LogDevice: A Distributed Data Store for Logs
0x00 引言
LogDevice是Facebook开发的一个存储日志类似数据的存储系统(不是存储日志数据)。在LogDevice中,一个写入的记录都是顺序写入,会赋予一个唯一的LSN,这个LSN规定了日志记录之间的顺序关系。在读取的时候,LogDevice可以保证不同的客户端读取的时候都以同样的顺序读取到这些数据,而且在发生数据丢失的时候,可以报告某个LSN数据以及丢失了。LogDevice中一个设计特点是non-deterministic decentralized record placement,也就是是说一条记录保存在集群中哪一台机器上不是确定的。这样的设计在对于写入处理是有利的,但是读取的话需要麻烦一些,LogDeice会有对应的机制来处理。在LogDevice Docs中提到LogDevice适合这样的一些应用场景,
Write-ahead logging for durability
Transaction logging in a distributed database
Event logging
Stream processing
ML training pipelines
Replicated state machines
Journals of deferred work items
0x01 基本架构
LogDevice的基本架构如下,写入的时候经过类似proxy的一层,这个称之为log sequenceers。log sequenceers的主要功能是对于多个writers写入的记录赋予一个LSN,作为一个log上面不同记录之间的顺序关系。在读取的时候则没有这个log sequenceers一层,readers直接链接storage nodes进行读取。一条日志记录会保存对个副本,保存到storage nodes中指定数量的节点上面,保存一条日志记录的节点集合称之为copyset。数据副本数量记为R,LogDevice中这个值一遍为2 or 3。根据前面的描述,LogDevice有个non-deterministic decentralized record placement,意味着一条日志记录的copyset可能是storage nodes任意的一些。在日志记录写入的时候,其在哪里保存,保存的顺序和日志记录之间LSN决定的顺序是没有联系的。数据读取的时候会涉及到一个nodeset的概念,这个是storage nodes中,了样保存一个log的nodes。nodeset的数量一般小于storage nodes的数量。这个nodeset数量选择和log的复制策略相关,也和non-deterministic decentralized record placement特点紧密相关。对于一个log的nodeset,它是可以随时改变的,这些信息会记录在log的元数据中。这些元数据使用类似于Zookeeper的系统中。数据读取的时候,由于non-deterministic decentralized record placement特点,一个简单的策略是将nodeset中的数据都读取出来,然后去重、排序。这样的方式带来的性能影响比较大,LogDevice会有对应的优化方法。LogDivce的LSN包含了两个部分,一个4byte的epoch number和一个4byte的offset。Epoch是分布式系统中一个常用的设计,LogDevice这样用这个解决sequencer故障的时候依然保证LNS递增的问题。这些epoch的信息保存在epoch store中。epoch store使用类似Zookeeper这样的系统保存。
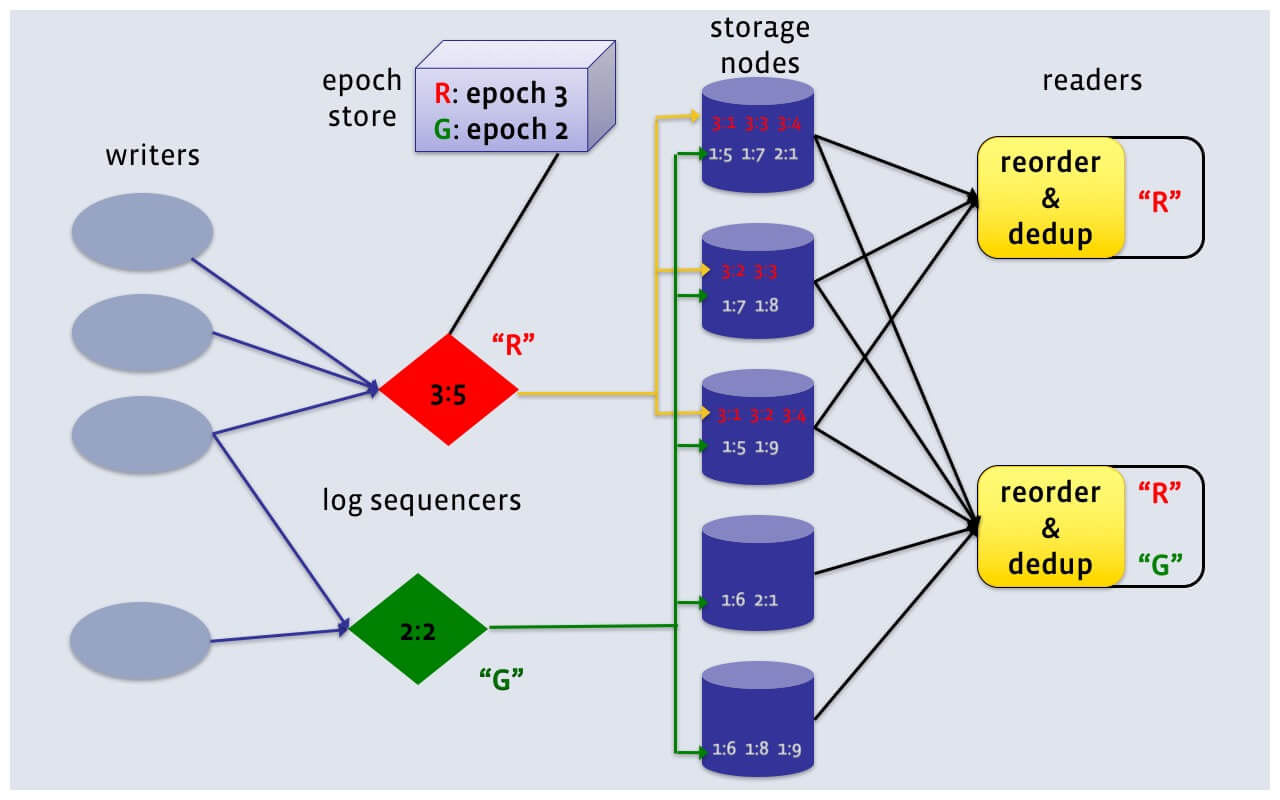
LogDevice保存数据的组件称之为LogsDB,实际使用来RocksDB来保存。LogDevice将数据一个(log id, LSN)作为key,数据作为value的方式保存到RocksDB中。一个LogsDB被划分为多个shards保存到不同的机器上面,一个机器上面一个shard有一系列的partition组成。一个partition保存一个shard一段时间内的数据,大小一般选择为几个GB级别。新写入的数据被写入到最后一个partition,但是这里和很多的系统不同,之前的partition也是可以写入的。不够钱吗的partition保持写入的能力主要是为了处理rebuilding的情况,这种情况下,之前的partition也可能被写入一些数据。
0x02 Write/Read路径
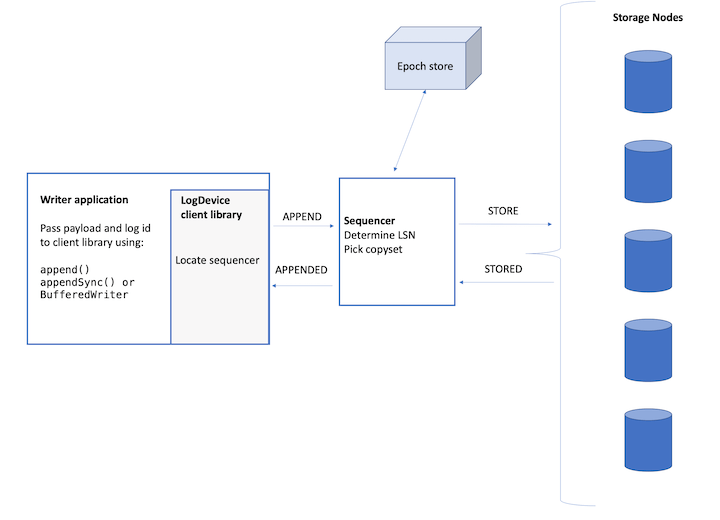
应用使用LogDevice提供的Client进行写入操作,写入的时候要经过sequencer进行排序。基本的写入逻辑如下,
- 应用通过LogDevice将payload和log id请求。客户端会通过基于gossip协议来进行故障探测,如果通过一个hash是否将请求路由到其中的一台sequencer。客户端想这个sequencer发送APPEND请求,sequencer在接收到这个请求之后,为这个日志记录生成一个LSN。这个请求然后被发送到存储节点,在满足了保存副本数量要求之后,一个APPENDED信息被返回个客户端。
- 在写入的时候,虽然使用基于gossip协议来进行故障探测,发现面前可用的sequencer。但是这里还是不能完全保证每个Client看到的可用的sequencer集合都是一样的。这种情况下,最常用的一种方法是使用一种机制来保存每个log只有有一个sequencer来赋予LSN。类似于Bookkeeper中使用的那样。但是在LogDevice文档中好像没有找到类似的记录。这个理应该就是集成到了epoch获取的逻辑中,一个sequencer获取到一个epoch就类似获取到了一个lease。这个lease可以其它的sequencer抢占。
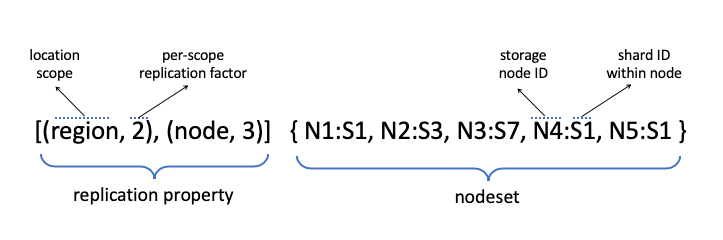
Replication property作为元数据的一部分被保存。基本结构如下。nodeset作为storage nodes中可以保存这个log数据节点的集合保存到元数据中。如果这个nodeset需要变化,必须更新epoch。在sequencer写入数据的过程中,sequencer会创建一个appender state machine。
-
之后nodeset中挑选出一个copyset,这个copyset的大小有replication property决定。然后发送STORE请求到copyset所有的节点。请求发送出去之后,节点存在几种情况,1. 没有回复sequencer的节点被分到graylists中,2. 将返回了但是返回的是错误信息的节点保存到blacklists中。如果存在没有返回的or返回错误的,从nodeset中重新挑选忽略graylists和blacklists中节点的copyset重新发送请求。当然如果都成功了,直接返回成功就可以了。
-
为了提高写入的性能,LogDevice使用pipelining append的方式写入数据。但是出于inflifht状态的请求不能太多,这里LogDevice就引入了一个sliding window,类似于TCP中的sliding window。这样的设计引入了另外的几个概念,1. last known good (LNG):LogDevice支持乱序的ACK,所有sliding window中可能存在ACK的“空洞”,对于最早的前面没有看懂的ACKed的记录称之为 last known good (LNG)。推进LNG就是推进sliding window。
-
一个日志记录在对reader可见之间,必须要release操作。得满足这样的一些条件,1. 前面的记录已经被复制到足够数量的副本上面,2. 前面epoch的操作都已经完成。需要release的一个原因是读取的时候Client是直接连接storage nodes读取的,使用没有release操作告诉storage nodes一条记录被正确保存下来的话,storage nodes是不知道这个情况的。这个release引入的一个概念就是The release pointer is the LSN,
* The “last known good” indicates the last acknowledged and completed append of an epoch. The storage nodes use it as a checkpoint. * The release pointer is the LSN of the last completed append of the log. All records up to and including that LSN, including all previous epochs, have been stored consistently. The storage nodes deliver records to readers up to the release pointer.
在读取的时候,应用使用LogDevice Client下面这样的API进行读取操作。基本就是从一个起始点出发顺序读取。要读取的时候,就需要知道log的copyset。一个log的copyset在不同的epoch下面可能是不同的。这些元数据信息被保存到一个metadata log中。metadata log保存了一个log的数据库变化的log。Client从元数据中获取到copyset,然后发送[start, util]的信息到storage nodes,表示要读取这个范围内的数据。在读取的时候Client需要进行额外的一些工作,
- Flow control,类似于TCP中的flow control概念。避免storage nodes过快的速率想Client发送数据。
- Re-ordering,storage nodes发送过来的数据是乱序的,需要根据LSN进行重新排序。
- De-duplication,不同的storage nodes可能发送重复的数据,需要进行去重的操作。
* startReading (log id, from log sequence number (LSN), until LSN = MAX) — non-prescriptive reading
* read (count, records_out, gap_out) — records_out vector, gap_out vector is returned
在读取的时候,一个很重要的操作是gap detection。因为LogDevice只能保证LSN是递增的但是并不是连续的。LogDevice需要知道哪些LSN是实际上就不存在,而那些是数据丢失了。LogDevice的gap detection算法中,一个重要的概念称之为f-majority,f-majority就是任何一个copyset会交叉的数量,其值为|nodeset|-R+1。这样f-majority集合的补集就不能凑成一个完整的copyset。如果客户端从超过了|nodeset|-R+1接收到从来没有收到一个LSN的记录的信息,这样就不需要询问其它节点了,因为这样的LSN表示的记录肯定不能写入完成。如果客户端收到了一个大于之前等待的最小的LSN的正确的记录,而又有f-majority数量的节点回复了这个LSN,表明这个LSN不存在,则说明这个LSN的数据丢失了。在处理这里的时候,为了应对一些nodeset中机器故障case,引入Authoritative Status来拓展f-majority概念[2]。读取的时候LogDevice引入来single copy delivery (SCD)来进行优化,其基本思路是copyset中的节点经过一种shuffle算法来决定某一个节点发送实际的数据,而不用所有的节点发送。
0x03 副本&容灾
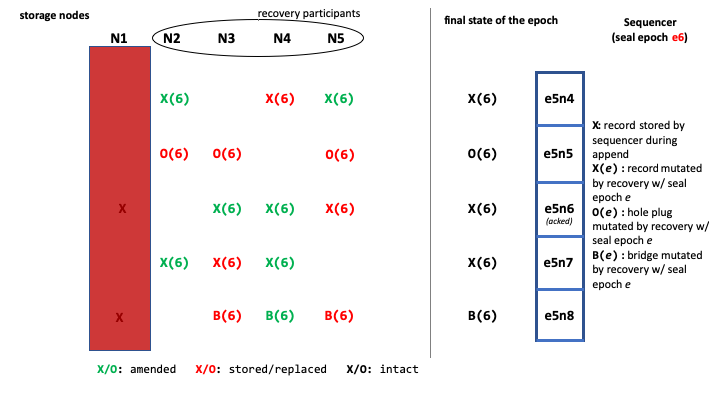
Sequencer故障的时候,LogDevice的处理主要分为两步,1. Sequencer Activation,新的Sequencer被激活,之前的Sequencer故障之后,一个新的被激活。新的Sequencer先想epoch store申请一个新的epoch,然后进行Log Recovery的操作。LogDevice设计上是的一个epoch被申请之后就可以进行写入操作。但是这些新写入的记录不能被release,还要等Log Recovery操作完成。Log Recovery要使得,1. 之前给writer返回成功的记录不能被标记了没有写入成功,2. 故障造成的LSN gap应该被报告为gap,而不是数据丢失,3. 恢复操作完成之后,之前epoch的数据就是不可变了的了。下面是一个Log Recovery操作的记录。在之前的Sequencer故障致,其中的e5n6记录已经被ack。另外副本的数量设置为3。有一些记录被复制到这个副本数量。这个时候Sequencer和storage node N1都故障了。

一个新的Sequencer起来之后。Log Recovery主要的流程,1. 通知storage nodes不在接收小于epoch 6的记录,2. 根据读取的结果将可以完成复制的记录完成复制,而没有的数据记录为空洞, hole plug 。在完成了恢复操作之后,结果如下。数据存在但是R小于3的被重新复制到3,而不存早记录为hole plug。在最后一个offset记录为一个brige gap记录,标记之后是gap,跳到下一个epoch。重新复制有处理storage nodes故障,acked的记录也可能没有R个复制的情况的考虑。
在一个storage nodes or 磁盘等故障时,LogDevice需要补齐不足副本数量的记录,这个过程称之为Rebuilding。Rebuilding操作通过一个event log完成,这个event log为storage node之间运行的一个复制状态机。在发现需要进行Rebuilding操作的时候,节点发送一条SHARD_NEEDS_REBUILD信息来开启Rebuilding操作:1. 获取到一个log的那些shards需要进行Rebuilding;2. 从目前的Sequencer中获取到一个log 目前的LSN,一般的情况就是恢复操作的这个LSN,until_LSN(Unless this is a mini-rebuilding, we need to rebuild up until that point (the until_LSN))。没有可用的Sequencer的情况下,需要激活一个;3. 从metadata log中取回元数据。 恢复操作需要等到目前的LSN被release。RebuildingCoordinator通过一个copyset index来获取要从其中读取数据的节点。这个index就是一个类似于(log id, LSN, copyset)的表。RebuildingCoordinator从copyset挑选,称之为copyset leader。RebuildingCoordinator之后的操作就是:1. 创建一个RecordRebuilding;2. 选择一个新的节点来保存这个数据,这个节点还不在copyset之中;3. 在一个记录被复制完成之后,发送出这条记录的节点向copyset其它节点发送一条AMEND信息,更新记录元数据中的copyset信息;4. 这个节点再更新本地copyset信息;5. 复制完成,复制状态机器被删除。每个记录的copyset leader不一定相同,通过这样的并发的方式来修复提高速度。这里还有更多的细节[3].
0x04 评估
这里的具体信息可以参考[1,2]。
参考
- https://engineering.fb.com/core-data/logdevice-a-distributed-data-store-for-logs/, LogDevice.
- https://logdevice.io/docs/Concepts.html.
- https://logdevice.io/docs/Rebuilding.html.
