FPGA-Accelerated Compactions for LSM-based Key-Value Store
0x00 基本思路
这篇paper是关于如何用FPGA处理LSM-tree Compaction的问题。LSM-Tree的Compaction是LSM-Tree设计实现中一个很麻烦的问题,处理不好就容易导致性能的问题,特别Compaction带来的性能抖动。LSM-tree的Compaction操作会消耗大量的资源,这篇Paper的思路就是将一部分Compaction的操作offload到辅助计算设备上面,这里使用的是FPGA。之前微软有一些关于用FPGS处理网络的研究,而这里则是用来处理一些存储系统的问题。
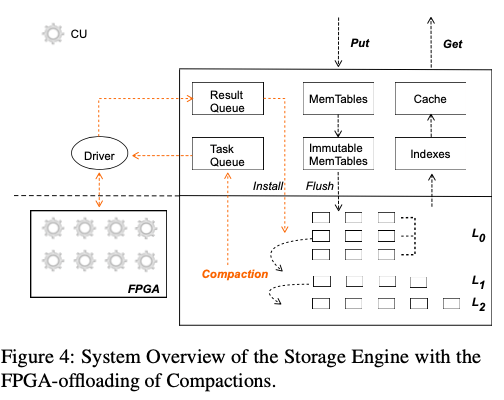
0x01 基本设计
这里设计的基本架构如上兔所示,由于FPGA的工作模式和CPU存在很大的差别,不是一般意义上面的冯诺依曼架构。一般在利用FPGA处理认为的时候,很常见的一个实现方式是想要工作拆除一个个流水处理的单元。这里也是使用这样的思路。由于FPGA这里作为一个协处理器的角色,很多事情还是要CPU来处理。这里CPU要处理的事情就是将工作任务包装作为一个个的Task的抽象,并要负责这些Task的调度以及直接结果的处理。基本的处理如下图所示,工作流程中主要有这些的一些角色以及其处理的工作,
- Builder线程。在一个Compaction操作被触发知乎,Builder线程负责将要进行Compaction的数据进行拆分,包装为一个CompactionTask的结构。在这个结构中,主要的字段是指向对应的task queue、输入数据、运行结果以及回调函数等。一个CompactionTask构建之后被添加到一个Task Queue中,等待被FPGA执行相关的操作。FPGA处理完毕之后,结果被添加到Result Queue,Builder线程也会检查Result Queue,处理FPGA返回的结果。在FPGA处理识别的时候,会转移到CPU处理逻辑,Paper中提到FPGA处理会有0.03%左右的识别概率,主要是一些比较长的数据字段导致的;
- Dispatcher线程。Dispatcher线程线程负责从Task Queue获取Compaction Task,然后分发到合适的FPGA的Computation Unit来处理。这里使用的负载均衡的测量就是简单的RR测量;
- Driver线程。Driver线程负责负责相关的数据传送,并在将数据传送到FPGA上面的时候,通知FPGA进行实际的Compaction的操作。在一个Compaction Task操作完成的时候,Driver线程会执行回调函数,用于将操作之后的数据传送回主机内存。然后将结果push到Result Queue中。
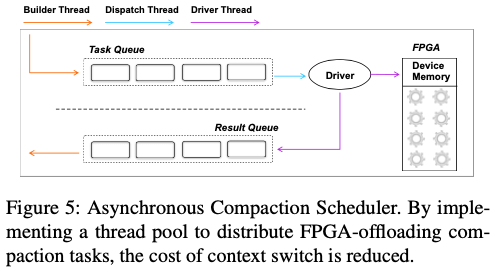
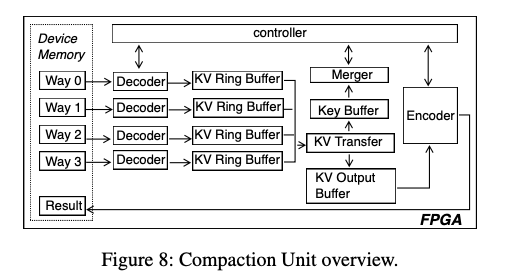
FPGA上面的处理实际上就是一个多路归并的过程。这里的LSM-Tree使用的Tier Level的分层的方式,意味着一层内的SST文件的Key Range是可能重合的。这里带来的是写入性能的提升,但是读取的想念回变差。这个时候就想要将一些SST文件归并操作,达到提高性能的目的。这里从内存中输入来的多路数据,会先进入一个Decoder来对数据进行decode的数据,方便内部操作这些数据。这些多路归并的路树选择是一个想要tradeoff的问题,这里选择的是4路,一般和具体的情况相关。在decodeer之后是一个ing buffer,用于暂时保住被decoded的数据,
The KV Ring Buffer caches the decoded KV records. We have observed in our practices that KV sizes rarely exceed 6KB. Thus, we configure each KV ring buffer to contain 32 8KB slots. The additional 2KB can be used to store meta-information such as the KV length.
之后就会进入一个合并操作的流程,KV Transfer组件将Key传送到Key BUffer,然后有Merger组件进行实际的多路归并的逻辑。这里只传送的Key,而不需要处理Value。Merger处理之后,满足条件的数据会被发送到KV Output Buffer。这里的条件应该会包含新旧数据的处理、被删除数据的处理等。经过Encoder的处理得出结果。这里可以看出来这里可以看作是一个多路归并操作的FPGA实现。
0x02 评估
这里的具体信息可以参考[1].
HotRing: A Hotspot-Aware In-Memory Key-Value Store
0x10 基本设计
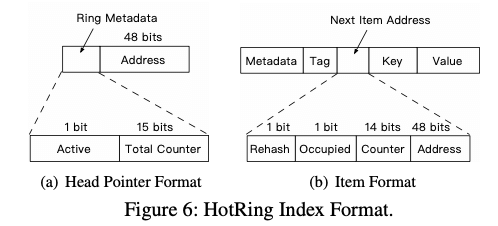
HotRing为一个机遇Hash Table的内存KV Store的设计,其的基本思路很有意思:HotRing通过将Hash Table中一个Bucket的Key Value连成一个环。为了处理热点Key,通过没经过R次访问之后,就觉得是否改变这个Bucket Header指针指向这个环的位置。在热点Key存在的情况下,Header会倾向于指向热点Key的位置,从而提高性能。这里具体的数学分析可以参考[2],不过思路是挺直观的。另外HotRing还有几个额外的优化设计,比如在查询不存在的Key的时候,会导致查询操作遍历整个Bucket Ring。这样查询不存在的Key会明显低于查询存在的Key的性能。HotRing的优化方式是将Ring中的数据有序保存。在查询的时候,如果前一个数据比查询的数据小,而后一个又更大的话,就可以直接返回NotFound。
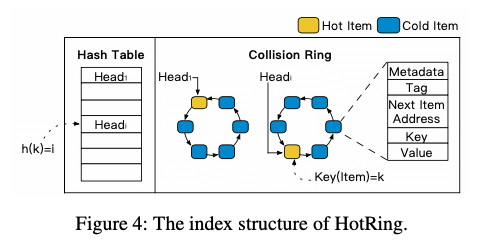
另外一个就是热点Key的处理。Paper中提到了两种思路,一种是在R次访问之后,就决定是否改变header指向Ring中的位置。如果决定改变,改变为随机改变。这样策略在没有热点的情况下效率一般。另外一种策略是利用目前64位环境下面,指针只使用了其中的48bit。Header指针剩余的16bit被分为了两个部分:一个Active bit,为控制位,在一个线程记录访问R次之后,判断目前header指向的是否还是热点,如果是,则关闭Active Bit,以减少计数带来的开销,如果不是,则开始新的计数,如果在下一轮发现那个是热点的时候,根据item format中的计数值来判断;另外一个是Total Counter*(15 bits),这个记录对应bucket的访问次数,另外是每个item的访问次数统计。而Key-Value Pair中的next指针被分为了4个部分,其中两个控制字段,一个计数值。根据bucket的计数值和item的计算值,计算出head指向ring的哪一个item的时候平均的访问次数最小。HotRing的并发操作还是类似于RCU的那一套。
参考
- FPGA-Accelerated Compactions for LSM-based Key-Value Store, FAST ‘20.
- HoRing: A Hotspot-Aware In-Memory Key-Value Store, FAST ‘20.
- BCW: Buffer-Controlled Writes to HDDs for SSD-HDD Hybrid Storage Server, FAST ‘20.
- INFINICACHE: Exploiting Ephemeral Serverless Functions to Build a Cost-Effective Memory Cache, FAST ‘20.
