Unioning of the Buffer Cache and Journaling Layers with Non-volatile Memory
0x00 基本思路
这篇Paper的思路是将FS的Buffer Cache和Journaling做到一起。Paper中提到的测试数据表明,现在的日志式文件系统为了实现更好的一执行使用Journaling机制会增大不少的Write Traffic。这里的思路就是如何利用NVM的特性来优化Journaling操作。这里实现的系统称之为UBJ,在UBJ中,buffer cache的存储位置和 journal area分配在同一个存储区域,存储介质使用NVM。在这些设计下面,NVM的一个Block(这里使用Block的管理方式)可能是cache block类型, 或者是log block类型, 还可能是 cache 和 log 共同使用的block。UBJ中,Block存在多种的类型以及状态,基本表示如下图,
The frozen/normal state distinguishes whether the block is a (normal) cache block or a (frozen) log block. The dirty/clean state indicates whether the block has been modified since it entered the cache. The up-to-date/out-of-date state indicates whether the block is the most recent version or not. This last distinction is necessary as multiple blocks for the same data may exist in the buffer/journal space.
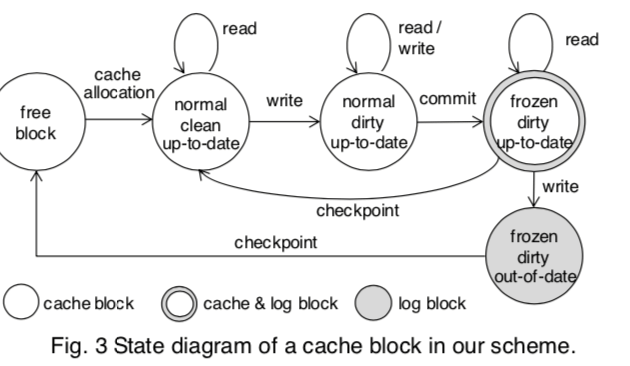
UBJ的设计在这样的基本思路下面的一些操作思路,
- Write/Read操作,写一个Block的时候,Normal状态的Block直接进行更新操作。状态是frozen的话,需要使用CoW的机制来更新,新的Block的状态是up to date,而之前的Block状态会变为out of date。Read操作就是直接读取。
- Commit操作。UBJ中事务提交会将normal dirty blocks转化为frozen dirty blocks。在UBJ运行中,running transaction会维护一个list,保存normal dirty blocks的信息。在发出commit操作的时候,running transaction转变为commit transaction,之前维护的Block会被直接就地commit。这里将这种机制称之为In-place Commit。这种变化只要改变一下block的状态即可,而不要一般的刷脏的操作。而在这里操作的时候产生的新写入的block将其当做下一个running transaction的block的来处理。这里之后transaction会转变为checkpoint transaction。
- checkpoint transaction用于处理将数据最终提交到文件系统上面。Checkpint操作会扫描checkpoint trisection中维护的blocks list,并尝试将其写入到文件系统。对于多次更新的blocks,只需要将最后一个版本的写入到文件系统即可。数据最终写入到文件系统之后,相关的Block就可以进行回收操作了。这个操作过程中,如果block的数据是最新的,其不一定要回收,还可以将转化为一个 normal 和 clean block,回到之前的操作流程。
0x01 评估
这里的具体信息可以参考[1]。
How to Get More Value From Your File System Directory Cache
0x10 基本思路
这篇Paper谈论的是Kernel中dentry cache的一些优化设计。Paper中总结在目前的Linux中使用的dcache基本结构是,1. 一个层次化的结构,每个parent dentry会包含一个没有排序的其内容的list,2. 一个hash table,使用其parent dentry虚拟地址和文件的名字作为hash key,3. 另外一个alias list用于处理inode的硬链接的问题,4. 一个LRU list用于实现LRU淘汰算法。另外的Linux dcache支持negative dentries,即缓存不存在的记录,用于查询没有存在的dentry的时候不支持老是穿透缓存。Linux目前的dcache设计中有基本不足的地方,1. 根据路径查找的时候要根据目录树来一层层查找,这个会导致多次的查询,2. 另外一个就是不支持读取目录内容的查询,使用ls之类的操作的时候总是穿透缓存。
0x11 Minimizing Hit Latency
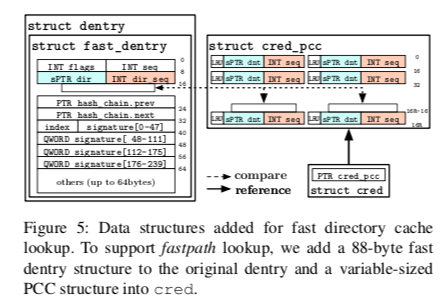
这里的思路是将根据路径查找时候的多次查询转变为一次查询。在Linux Kernel dcache目前的结果之前添加了一个direct lookup hash table (DLHT)用于实现根据路径的直接查询,这个实际上就是一个hash table,作为一个fast path的存在。当这个DLHT存在的时候,会先使用全路径作为hash key查找这个hash table。为了支持这个fast path,在struct path中提取出一个struct fast_dentry的部分。这个fast_dentry保存的时候选择不保存完成的key,而是保存起一个hash 值。除了这个DLHT之外,还有一个称之为prefix check cache (PCC)的hash table,PCC中缓存的是被缓存的dentry虚拟地址和其版本号,版本号用于处理一种corner case,比如一个dentry被释放之后有被重新分配使用,造成PCC中记录的地址实际上不是对应到原来的dentry,这里的方式是每次分配的是递增一个版本号,另外这个版本号最高为2^32-1,在超出这个数之后选择将这里缓存都清楚的做法。PCC的存在主要是解决路径上面的权限检查的问题。fast_dentry中主要包含了,signature、flags,一个sequence计数,mount point等。fastpath中查询的一般流程是先查找DLHT,若里面存在对应的记录在查找PCC,版本号匹配的情况下检查里面的权限。通过则返回结果。这里在实现上还有不少的chmod or rename操作的时候并发问题的处理[1]。也就是这里利用DLHT来缓存dentry,用PCC来缓存权限检查。
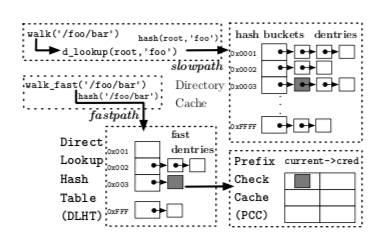
在一般的权限的问题之外,Linux中的extensible security module framework(LSM)可能覆盖之前的权限检查的逻辑,这里为了兼容这些也要做额外的处理。
-
LSM的问题,这里利用了kernel中的struct cred结果来处理,在task struct中会有一个指针指向这个结果。这个cred结构可能被多个进程共享,并且使用COW的机制。在修改这个cred的时候会拷贝一个新的cred结构。这里将cached prefix checks(PCC)的数据保存早cred中。cred在结构被初始化的时候PCC为空,
The PCC is added to the kernel credential structure (struct cred), and stores a tunable number of tuples of dentry pointers and sequence numbers; the system is evaluated with a PCC of 64 KB. Because the highest and lowest bits in each dentry pointer are identical, the PCC only stores the unique pointer bits (8–39 in x86 64 Linux) to save space.
-
在使用非标准话的路径的时候,一种作为是将其转化为标准话的路径表示在来进行查找。比如将/X/Y/./Z转化为/X/Y/Z。但是这里有另外的一些细节要处理,比如如果/X/L是一个symbolic link,/X/L/../Y实际对应到一个不同于/X/Y的路径。在使用/X/Z/../Y访问/X/Z的时候,即使有访问/X/Z的权限但是没有访问/X/Y的权限,这个权限检查也会是失败。这里处理symbolic links的时候,这里会创建一个特殊类型的dentry缓存,会讲访问转换到访问对应的dentry,
We resolve symbolic links on our lookup fastpath by creating dentry aliases for symbolic links. For instance, if the path /X/L is an alias to /X/Y, our kernel will create dentries that redirect /X/L/Z to /X/Y/Z. In other words, symbolic links are treated as a special directory type, and can create children, caching the translation. -
在处理Mount Points的时候也有不少的corner cases要处理。比如以read only的方式挂载的时候。挂载的时候也是挂到目录树的一个地方,在检查的时候也得能够识别出来。另外的一个问题是像proc, dev, 和 sysfs这样的伪文件系统可能被挂载到多个地方等等也要处理。还有就是Mount Namespace的问题,Linux中的 Namespace机制是一个很有用的功能。在Linux Kernel这样的一个负载的系统,这里的改动会设计到很多地方的细节上的改动[1]。
0x12 Improving the Hit Rate
这里的思路主要在亮点,第一个就是记录一个目录下面的内容被完全缓存了。另外一个优化是使用更加激进的Negative Caching策略。为了优化第一个点,这里在目录中缓存中记录了DIR COMPLETE的flag,在mkdir、完整地readdir一个目录的时候,这个DIR COMPLETE flag就会被添加。这样后面readdir操作的时候,就可以直接返回缓存的数据。对于那些知识readdir部分的操作,需要将这里得到的结果作额外的处理,这些不会被添加到其目录的DIR COMPLETE缓存中,不能用于后面的readir缓存但是单点查询还是可以的。这样完整的缓存的时候点查找不存在的对象的时候可以直接根据缓存中没有来回答这个对象不存在。negative dentries机制只能在一个不存在的对象被多次访问的时候获取比较好的效果,而DIR COMPLETE缓存可以在查询批量的不存在的对象的时候也能获得很好的效果。Paper中虽然DIR COMPLETE缓存这里说这样在并发的修改操作下面也是安全的,但是这里缓存的一致性会有很多的corner cases要处理,是一些很棘手的问题,不知道这里的具体的处理逻辑是什么,
We note that concurrent file creations or deletions interleaved with a series of readdirs will still be in the cache and yield correct listing results. After setting the DIR COMPLETE flag, subsequent readdir requests will be serviced directly from the dentry’s child list.
另外的就是更加激进的Negative Caching策略,主要包含这几个点:1. rename、unlink操作之后,原来的dentry就直接记录为negative dentry,用于回答后面的dentry不存在;2. 对于 proc, sys, 和 dev 这样的伪文件系统也使用negative dentries机制;3. 在前面的fastpath优化基础之上,对于查询/X/Y/Z/A这样的其中Z不存在的请求,支持在negative dentries下面记录一个negative children。也就是说在一个不存在的/X/Y/Z下面也可以记录A 和 A/B这样的negative dentries,这样在这样的查询缺失的时候也可以直接使用fastpath来回答。
0x13 评估
这里的具体信息可以参考[2].
参考
- Unioning of the Buffer Cache and Journaling Layers with Non-volatile Memory, FAST ‘13.
- How to Get More Value From Your File System Directory Cache, SOSP ‘15.
- GAIA: An OS Page Cache for Heterogeneous Systems, ATC ‘19.
