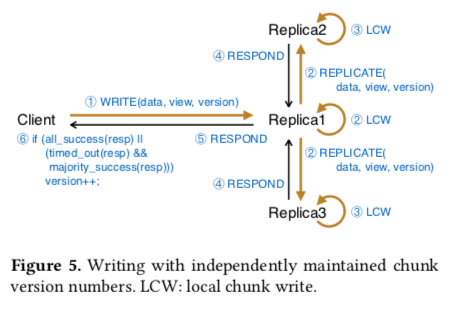
Ursa的复制协议将网络故障和副本故障区别对待,结合了同步复制和异步复制。Ursa复制协议的一些细节,
- 初始化,从master回去chunk的位置和view number信息,然后异步询问chunk servers上面的version number 和 view number信息。如果一个chunk所有的副本和master上面保存的一致(view number),则选择其中一个作为主副本,优先选择SSD的节点。在不相同时候,则通过cluster director 来处理一致性的问题,然后重试。
- 正常情况下的读写,客户端读请求一般倾向于选择使用主节点来处理,对于写入请求,客户端在请求中带上它知道的view number 和 version number发送给主副本。主副本在接受到这样一个写入请求的时候,操作:1. 检查主节点它本地保存的view number 和 version number是否一致;2. 如果一致,则将处理写入请求并将请求转发到其它副本,递增version number,然后回复客户端;3. 不匹配则拒绝写入请求,并回复客户端。如果客户端带来的version number更大,则主节点需要进行修复操作,通过从其它副本同步修改来解决。4. 如果客户端带来的version比主节点上面的小1,则只是转发给其它的副本,因为只会是一个重试的请求。
- 正常情况下写完所有的副本请求就返回了,但是由于故障这个条件不能满足了,则需要进行另外的操作。等待一段时间之后,如果能获取到半数以上节点的确认,也会返回给客户端。客户端会通知master节点处理这个问题,比如处理没有完全复制成功的数据 or 只用一个新副本代替被判断为故障的副本。另外的Ursa通过将小的写入请求直接发送给所有副本而不是经过主副本的方式,基本的逻辑是一样的。
- 在主副本被认为故障的情况下,客户端会选在另外的一个副本作为新的主节点。由于SSD journal的存在,写入性能影响不大,但是读取肯定差了不少,这个时候会选择另外的一个SSD的副本作为新的主节点。
增量修复的基本逻辑是每个副本在内存中保存一个journal lite,记录最近写入的position, offset, 和 version number的信息。当一个节点从临时的网络故障中恢复的时候,通过副本中保存的这些信息来同步故障时间内的操作,即增量修复。但是由于GC等的原因,这个增量的方式并不是每次都行,不行的时候则需要进行全量的修复操作,
the recovered replica tries to update its data by sending its current version number to other replicas. Upon receipt, these replicas (i) query their journal lite with the received version number to locate the modified data; (ii) construct a repair message based on indices provided journal lite; and (iii) transfer the message with the new version number to the recovered replica.
故障恢复操作的时候version number起着重要的作用,发生可以不一致情况的时候,master通知version number最高的副本来进行增量修复操作。Master通过找到多数派副本的最高的version number,用于修复处理的时候如果在这个最高version number之前执行的写入请求(被多数副本之前来),在修复操作之后会体现到修复之后的状态中。这里麻烦的事每个写入请求的多数派可能是不相同的,每个副本缺少一点也是有可能的。修复完成之后更新version number。后面的Discussion在实际应用中也挺有意思的。主要就是关于如何无缝升级各个组件[1].
0x03 评估
这里的具体信息可以参看[2].
PARIX: Speculative Partial Writes in Erasure-Coded Systems
0x10 Parity Logging with Reserved Space
PARIX这篇Paper是关于Ursa的EC的一个设计,要解决的问题是EC块被部分写的情况下,一般使用的方式是将原来的数据读取出来,重新生成EC输入然后写入。这样的方式是简单直观,但是性能会有一些问题,特别是在部分写很频繁的情况下。在Paper[3]中总结了处理部分写导致的需要处理EC更新的一些方式,并也提出了一种方法。除了将数据读出来重新计算的方式,还可以使用的策略是:Full-segment writes的方式,写入新的数据块和校验块,不用读取原来的数据,一般使用log-based的方式实现;Read-modify writes的方式,读取出旧数据块的数据,计算出新、旧数据块之间的差异,然后将变化应用到校验块上面。另外的一些策略是基于Delta的方式,基本的做法是先读取数据块被更新范围内的数据,然后计算出delta(delta是新旧校验块由于数据块更新导致的差异),之后将更新范围内的数据和校验块detla发送到对应的节点,然后更新操作。这种方式的好处是发送更新范围和delta的方式减少了网络流量。
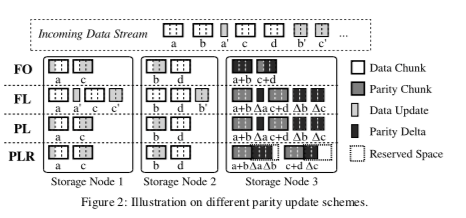
Parity Logging with Reserved Space(PLR)的思路是在校验块后面预留一部分的空间,用于后面的parity deltas的保存。这样的改进思路是比较简单的,PLR中提出这样的方式可以实现更多的顺序操作,从而提高性能。
0x11 基本思路
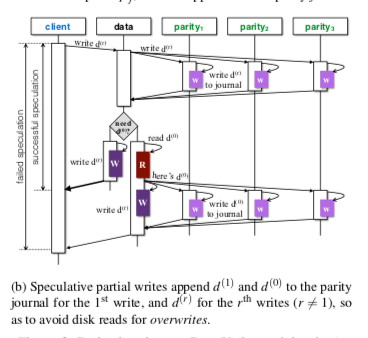
PARIX是在这些思路上面的继续改进,它基于这样的一个EC中的特点。校验块p,数据块d,校验块delta计为Δp,数据块delta记为Δd,则, \(∆p = A×∆d.\) 这里A为计算EC的系数矩阵,而且还有对于多次的更新,最终的结果只会和最初的数据和最新的数据相关。即可以表达为, \(p_j^{(r)} = p_j^{(0)} + \sum_{x=1}^r\Delta p_j^{(x)} \\ = p_j^{(0)}+\sum_{x=1}^r a_{ij}(d_i^{(x)}- d_i^{(x-1)}) \\ = p_j^{(0)} + a_{ij}(d_i^{(r)}- d_i^{(0)}).\) 基于这样的特点,一种思路是在校验日志上面记录最初的数据块的数据。这个数据只会在第一次的时候才需要被记录,在后面更新的时候,只需要利用最新的数据块,最初的数据块和最初的校验块,就可以得到最新的校验块。这样在更新数据块的时候,向校验块发送信息。如果是多次的更新,就只会需要第一次的时候校验块向数据块请求最初的数据,后面的时候就不需要做额外的处理了,是一种很巧妙的方式。
参考
- Ursa: Hybrid Block Storage for Cloud-Scale Virtual Disks, EuroSys ‘19.
- PARIX: Speculative Partial Writes in Erasure-Coded Systems, ATC ’17.
- Parity Logging with Reserved Space: Towards Efficient Updates and Recovery in Erasure-coded Clustered Storage, FAST ‘14.
