A Lightweight and Efficient Temporal Database Management System in TDSQL
0x00 Temporal DBMS
这篇Paper挺有意思,其中描述的是一种Temporal/时态数据库系统的设计。Temporal数据库一个核心的一个地方是会保存一个数据记录多个版本。这个多个版本和MVCC中的多版本不是同一个大小,MVCC中的一个记录的多版本主要用于并发控制,逻辑上面一个记录就是一条记录,对数据库用户是透明的。而Temporal数据库中一条记录会保存一条记录随着时间变化形成的版本,对数据库用户是可见的。一个Temporal表的例子,这种常见的一个用途就是记录一个账号余额的变化,
ID Player Bal Transaction Time
r1.1 James 0 [2018-05-20 06:20:00,2018-10-21 00:30:00)
r1.2 James 50 [2018-10-21 00:30:00,2018-11-01 09:01:41)
r1.3 James 1000 [2018-11-01 09:01:41,2018-11-12 00:00:10)
r1.4 James 2000 [2018-11-12 00:00:10,∞)
r2.1 David 150 [2018-10-20 20:10:10,2018-10-20 20:40:00)
r2.2 David 200 [2018-10-20 20:40:00,∞)
r3.1 Jack 200 [2018-11-08 10:12:43,∞)
Paper中描述了TDSQL中支持不同的Temporal Data Model,
-
Valid-time data model。这种模式下面,一个记录类似于{U, VT }模型,U就是普通数据库记录中的属性,VT是这条记录的valid-time period。
-
Transaction-time data model。不同于Valid-time data model,这种模式下面一个记录类似于{U,TT,CID,UID},U为普通数据库记录中的属性,TT为 transaction-time period, CID为创建这条记录的事务的ID, 而 UID为删除/更新这条记录的事务的ID。
-
Bi-temporal data model。这种模式下面一个记录类似于{U,VT,TT,CID,UID},是前面两种模式的组合形式。这些模式下面一个记录的在一个时间内的有效性和事务上的可见性判断使用如下的思路:
We denote VT as a closed-open period [VT.st, VT.ed), and TT as [TT.st, TT.ed). VT.st, VT.ed, TT.st, TT.ed are four time instants. For valid-time, a record is either currently valid if VT.st ≤ current time < VT.ed, or historical valid if VT.ed ≤ current time, or future valid if VT.st > current time. For transaction time, a record is said to be a current record if TT.st ≤ current time < TT.ed, and a historical record if TT .ed ≤ current time.
0x01 基本架构
在Temporal数据中,创建一个表有相关的SQL拓展。在查询上面也会有时间上的相关拓展,比如使用OVERLAPS、CONTAINS作为一个谓词在where语句种使用判断一个Temporal记录是否是复合查询条件的记录,等等。
-- 第一种模型的表
CREATE TABLE R (ID INTEGER, Period VT);
-- 在创建的时候可以指定一些约束条件, 比如下面的例子约束VT不能有重叠
PRIMARY KEY (ID, VT WITHOUT OVERLAPS)
-- 第二种模型
CREATE TABLE R (
ID INTEGER
) WITH SYSTEM VERSIONING;
-- 一些Transaction-time Queries查询的例子
-- (1) FOR TT AS OF t, which restricts records that are readable at t
-- (2) FOR TT FROM t1 TO t2, which restricts records that are readable from t1 to (but not include) t2,
-- (3) FOR TT BETWEEN t1 AND t2, which restricts records that are readable from t1 to (and include) t2.
-- 查询
SELECT ID, Player, Bal FROM R WHERE Player = 'James'
AND VT CONTAINS DATE '2018-10-30'
FOR TT AS OF TIMESTAMP '2018-10-11 00:00:00'
SELECT ID, Player, Bal FROM R WHERE Player = 'James'
AND VT.st ≤ DATE '2018-10-30'
AND VT.ed > DATE '2018-10-30'
FOR TT AS OF TIMESTAMP '2018-10-11 00:00:00'
系统的基本架构如下图所示,主要和Temporal相关的几个地方就是Parser,主要就是处理在SQL上面的拓展。Query optimizer and executor负责将Temporal相关的查询转化为查询计划,并进行优化。Storage engine则要复杂将表的数据和历史的数据保存下来。
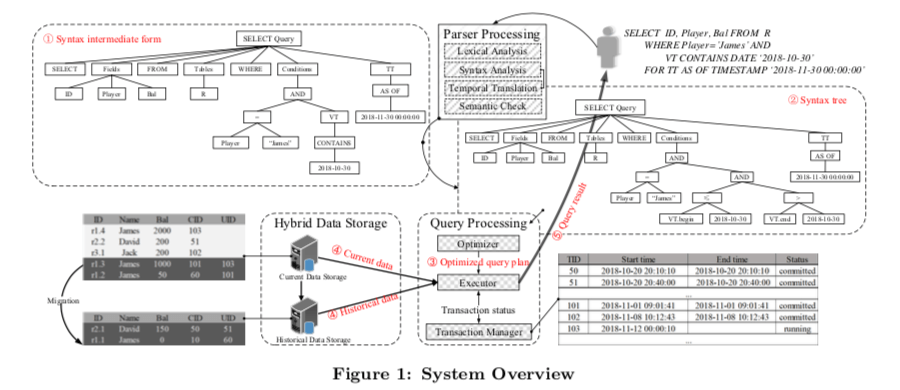
0x02 存储和查询处理
Temporal Data Storage
很显然如果将一条记录所有的变更都保存在一个表的空间之中的话,这个表会膨胀得很严重,一些操作如范围查询的性能也会很糟糕。TDSQL的思路是将目前的数据和历史的数据分开保存的思路。TDSQL的Temporal Data Storage实现上面利用来数据MVCC的机制,
- 总体思路上是目前的数据和历史数据分开保存。在一些基于MVCC的数据库如MySQL中,老版本的数据在新版本的数据添加之后会保存在一个rollback segment, or 其它的保存机制。这些数据会被TDSQL转移保存到另外一个地方。这里使用的就是Key-Value Store来保存。不同的历史版本保存使用基于Delta的方式,即有一个版本保存了完整的数据,后面的版本保存和这个版本的差异。这个也是MVCC多版本实现的一种思路,在比如MySQL这样的数据库中就是使用了这样的方式。KVS为有序的结构,Key就是primary key 加上 transaction IDs,这样同一个数据不同的历史版本就会保存到一起。
- 这里另外的一个问题就是什么时候将rollback segment之类的地方的历史版本的数据转移到KVS中存储。TDSQL中使用一个vacuum cleaner线程来周期性地处理数据转移的工作。执行这里的工作的时候,vacuum cleaner现场扫描rollback segment中的数据,如果rollback segment中一个page的max id(max transaction id)比目前系统中还在使用的最老的snapshot id还要老,就表示不属于目前活跃的数据,对应的记录会被暂存到一个undos集合中。之后启动几个worker将这些数据转化为key-value pair并发送到KVS中保存。
Temporal Query Processing
在Paper中这里主要讨论了两个问题,第一个问题就是如何处理transaction-time queries的问题。另外的一个就是如何执行Record Visibility Check。前者的问题在与TDSQL的Temporal数据库功能是实现在传统的关系性数据上面的,很多在时间的时候没有在记录中保存commit time的信息。而MVCC的机制依赖于记录的start time和commit time,前者主要的功能就是决定相关的事务操作能看到哪些数据,后者决定这条记录能被哪些事务看到。而直接改动原来的设计添加commit time信息会是一个很麻烦而且开销不小的操作,这里使用的一种优化的策略,
-
解决第一个问题是在系统中引入了一个 transaction status manager,用户维护事务的一些status信息,包括commit time, 一个running/committed/aborted 的状态信息。这些信息保存在一个transaction log中。在事务创建的时候添加到transaction status manager中,在事务commit or abort的时候添加更新commit time,状态等的信息。在数据转移的时候,通过记录关联的transaction ID来找到对应的 commit time。这样在历史数据中就可以显式的用commit time这个信息,而当前数据table的结构不用去改动。
-
另外一个处理的问题时Record Visibility Check,TDSQL使用的是一种snapshot based approach的机制。一个事务在启动的时候会被赋予一个唯一的snapshot,这个snapshot会包含这样的一些信息,
(1) S.tids includes all active transactions’ IDs when a snapshot is generated; (2) S.min represents the minimum transaction ID in S.tids; (3) S.max is the first unassigned transaction ID; (4) S.creator is the snapshot owner’s transaction ID.在Record Visibility Check的时候主要分为两种主要的查询case,as of和from to(and between and)类型。这两种类似的检查只有一个地方不同,前者是从新的版本向前面找,找到第一个表示就可以停止查找,而后面一个需要查找到所有的在条件区间内的版本。在temporalCheck
# Algorithm 2: currentStorageRead(S,μ)) input : snapshot S, query type μ output: versions φ meet the temporal condition φ←∅; if μ=as_of then // Candidates:records should be check foreach rec ∈ Candidates do while rec <> null do if rec.cid >= S.max ∨ (rec.cid ∈ S.tids ∧ rec.cid <> S.creator) then // fetch the previous version rec ← prevV er(rec); continue; if temporalCheck(rec) then φ ← φ∪{rec}; break; else rec ← prevVer(rec); if μ=from_to ∨ μ=between_and then foreach rec ∈ Candidate do while rec <> null do if rec.cid >= S.max ∨ (rec.cid ∈ S.tids ∧ rec.cid <> S.creator) then // fetch the previous version rec ← prevVer(rec); continue; if temporalCheck(rec) then φ ← φ∪{rec}; rec ← prevV er(rec); # ---------------------------- # Algorithm 3: temporalCheck(υ) switch μ do // get commit time from trsancation log γst ←getCommitTime(υ.cid); γ_ed ← getCommitTime(υ.uid); case as_of do if γ_st ≤ ts ∧ γ_ed >ts then return true; case from_to do if γ_st < ts2 ∧ γ_ed > ts1 then return true; case between_and do if γ_st ≤ ts2 ∧ γ_ed > ts1 then return true; return false;
0x03 评估
这里的具体信息可以参考[3].
Scalable Garbage Collection for In-Memory MVCC Systems
0x10 引言
这篇Paper描述了Hyper内存数据库GC的改进设计,这个Garbage Collector称之为Stream。Stream总体上思路和HANA中采用的基于Interval的思路一致。基于Interval的主要是因为处理长事务和短事务混合的workliad中,由于长事务导致的一些version的数据不能及时回收的信息,Interval思路是识别一个Interval中不会被任何事物访问,从而将其回收,而不用一定要等到比这些Version老的Version都能回收才能回收。不过Stream选择使用处理事务的现场在工作的时候进行GC,而不是和HANA一样使用后台的GC线程来执行GC任务,这么设计的思路是因为在事务现场执行的时候已经获得了version chain的锁,直接执行GC的时候就不用像使用另外的线程那样还需要获取一遍锁。MVCC的GC主要涉及到下表中5个方面的设计,
- Tracking Level。从什么样level来追踪可以回收的version。从细粒度的每个tuple的粒度,到粗粒度的table的粒度。另外还可以追踪每个事务相关的version信息。基于Epoch也是一种方式,基本思路是通过将txn根据执行的事务归类为一个个epoch,在epoch粒度上面进行回收。
- Frequency and Precision。这里主要设计到以什么样的频率进行回收,常见的是周期性触发GC方式。另外的方式有在基于threshold的方式,在资源使用到一个程度的时候进行回收的操作。Hyper选择的时候在事务Commit的时候进行GC的操作。
- Version Storage。Version Storage涉及到如何保存多版本的数据。有每个version都保存完整数据的方式,后者是像Hyper一样记录的是这个版本和前面版本的delta,即差异的方式。这些信息被Hyper保存在一个Undo Log的位置。
- Identification。这里主要涉及到如何识别可以回收的版本。基于Epoch的机制中version属于某一个epoch,系统周期性向前推进epoch,在哪些较老的epoch不会在访问的时候就可以回收相关的version。Hyper使用Txn List的方式,根据最新的statTs和commitId来确认哪些version不会早被访问,从而可以进行回收。Stream这里在Hyper原来的GC方式上优化为一种Local List的方式,在后面有详细的介绍。
- Removal。这里主要涉及到由谁来进行GC的操作。on-the-fly选在在事务处理的时候,遇到可以回收的数据就直接进行回收操作,这样回收的方式在version chain是从老到新顺序的时候比较适用。Hyper使用的是Interspersed的方式,GC操作有前台执行事务的现场完成,但是在事务提交之后进行GC的操作。另外的就是使用专门的现场后台扫描进行回收。Stream这里采用的是on-creation的策略,在添加新version数据的时候进行GC的操作。

0x11 基本思路
在Hyper的设计中,事务的执行维护了两个全局的有序的list。一个active transactions list在分配一个新的事务的时候被添加到这个list中,另外一个committed transactions list在一个事务被提交之后被添加到这个list中,但是对于只读事务,不会有添加到committed transactions的操作。active transactions list使用事务的startTs来排序,这样哪些commitId ≤ min(startTs)的version就可以进行回收操作。这样的设计引入了Stream的第一个优化设计,Scalable Synchronization。
-
Scalable Synchronization。这里的优化主要就是设计到操作这两个list的优化,修改这个两个list的时候要回去一个全局的mutex,这样并发高的时候会引入不小的同步的开销。Stream并没有采用Latch-free的方法,因为其认为Latch-free并不是一个非常好的选择。Steam选择使用每个现场单独的list代替全局的list,这样的好处就是优化了同步的开心,缺点是一些数据可能被保留稍微上一点的时间。线程会保留出本地list的最小的startTs等的信息,一个线程在读取了全部的thread-local信息之后就可以获取到全局的最小的startTs等的信息。这样有一个问题就是一个线程在idle的情况下没有更新这个thread-local的信息,导致GC受阻,所以需要系统周期性地在合适的时候触发GC。
-
Eager Pruning of Obsolete Versions。这里的思路就主要涉及到了在Stream中也使用HANA中基于Interval的机制。使用全局最小startTs和commitId的方式会导致,一些长事务存在的时候会很多不会被访问的version不能回回收。因为可能有更老的version在被长事务访问。为了识别可以回收的Interval,Stream使用了类似HANA类似的方法。在设计上,Paper强调的和HANA中使用不同的是Stream不是使用和HANA周期性地触发后台现场进行GC的方式,而是在事务现场在访问version chain的时候就进行处理。Steam认为HANA的方式有一些缺点,
When HANA’s GC thread is triggered, it scans the set of versions that were committed after the start of the oldest active transaction. ... . This causes additional chain accesses, whereas Steam can “pig- gyback” this work on normal processing. Since HANA calls the interval-based GC only periodically, the version chains are not pruned and grow until the GC is invoked again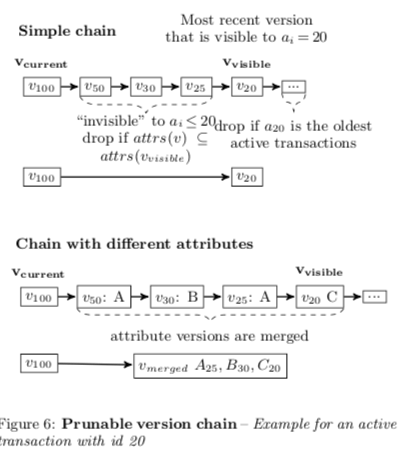
-
Layout of Version Records。这里主要讨论的是Hyper保存记录的时候一些优化内存使用的方式,很工程的风格。这的思路是针对不同记录的类似,记录有不同的布局,对一些字段有不同的解释。另外还为bulk operation,批量操作提供了一些优化方式。
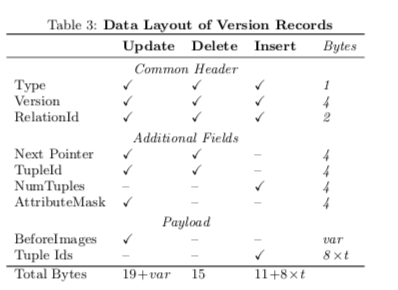
0x12 评估
这里的具体信息可以参考[2].
参考
- On Supporting Efficient Snapshot Isolation for Hybrid Workloads with Multi-Versioned Indexes, VLDB ‘19.
- Scalable Garbage Collection for In-Memory MVCC Systems, VLDB ‘19.
- A Lightweight and Efficient Temporal Database Management System in TDSQL, VLDB ‘19.
