BTrim – Hybrid In-Memory Database Architecture for Extreme Transaction Processing in VLDBs
0x00 基本架构
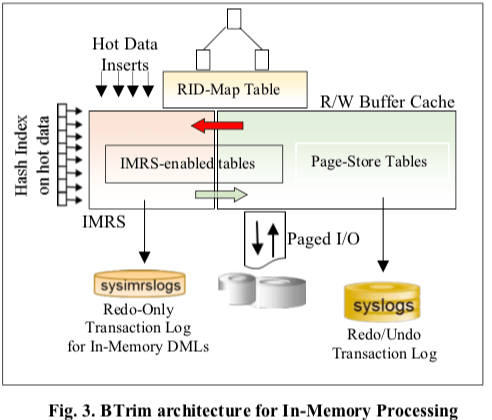
这篇Paper描述的是一种传统的基于Page的B+ tree存储加上另外的一个In-Memory Row Store (IMRS)结合而来的存储引擎/数据库的设计。IMRS用于处理数据库运行的热点部分的数据。BTrim的基本结构如下图,Paper中提到Btrim的价格设计很能和现在已经存在的部分结合,这个部分就是Page Store Tables部分。在加上了IMRS之后,相当于在原来的基础之上加上了一个hot rows caches layer,另外原来的Page Store Tables的Buffer Cache也是存在的。Page Store部分的组件,比如disk-based store, page-formatted buffer cache, 和 the redo/undo transaction logging等,不用做什么改动。在IMRS部分中,只会有一部分的数据保存在这里。
- 这里的IMRS保存的是hot rows就需要一个机制来在IMRS和Page Store Tables中转移数据。Btrim这里引入的ILM– Row-level Data Ageing机制。另外IMRS部分的数据持久化有一个原来Page Store Tables之外的sysimtrslogs实现。IMRS是一个内存中的组件。数据保存到内存中就需要一个机制来高效管理内存,Btrim中了一种best-fit策略 memory allocation。这个内存分配器支持一些固定长度的分配。分配之外就是内存回收,IMRS-GC机制使用了基于MVCC的一些特点。
- Btrim一条记录在Page Store Tables中的时候使用(page-ID, row#)来标识,在IMRS中使用一个Virtual RID (VRID)标识。在Btrim的设计中,进行基本的增查删改操作的时候,要操作的row可能在IMRS中,也可能在Page Store Tables中。并发操作的时候都使用RID来进行保护,这样并发在不同的地方操作也能保证正确性。
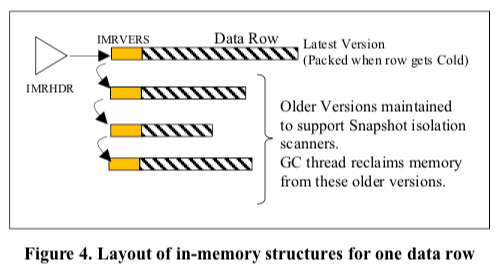
IMRS的操作也要和Page Store Tables部分一样支持基本的增查删改操作。在IMRS中一个记录有一个immutable header structure,称之为IMRHDR。另外数据部分使用多版本的方式保存,这里称之为IMRVERS。基本的结构如下图所示。每个版本的数据在创建完成之后,也会是immutable。这里的version称之为row version。在这些基本设计上面的增查删改的操作,1. 增,直接表现为在IMRS中添加一个记录,这样的记录称之为inserted rows。新添加的数据不会立即出现在Page Store Tables中。实际上,这里暂时会不会有Page Store Tables的参与,这样早这里的添加操作效率更高;Selects,Btrim的索引会处理一部分版本在IMRS中,而一部分版本的数据在Page Store Tables中的情况,这样的记录称之为cached rows。更新操作可能会有不同的情况,如果之前的记录在Page Store Tables中,则可能会导致一些数据转移到IMRS中,这样的记录称之为migrated rows。对inserted rows的删除表现为添加一个deleted version,而对migrated rows的删除表现为添加一个deleted version之外还有删除Page Store Tables的动作。
0x01 Index Management
在索引的设计上面,Btrim完整地支持了传统索引的功能。Btrim的索引的基本结构也是基于Btree的变种,其叶子节点保存的数据为{key-values, RID}形式,其中对于inserted rows,RID为VRID,而对于在Page Store Tables中的记录,则为实际的RID(在实际使用的时候RID和VRID估计就可以直接通过一个flag bit位来识别)。这样的设计也使得数据在IMRS和Page Store Tables之间的数据迁移变得比较容易。对于内存中的rows,Btrim使用一个RID Map来将RID映射位保存这些数据的内存地址。Btrim在索引的设计上面另外的几点,
-
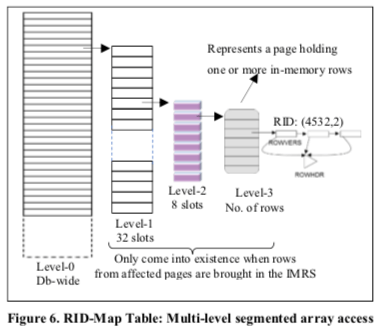
RID-Map使用的multi-level segmented-array的结构,基本的结构如下图。这里实际上的设计就类似于kernel中的multi level page table的设计。整个space中只会有比较小的一部分RID映射在这个RID Map中,使用一个完全数组去映射从空间上来看是完全不可行的,就很容易想到利用page table中的一些思路。
-
对于内存中的索引,paper中认为使用一个hash index在一些情况下能够带来不错的性能提升。Btrim的设计中考虑了不少OLTP的情况,OLTP的workload中一个事务一般只会访问很少量的一些rows,这样hash index显得更加合适。这里引入的hash index称之为Hash Cached BTree (HCB) index,只会记录在内存中rows,而之前已经存在的Btree索引则依旧保护完全的数据记录。
0x02 IMRS Durability
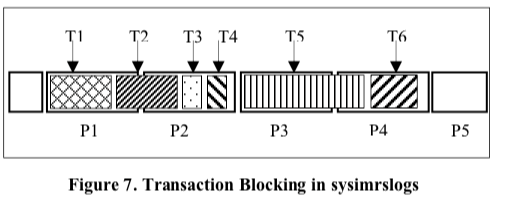
前面提到Btrim中,其架构设计中保护两个分离的log。IMRS中对应的log称之为Sysimrslogs。在Btrim中,一个基本的添加操作会导致IMRS中添加一个记录,另外Page Store Tables中索引也会添加一条记录,实际上会影响到两个地方,同样地一个简单的更新操作。在Btrim的设计中,更新的rows相关实际上在IMRS中操作,这样传统的Buffer Cache中刷dirty page等操作者syslogs中就不存在了。这样给性能提升带来了很大的空间。另外对于内存中的rows,Btrim采用了aggregate logging的优化策略,即对于哪些在一个事务中被多次更新的rows,只会有最好一个版本的数据被写入到日志中,
Next, only commit-time logging is performed. At commit-time, the in-memory versions, which are located easily off the transaction descriptor, are scanned, and log records are generated directly into sysirmslogs for the final images of modified rows. This way, at transaction run-time, no intermediate copies of log records are generated (in PLC) and the double-copying, like in syslogs, is avoided.
Btrim这样的设计另外的一个好处就是消除了undo log。日式的格式上面,Btrim使用了一种比WAL更加简单的设计。日志的空间按照page粒度分配,但是对于每个事务日志怎么样写入没有啥要求,可以跨page,也可以使用多个page的等。写入日志的空间可以分配给每个日志,这样日志写入的时候不同事务的写入操作实际上是没有冲突的,可以进行并发的操作。在Btrim的工作机制下面,在Crash Recovery的操作中,只要redo即可。因为dity page在Btrim中没有的原因,checkpoint操作也变得简单,只会有一些book-keeping持久化即可。Crash Recovery从添加到IMRS中最老的inserted row的日志记录开始,操作过程中要处理的时候要跳过无效的事务块,因为Btrim不保证sysimtrslogs不是没有空洞的。
0x03 评估
这里的具体信息可以参考[1].
FineLine: Log-structured Transactional Storage and Recovery
0x10 基本思路
这篇Paper提出了一种完全基于log的数据库的实现方式。畅通的数据库实际上是下图WAL+Database两个部分,数据也至少会写入两次。而FineLine提出的思路是只会写入日志。数据日志式写入log,然后在内部进行reconstruction,去读的时候使用fetch的方式从indexed log中获取数据。传统的数据以Page为单位组织数据,而在FineLine中基本的组织单位为node,于page不同,node大小是任意的,视为数据结构的一个部分。当然node也可以就是一个page的抽象,当node实现中代表了一个page的时候,FineLine类似于更加简单redo-only logging的数据库。当一个node表示单独的一条记录时候,FineLine更像是一个physical logging。
-
FineLine中,Log对外提交的两个核心接口是fetch 和 append,另外内部实现的reorganization复制组织还indexed log内部的数据。FineLine 在事务提交的时候append日志。和现在的一些数据不同,一个事务实际上会有多次的数据写入操作(比如MySQL中的MTR),而FineLine选择的方式提交的时候将每个private buffer中组织到一起,一次性写入到log中。
-
FineLine中同样也需要buffer management。FineLine中的buffer management实现地更加轻量。在FineLine的buffer management中,不需要处理维护PageLSN,单个node的数据持久化情况,以及将数据写入到持久化设备上面等的功能,这些有FineLine logging机制来实现,
(1) managing memory and life-cycle of individual nodes, (2) fetching requested nodes from persistent storage (i.e., from the log), (3) evicting less frequently- or less recently-used nodes, and (4) providing a transparent addressing scheme for pointers among nodes. -
FineLine中的transaction manager处理事务的运行、提交和回滚等的操作。事务运行的时候,相关的数据会被保存到 thread-local, per-transaction的log buffer中。在事务提交的时候,由FineLine的commit protocol将这些数据一次性持久化。
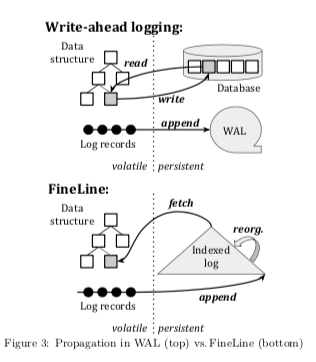
0x11 Logging
FineLine中indexed log实际上是一种partitioned index。传统的WAL通过LSN来维护log记录之间的全局的顺序关系,而indexed log中,一个partition内的记录由代表的操作应用到node顺序来排序,这里会有一个sequence number。fetch操作请求node A的时候,需要将示例图中A相关的partition拉去出来合并操作得到最终的结果。FineLine中是一次append操作会有一个新的partition。
-
FineLine中,一个工作现场执行一个事务的时候,相关的数据会记录在一个transaction-private log buffer中,在事务提交的时候,这个log buffer会被添加到一个全局的commit queue。这里操作完成之后事务达到一个pre-commit的状态,相关持有的锁等资源就可以释放了,因为这个时候事务实际的操作都已经完成了。但是目前还不能提交,因为日志还没有持久化。数据持久化的方式通过append到indexed log完成。
-
在commit queue中,数据最终还会是以page的形式组织好数据,然后append到indexed log中。这样的话就需要在append之前有两个层面的排序动作的,一个是node ID来排序,另外一个就是根据node-local sequence number来排序。这里排序就对应到了下图中的顺序逻辑。这里在append log实际由两种方式,
Each appended log page creates a new partition in the indexed log. An alternative implementation maintains the last partition unsorted, i.e., it retains the order of transactions established by the pre-commit phase. Since it is unsorted, the last partition can be much larger than a log page. To enable access to the history of individual nodes in this last partition, it must either be sorted or use an alternative indexing mechanism -
FineLine实际上使用了group commit的方式来在每次组提交的方式创建一个sorted partition。每次group commit定义来一个epoch,提交完成之后,client才会收到事务执行结果的通知。
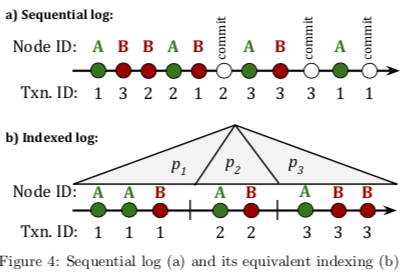
如果数据都是顺序写入的话,加上一些index,其查找的性能也会是很糟糕的。FineLine解决这个问题就是node的fetch和merge的机制。Partition会在后台被merged和compacted。这里的工作类似于LSM Tree Compaction的机制。为了方便处理merge和compaction的工作,FineLine中将Partition以⟨level number, first epoch, last epoch⟩三个维度来标识。Commit操作形成level为0的partition,epoch对应创建时候的epcoh,即此时标识为<0, e, e>,partition之间的merge操作会产生新的partition,记为⟨i + 1, a, b⟩,其中i为merge之前的level,而a为被合并partition的最小的first epoch,而b为被合并的partition的最大的last epcoh。Fetch操作会利用partition的标识信息等,
When performing a fetch operation, a list of partitions to be probed can be derived by computing maximum disjoint [first epoch,last epoch] intervals across all existing levels (i.e., the smallest set of partitions that covers all epochs). This can occur either by probing the index iteratively or relying on auxiliary metadata—such implementation details are omitted here.
FineLine的设计使得恢复也比常见ARIES方式简单,more…
0x13 评估
这里的具体信息可以参考[2].
参考
- BTrim – Hybrid In-Memory Database Architecture for Extreme Transaction Processing in VLDBs, VLDB ‘18.
- FineLine: Log-structured Transactional Storage and Recovery, VLDB ‘19.
