Fault-Tolerance, Fast and Slow: Exploiting Failure Asynchrony in Distributed Systems
0x00 基本思路
这篇Paper是Raft,ZAB之类分布式一致性协议的一些优化。这里提出的优化称之为situation-aware updates and crash recovery (SAUCR)。现在的很多一致性协议的实现,为了保证数据的持久化,会在返回结构之前使用fsync之类的方式来将数据刷到磁盘上面,数据每次都持久化可以提供可用性,降低数据丢失的风险,但是也会损失一些性能,而另外的对应设计是Log保存到内存中就返回,优缺点互换。SAUCR从实际的数据中分析出,在集群中会经常有机器故障,但是有多台机器同时故障的概率是很低的的。SAUCR从这点出发,给出了一个Memory Log和Disk Log结合的设计:在集群完整正常运行的时候,出于fast mode情况下,数据保存到内存中就可以直接返回,而如果一部分的机器故障,则切换到slow mode,数据得fsync到磁盘上面才能返回。这也主要影响到Raft、ZAB的两个方面的设计,一个是如何在这两种模式下切换,另外一个是恢复如何处理。
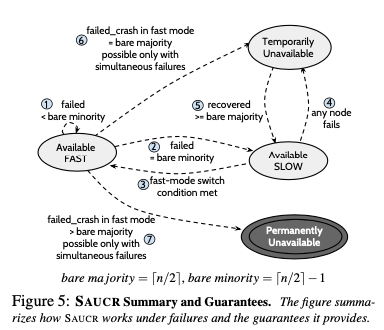
Mode Switches
SAUCR在集群中有超过bare majority个节点正常工作的情况下出于fast mode。Bare majority即指的是刚好超过一般的节点数量,而超过bare majority最少的输入自然就是bare majority + 1。这样看来,如果集群的节点数量,SAUCR是起不到优化的作用的,所以Paper中讨论的时候都是假设系统是5个节点。至于为什么要比bare majority还要多1,主要和SAUCR恢复操作相关。故SAUCR假设Protocol是一个leader-based的协议,所以这里故障分为leader的故障和follower故障,
- follower故障,在follower故障到只有bare majority正常工作时(leader认为目前是这样,不一定实际上就是这样)。Leader会发送一个特殊的请求。Followers在收到这个请求的时候,需要将内存中的数据flush到磁盘上面,而且确定数据被持久化之后才能返回给leader这个请求。之后的运行就会处理slow mode状态。而如果leader重新认识到集群中有足够数量之后,可以统一发送一个特殊的请求来将mode切换到fast mode。
- leader故障,followers在通过hearbeat的方式认为leader故障的时候,就会将自己内存中的数据flush到磁盘上面。
也就是说对于一个节点,其故障之后,可能以及返回给client的数据已经丢失了。节点故障恢复需要知道其故障之前处于的mode。这个也是在log中记录特殊的一条记录。在处理fast mode下面的第一个请求之前,节点在日志中记录fast-switch-entry,并持久化。这条日志中会记录下<epoch,index>。同样的在切换到slow mode的时候,flush内存中数据的时候也会记录一条latest-on-disk-entry。通过这两种特殊类型的entry就可以知道故障之前节点处理的mode。在回复处理的时候,一个节点需要知道在故障之前其已经写入了多少的日志,如果是处理slow mode下面,这个操作时trivail的,直接从磁盘上就可以获取到。但是在fast mode下面,可能之前写入的日志已经丢失了。最好一条写入的日志称之为last logged entry,LLE。在fast mode故障的情况下,需要从其它节点来恢复这个节点的LLE的数据,还要从其它节点恢复丢失的数据。
恢复
LLE Map用于处理LLE的问题,包含了每个节点在log复制到了哪个epoch那个index下面,记录为⟨S1 :e.10, S2 :e.10, S3 :e.10, S4 :e.10, S5 :e.5⟩。这个MAP由leader发送给其它节点,而fast mode下面的节点将其保存到内存中,slow mode保存到磁盘上面。Slow mode下面的恢复操作和一般的算法没有很大的区别,fast mode下面的会有额外的处理,
A fast-mode crash recovery, however, is more involved. First, the recovering node would not have its LLE on its disk; it has to carefully recover its LLE from the replicated LLE-MAPs on other nodes. Second, it has to recover its lost data irrespective of whether it becomes the leader or a follower.
SAUCR使用max-among-minority算法来恢复LLE。一个节点会现标记自己为recovering状态,然后发送LLE查询到其它的节点,其它的节点只在recovered状态的时候才会回复信息。在收到bare-minority = ⌈n/2⌉ − 1个节点恢复的时候,取其中最大的最为其LLE。bare-minority和前面的bare-majority相对,指的是刚好少与一半的节点的数量。LLE MAP处理了这样的情况:5个节点相继挂了3个之后,剩下的两个节点会处理slow mode下面,但是这个时候不能正常工作的,需要等待其它节点的恢复。如果恢复的是最后一个故障的节点,这个节点会在slow mode下面故障的,则可以正常进行新的选举流程。如果恢复的是fast mode下面故障的节点,则它不知道自己的日志在故障之前写入到哪里了,由于在Raft这样的进入选择需要知道自己之前日志写到哪里,这样的话就选举操作就会失败,从而集群无法恢复到可用的状态。另外一个问题就是fast mode下面为什么要比bare-majority + 1个节点成功才能返回成功。一个case如下:
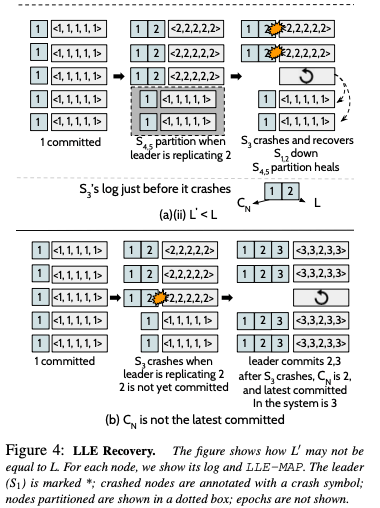
上图中的第一个,复制1的时候,5个节点都复制成功的。在复制2的时候,4、5节点和leader S1失去了联系。之后集群会进入到slow mode状态。2复制到了1、2、3号节点。在一个的协议中,这个时候就可以返回成功了,因为复制到了多数节点。但是SAUCR中不能给请求2返回成功。如果这个时候节点1、2故障了,而3恢复,节点4、5的网络隔离恢复。如果请求2提交了,这个时候会发现2并没有在半数以上节点存在,恢复的时候就会认为2美元提交从而造成数据丢失。所以这里请求2不能提交。不提交的时候这种情况下,节点3通过max-among-minority算法算法就可以知道之前写到了请求1。
0x01 评估
这里的具体信息可用参考[1].
Strong and Efficient Consistency with Consistency-Aware Durability
0x10 基本思路
这篇Paper和上面的这篇出自同一个实验室。这里提出的思路称之为consistency-aware durability(CAD),CAD的基本思路是允许写为异步持久化的方式,即写入的时候不强制fsync数据到磁盘上面,但是读取的时候,要求数据持久化之后才能读取。CAD在实现cross-client monotonic reads特性的基础之上在一些workload下面优化了性能。和前面的SAUCR一样,CAD也是假设在一个majority-based系统下。CAD的改动主要就是read逻辑上面的改动,而写和恢复的时候就喝noforce fync模式下面的类似。这篇paper中开发的系统称之为ORCA。
-
在读取一个item i的时候,ORCA会保证读取到的是这个item最新的状态,并且这个数据会持久化。读取的时候会有两种情况,第一个是读取的时候这个状态已经正确持久化了,另外的一个case是这个状态还没有持久化。前面一种case的处理是trivial的。而后面一种会需要额外的处理。一个leader接收到一个read请求的时候,这个leader需要将到这个item最新的log index的位置已经之前的log全部都持久化,另外一个需要发送信息给followers将这个index之前没有持久化的数据持久化。
-
限制读取都从leader读取的时候这样的处理就足够了。当时限制只能从leader会限制read性能的提升。而从follower读有可能违反cross-client monotonic reads的特性。ORCA使用active set的机制来解决这个问题。基本思路:active set至少包含了majority nodes。
R1: When the leader intends to make a data item durable (before serving a read), it ensures that the data is persisted and applied by all the members in the active set. R2: Only nodes in the active set are allowed to serve reads.通过上面的两条规则保证了follower也会有最新的数据而去被读的已经持久化了。只是有active set还是不够的,因为数据被更新的时候,leader通知active set里面的节点可能是不。所以这里需要一个lease机制,这里和[3]的思路比较类似,具体可以参考[2,3].
Fine-Grained Replicated State Machines for a Cluster Storage System
0x20 基本思路
这篇Paper也是FSM之类Protocol的一个优化。比如用Raft实现KV Store的时候,常用的方法就是对Key进行一个Partition,每个Partition上面运行一个Raft,做成一个Mutil的版本。这里的一个tradeoff就是Partition数量和由此带来开销之间的一个tradeoff。由于KV Store不同的Key的操作是不互相影响到,理论上Partition越多,可实现的并发度更大。这篇Paper提出fRSM进一步提出了Partition细粒度到当个Key的思路,为了避免为每个Key维护一个log,这里直接将RSM的状态和Key-Value Pair一起保存。RSM的逻辑和Paxos之类的算法没有太大的不同。在Key-Value的结构上有额外的一些元数据。基本思路如下,
- 一个Key-Value Pair除了数据之外,还保存了,1. epoch number,代表了Key-Value的“代”,每次删除有创建的时候被增加;2. timestamp,一个epoch之内的更新会导致增加逻辑上面的timestamp。epoch加上timestamp对应到了Paxos中的instance number;3. promised proposal number 和 accepted proposal number,对用到Paxos系统的概念;4. chosen bit,表示目前保存的value是不是被选择达成consensus的value。
CAS Processing
对于KV Store,如果支持CAS会是一个非常有用的功能。fRSM也支持CAS操作,CAS要求先读取一个Key,获取到之前的epoch e和timestamp t的信息。之后执行CAS操作会要求带上这个信息,之后这个t会被更新为t+1。这个CAS可以看作是Paxos的一种变体,基本操作流程,
- Retrieve key’s consensus state,CAS请求被路由到leader来请求。leader先从本地读取这个key的信息,比如包含proposal number Pp和目前accepted value的Pa;
- Prepare reques,如果Pp为不同的节点发出的,leader产生一个更大的Pp。然后将请求发送到其它的节点。leader需要等待超过半数节点的返回。如果是leader发出的而去Pp和Pa相等;Prepare handler,如果这个Pp就是最大的,则不会在accpt比这个更低的Pp。并会吧这个信息持久化保存下来;
- Accept request,Leader发送一个accept请求给其它的节点。带有新的t=t+1,目前的epoch已经前面的Pp;Accept handler,每个副本判断的时候,如果目前的timestamp还是之前的t,且Pp大于等于本地保存的,则可以进行更新的操作。
- Accept response processing,半数以上accepted的时候,leader就可以标记chosen bit,并返回给客户端。不让accept请求是不满足CAS的条件,则返回CAS错误给客户端,如果是其它的导致accpet请求被reject,则可能需要重试操作;
这里整体上还是Paxos算法的一种实现。
Read Processing
Read操作要求返回最新的被chosen的数据,还要处理之前的<epoch, timestamp>更高的accepted不被被chosen。后面的条件主要主要是为进行中的CAS在后面不会成功。read操作被分为leader-only reads, quorum reads, 和 mutating quorum reads这三种模式。leader-only的时候自己的数据是不是最近被chosen的,如果是则返回个client。不是这个模式的时候,leader需要询问其它的副本最近的被accepted的value。如果没有value,leader需要将value复制到至少一个quorum数量的节点上面。这里这样处理主要是考虑网络分区下面的一些操作,比如这个时候的leader可能实际上和集群中另外半数以上的节点网络分区了,但是目前还没有发现,
- Quorum read request,leader发送一个read请求到其它的节点。这些节点恢复恢复clock属性,即前面讲到的4个元数据字段,已经数据本身;
- Quorum read response,leader在接收到response之后,检查response中是不是有<higher epoch, timestamp>的情况,已经是否有一个quorum报告了最近accept的value。如果leader没有最高的epoch和timestamp对应的value,从返回中获取最佳accept的数据,如果一个quorum的节点数据报告没有value,则需要复制这个value给它们。
- Check for outstanding accepted values,leader会检查是否存在这样的情况,如果有promise的proposal number大于等于目前知道的最大的proposal number,并带有accept的数据,且做出promise的节点没有回复clock属性。则进入阻止其它的操作提出的方式。这里通过更新t的方式完成,即Update timestamp to quench outstanding accepts。Pp表示到不了的节点发出的proposal number。leader发出一个prepare请求,带有更高的Pp,然后发送accept请求更新value,epoch和timestamp。这样的操作主要是为了阻止之前的CAS提交。
一般情况下,leader only的模式就够用了,mutating quorum reads模式为了处理这里有一个不可达的节点,而且这个节点获取到了更新这个key的promise的情况下才会进行。
The quorum reads are performed when the leader is not operating in leader-only mode immediately after a failover. In this case, the leader has to communicate with the other replica nodes in order to process the read request. If the most recent accepted value is not available on a quorum or if there is evidence of an unreachable node with an outstanding promise, then we resort to mutating quorum reads...
Scalog: Seamless Reconfiguration and Total Order in a Scalable Shared Log
0x30 基本思路
Scalog是一种Shared Log的改进思路,Shared Log的最典型的一个设计是CORFU。另外Facebook最近开源了一个保存日志式数据的项目,称之为LogDevice,前面一个讲了。CORFU和LogDevice一个特点是在数据写入之前都会有一个Sequencer的角色,用于对这些写入进行排序,而Scalog认为操作方式限制了性能,而其思路是先保存数据,然后在进行排序的操作。Scalog的基本思路如下。下面的例子中,Client是可以进行并发写入的,这个和目前一些开源的分布式系统有点不同,不少是一个时间只支持一个writer。Scalog的基本操作流程中,Client讲写入请求发送给storage server。数据在Scalog中被划为shards保存,而且和一些Kafka之类的系统不同,kafka只保证党个shard/partition里面的写入是有序的,而Scalog则保证在不同的shards里面也是有序的。即Scalog维护了log entry之间的全序的一个关系。写入的记录被复制到backup上面,这里要主要复制得是FIFO的,要保证Primary节点和Backup节点上面的日志的顺序是一致的。所以Backup上面的log segment会是Primary的一个前缀。
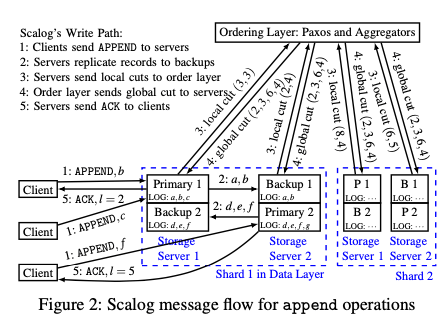
这里就需要处理如何对写入的记录进行全局定序。Ordering Layer负责处理顺序的问题,通过Paxos实现Ordering Layer的高可用。Storage Severs会周期性地讲想Ordering Layer报告log segment的长度。如上图,Storage节点1和2报告了两个不同的Segemnt保存到的位置,单机上面的不同的segment组成的vector称之为local cut,Ordering Layer在组合里这些local cut,从而得出全局的global cut。Scalot通过这种方式来获取log目前正确持久化的位置。同时一个shard的写入是顺序的,复制到backup上面的时候也是FIFO的方式,保持了和Primary顺序的一致。这里另外的一个问题是如何在这样的工作模式下面获取全局的顺序关系?即如何获取写入到不同shards的记录之间的顺序关系呢?对于并发的请求,cut之间的顺序就是order layer决定的。这种模式下面,处理sequence空洞可以比较简单一些。
The difference between any two cuts determines which records are covered by those two cuts. We use a deterministic function that specifies how to order the records in between two consecutive cuts. In our current implementation, we use a simple lexicographic ordering...
0x31 评估
这里的信息可以具体参看[5].
CRaft: An Erasure-coding-supported Version of Raft for Reducing Storage Cost and Network Cost
0x40 基本思路
这篇Paper的Idea很有意思,把Erasure Coding和Raft算法结合。标准的Raft算法每个节点上面保存的是一个数据的副本,而CRaft选择保存EC编码的一个快,比如3+2的编码,同样是5个节点,而且都能过实现坏了2个的时候还能使用。有了这个基本的Idea之后,CRaft的基本算法没有太多特别的地方。假设集群中节点数量为N,EC编码的参数应该满足k + m = N。另外一个参数F即满足2F+1=N。
-
CRaft数据复制的时候,会被发片/快,每个快会记录在原来数据中的位置。Leader复制数据的时候会将复制给每个节点一个fragment,而不是完整的数据。另外Leader在复制数据的时候,会保证至少有(F + k)个节点回复成功才会成功,这里和一般的Raft有点去吧。在Leader故障的时候,新选出的Leader必须包含前面所有数据的副本的一个fragment。在发送节点故障的时候,除了数据恢复得根据其它的fragemnts来计算处理,其它的流程和Raft一样的。
-
另外一个要处理的情况是节点中没有 (F + k)个节点可以正常工作的情况下,如何处理?CRaft的解决方式是转换到完整复制的模式。这样这里就和原来的Raft算法没有很大的区别了。这个时候需要记录目前处于的模式。
-
在新Leader被选举的时候,由于Leader可能只保存了一个log entry的一个fragment,而不能保证这个log entry是可以恢复的。CRaft可以保证以及被Committed的数据在副本数量满足要求的前提下,总是可以恢复的。CRaft还需要一个LeaderPre的操作来处理不能保证恢复的log entry。查询能否恢复的方式是查看还有没有满足要求数量的fragments存活 or 存在一个完整的副本(因为之前可能也处于完整复制的模式而是EC的模式),
For each entry, if there are at least k coded-fragments or one complete copy in (F + 1) answers, it can be recovered, but not allowed to be committed or applied immediately. Otherwise, the new leader should delete this entry and all the following ones (including complete entries) in its log. After recovering or deleting all the unapplied entries, the whole LeaderPre operation can be done.
参考
- Fault-Tolerance, Fast and Slow: Exploiting Failure Asynchrony in Distributed Systems, OSDI ‘18.
- Strong and Efficient Consistency with Consistency-Aware Durability, FAST ‘20.
- Paxos Quorum Leases: Fast Reads Without Sacrificing Writes, SoCC ‘14.
- Fine-Grained Replicated State Machines for a Cluster Storage System, NSDI ‘20.
- Scalog: Seamless Reconfiguration and Total Order in a Scalable Shared Log, NSDI ‘20.
- Balakrishnan, M., Malkhi, D., Davis, J. D., Prabhakaran, V., Wei, M., and Wobber, T. 2013. CORFU: A distributed shared log. ACM Trans. Comput. Syst. 31, 4, Article 10 (December 2013), 24 pages. DOI: http://dx.doi.org/10.1145/2535930.
- CRaft: An Erasure-coding-supported Version of Raft for Reducing Storage Cost and Network Cost, FAST ‘20.
