FStream: Managing Flash Streams in the File System
0x00 引言
目前的一些SSM中提供了Multi-Stream的功能。Stream可以看作是SSD中一种存储空间管理的形式,主要用于优化SSD的写入放大、GC等的问题。一般在SSD中,写入的单位是Page,擦除的单位是Block,一个Block会有多个Pages。如果一个Block被擦除的时候,里面存在还在被使用的Page,就需要将其转移到其它的地方保存,形成拷贝写入的操作造成了写入放大,也会降低GC的性能。Muli-Stream的基本思路是将有相近生命周期的Page放到一起,这样Block被擦除的时候有更大的可能能够一起就回收了。这样就带来了一个问题就是如何识别出生命周期相近的数据呢。FStream使用的是在文件系统层面修改的方法,将文件系统不同类型的写入当做不同的生命周期来处理。Linux中已经有相关的支持特性。
0x01 基本思路
FStream的基本思路比较简单,就是根据文件系统的特性来进行数据不同的生命周期区分。ext4文件系统基本的disk layout还是来自于Unix FFS,FStream具体的划分和ext4文件系统中对于的部分如下。
Mount-option Stream
journal-stream Separate journal writes
inode-stream Separate inode writes
dir-stream Separate directory blocks
misc-stream Separate inode/block bitmap and group descriptor
fname-stream Assign distinct stream to file(s) with specific name
extn-stream File-extension based stream
XFS的disk layout和ext4的有着最大的区别,于ext4使用bitmap管理磁盘空间不同,XFS使用的B+ tree。不过总体上面的思路没有太大的差别,
Mount-option Stream
log stream Separate writes occurring in log
inode stream Separate inode writes
fname stream Assign distinct stream to file(s) with specific name
0x02 评估
这里具体可以参看[1].
Fully Automatic Stream Management for Multi-Streamed SSDs Using Program Contexts
0x10 引言
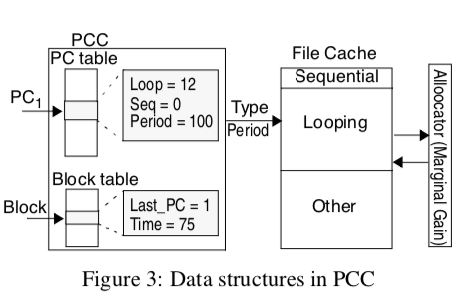
这篇Paper使用了一种很脑洞的思路,通过Program-Counter-based Classification (PCC)的方式来对数据的生命周期进行分类。PCC通过应用调用相关write接口(比如write、pwrite、writev之类的)来对IO Pattern进行分类。这种思路在04年的一篇paper[3]中被用于优化OS的Buffer Caching。[3]中利用PCC对IO进行这样的一些归类,Sequential references,Looping references和Other references。总体利用了两个hash table,一个PC table记录每次操作访问Blocks的情况(The PC hash table keeps track of how many blocks each PC accesses once (Seq) and how many are accessed more than once (Loop)。而Block table记录最近访问的M个Blocks,包含Block地址、最近PC的信息已经访问时间。基本的操作示例:一个IO操作触发的时候,首先从Block table中取回IO操作访问Block最近的PC和访问时间信息。从Block table获取的PC用于在PC table中查找。如果存在会递增Loop字段而减小Seq字段的值,因为这里被重复访问了。访问的间隔时间通过PC table和Block table中的Period和Time字段计算。
PCC(PC, Block, currTime):
if ((currBlock = getBlockEntry(Block)) == NULL) currBlock = NewBlockEntry(Block);
else { // the entry for last accessing PC must exist
currPC = getPCEntry(currBlock→Last_PC); currPC→Seq--; currPC→Loop++;
currPC→Period = expAverage(currPC→Period, currTime - currBlock→Time);
}
if (currBlock→Last_PC != PC) currPC = getPCEntry(PC);
if (currPC == NULL) {
currPC = NewPCEntry(PC); currPC→Seq = 1; currPC→Loop = currPC→Period = 0; Type = “Other”;
} else {
currPC→Seq++;
if (currPC→Loop > currPC→Seq) Type = “Looping”;
else if (currPC→Seq >= Threshold) Type = “Sequential”;
else { Type = “Other”; Period = currPC→period; }
}
currBlock→Time = currTime;
currBlock→Last_PC = PC;
return(Type, Period);
0x11 基本设计
PCStream这里也利用Program-Counter-based Classification (PCC)的思路,并分析了RocksDB、SQLite和GCC等查询发现其不同的写入存在一些生命周期的规律。以RocksDB为例,其写入主要来自几个方面:写日志、刷memtable和Compaction。这些操作走的不同的执行路径,很方便用于PCC方式中识别出不同类型的访问。PCStream这里要处理的一个问题就是获取程序运行时候的PC signature信息,之前的思路是使用的方式,因为现在的一些编译的时候消除了这个frame-pointer,比如GCC中使用-fomit-frame-pointer。PCStream使用的方式是write syscall被调用的时候,扫描一下程序的stack的word,其值在 process’s code segment中的时候就假设这个是一个return address,
Since scanning the entire stack may take too long, we stop the scanning step once a sufficient number of return address candidates are found. The larger the return address candidates, the longer the computation time. On the other han\d, if the number of return addresses is too small, two different paths can be regarded as the same path.
仅仅通过不同的Program Context来判断一个写路径上写入的数据的生命周期是不够的。Paper中举了RocksDB的例子,在Compaction的写入路径中,不同的Level Compaction写入之后的生命周期差别很大,但是其执行的是同样的程序路径。PCStream提出的第一个解决方式是一种ad-hoc的方式,即在一个PC显示出很大的生命周期的差异是,另外开辟一个internal stream,将其写入原来stream的数据写入到这个internal stream。这种方式的一个缺点是会造成使用的stream的数量翻倍。而一般的Multi-Streams SSD支持的Stream数量是比较有限的。PCStream使用了另外的思路。如下图所示,PCStream是实现在内核里面的,它可以控制很低层的东西。为什么支持streams数量有限的一个原因是stream写入的时候,需要一些后备电源来支持在突然断电的时候将没有持久化的数据持久化。另外为了性能考虑一个streams也会占用一些内部的内存。而如果直降internal stream用于SSD内部GC操作,则不用考虑这些东西。因为GC的时候要将要擦出的block中还有效的page拷贝到另外的地方,这个过程中断电也是没关系的,因为数据不会丢失。另外的一个就是SSD中的内存占用,一个GC操作后台任务运行,可以选择更少的内存占用的设计。
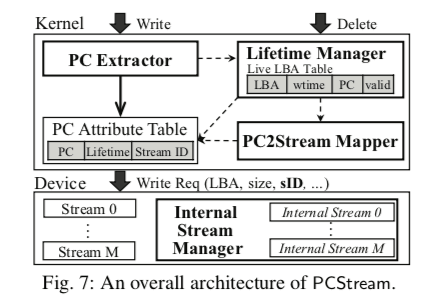
PCStream的总体结构设计如上图,总体上分为PC Extractor、Lefttime Manager和Internal Stream Manager等部分。对应到要实现PCStream思路要解决的几个问题,Paper中总结如下,
-
PC Lifetime Management。PC Lifetime Management的核心功能是估计出一个Program Context写入的数据的生命周期。一个新的写入请求到来的时候,PCStream会记录下来请求的时间、PC signature、以及会影响到的LBA。这些信息保存在 live LBA table中。 live LBA table使用LBA作为Key。在接受到与个TRIM请求的时候或者是对一个LBA的覆盖写入。利用LBA作为Key在live LBA table中查找。根据之前的信息和现在的信息估算出新的生命周期,删除和覆盖些会使用不同的计算方式。生命周期的这些信息保存在PC Attribute Table中。live LBA table可能占用了很大的内存空间,PCStream使用一种精确的方式来降低这个内存消耗。
he lifetime manager slightly sacrifices the accuracy of computing LBA lifetime by increasing the granularity of LBA lifetime prediction to 1 MB, instead of 4 KB. The live LBA table is indexed by 1 MB LBA, and each table entry holds PC signatures and written times over a 1 MB LBA range.PC attribute table记录了一个PC signatures到其预测的生命周期、Stream ID等的信息,使用hash table实现。这个table的大小不会很大,不用和live LBA table一样需要额外的处理。
-
Mapping PCs to SSD streams。在预测出一个生命周期之后,PC2Stream mapper将生命周期相近的操作映射到同一个stream。这样映射同样是解决stream数量有限而PC signatures可能很多的问题,映射通过k均值算法来进行分组。分类之后这个stream id会保存在PC Attribute Table中,之后的写入请求之后读取PC Attribute Table中的stream id即可。另外为了处理生命周期变化的情况,PCStream会在适当的时候进行重新聚类的操作,必要时更新一个PC signature对应的stream id。
-
Internal Stream Management。Internal Stream Management实现更加底层,在上面的结构图中被实现在设备内部,因为internal streams的实现要涉及到内部结构一些管理。PCStream认为,如果短生命周期的page混合在长生命周期中,则GC的时候,拷贝到interl stream会更有可能是长生命周期的,短生命周期的更加可能已经失效了。
-
PC Extraction for Indirect Writes。这样主要是为了解决这样的一些问题:如果是C/C++这样的编程语言些的程序,直接调用相关接口,计算出PC signature比较简单的。但是如果是java之类写的程序;或者是一些数据中,比如MySQL、PostgreSQL这样的一个地方先写入自己管理的buffer中,另外的地方进行flush操作的,识别起来就比较麻烦,
The problem of indirect writes can be addressed by collecting PC signatures at the front-end interface of an intermediate layer that accepts write requests from other parts of the program.
0x12 评估
这里的具体信息可以参考[3].
参考
- FStream: Managing Flash Streams in the File System, FAST ‘18.
- Fully Automatic Stream Management for Multi-Streamed SSDs Using Program Contexts, FAST ‘19.
- Program-Counter-Based Pattern Classification in Buffer Caching, OSDI ‘04.
- AutoStream: Automatic Stream Management for Multi-streamed SSDs, SYSTOR ’17.
