Pingmesh: A Large-Scale System for Data Center Network Latency Measurement and Analysis
0x00 引言
Pingmesh是微软开发的一个测量数据中心中网络延迟和丢包率的Paper。Pingmesh在这个方面是一篇比较重要的文章。Pingmesh的思路在于使用数据中心内全部的服务器进行TCP or HTTP的ping操作,来测量数据中心内部的网络情况,可以提供最大的覆盖率。测量到的数据会被汇总处理,之后在多个层面展示数据,比如一个机架内的、以ToR交换机为一个抽象节点的已经整个数据中心层面的等。这个系统也是微软在实际的环境中使用的多年的一个系统。
0x01 基本设计
Pingmesh的基本架构如下,主要包含这样的一些组件:1. Pingmesh Controller,用于控制每个server上面的agent的操作。会对每个server产生一个pinglist文件,这个文件包含了这个server需要ping的servers已经相关的参数。这个pinglist有Controller根据网络拓扑产生,server通过一个RESTFul的API获取到;2. Pingmesh Agent,Agent从Controller下载pinglist文件之后,会对这个pinglist中的server进行TCP/HTTP的ping操作,将数据保存在本地的内存中。在一段时间过后 or 本地buf的数据达到一定量之后,在这个数据上报保存到一个分布式存储系统Cosmos中。另外Agent也会收集一些性能统计信息,会讲这些信息上报到Perfcounter Aggregator中;3. Data Storage and Analysis (DSA),这个DSA就是用于数据处理、分析用的。
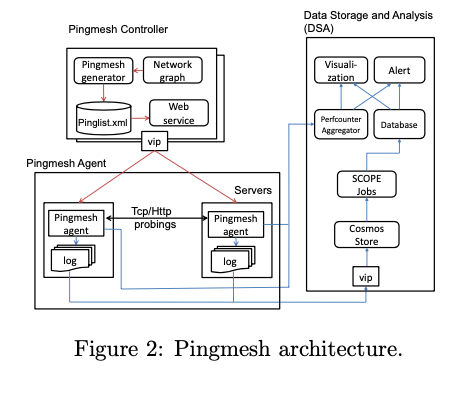
- Pingmesh Controller,Controller的一个核心功能就是产生pinglist。这个的设计考虑了从不同的层面,首先是一个Rack/Pod level的,这里应该就是单个的server,另外就是一个intra-dc的level,这里不是将每台server作为一个节点,而是将一个ToR作为一个抽象的节点,减少节点的数量,还有局势inter-dc level,每个数据中心作为一个虚拟的节点。虚拟的节点不执行实际的ping操作,而是选中这个节点中的一些server执行。ping对象选择上面,则选择了ping不同层面的所有节点的方法,以达到最高的覆盖率。经过三个层次的抽象,这个每台机器需要ping的servers数量在2000-5000的级别。
- Ping Agent,Agent ping操作的实现使用了TCP/HTTP层面实现ping操作,而不是一般的ping命令的ICMP层面的。这样更方便用于区分出网络出现了那种类型的问题。在实现的时候,Agent特别注意使用很少的资源,所以Agent使用C++实现,而且不使用其它任何的库,直接使用winsock实现。
- Data Storage and Analysis,这里就是一个数据存储,分析类型的应用。
0x02 数据分析
关于不同数据中心,不同Level的延迟Paper中总结了一些数据,这个和具体的数据中心的情况相关性很大。因为就是丢包率的测量,Paper中使用的是如下的计算方式, \(\frac{ProbesWith3sRTT+ProbesWith9sRTT}{TotalSucessfulProbes}.\) 这里计算的时候只使用成功的探测的次数,而不是全部的。对于失败的,这里还无法区分具体是哪里出现了问题。公式中的3s和9s和Windows系统中TPC连接建立的超时时间时间相关。9s应该是下次的超时的时间,这里只计算了一个丢包,因为Pingmesh认为前后的两次丢包存在比较大的联系,比如第一次丢了,第二次丢的可能性很大。另外一个特别提到的问题是静默丢包,比如packet black-hole 和 silent random packet drops这样类型的静默丢包。packet black-holes也有不同类型,一种是有特定的IP源、目的地址的packet被丢弃,另外一种是特定源地址、端口的packet被丢弃。
- 这里使用了基于Pingmesh得到的数据的一种探测方法。在一个ToR交换机下面的一个server遇到了类型back hole的症状的时候,标记这个ToR为一个候选,然后赋予其一个score,这个score和出现了相关症状的服务数量相关。之后选择一个score大于一个阈值的。在一个Pod集中,如果只有一部分ToR遇到了,则认为这些出现了问题,如果是所有的都有,则可能这个问题存在更高层的交换机中。
- Pingmesh也用于帮助定位silent random packet drops的问题。如果所有的用户都遇到延迟的PCT99突然增高的情况,则一般是spine switch出现了问题,因为如果是leaf和ToR交换机出问题影响的范围要小得多。
0x03 评估
这里的具体信息可以参看[1].
007: Democratically Finding The Cause of Packet Drops
0x10 基本思路
007期望在发现数据中心内丢包的更加具体的地方,同时又要可能的实现为更小的开销。在这里Paper假设了数据中心内主要的流量都是TCP流量(到目前为止这个假设都是成立的)。 另外,分析一些数据分析,数据中心内一旦有丢包的时间方式,一般来说都不知一个tcp flow遭遇了丢包现象,
... see that the more packets are dropped in the datacenter the more flows experience drops and 95% of the time, at least 3 flows see drops when we condition on ≥ 10 total drops. We focus on the ≥ 10 case because lower values mostly capture noisy drops due to one-off packet drops by healthy links. In most cases drops are distributed across flows and no single flow sees more than 40% of the total packet drops.
基于这个数据统计的分析,如果追踪发生了数据包重传的tcp flow,获取其经过的路径。如果赋予路径上面每个link 1/h的权重,这里h为路径的长度。然后周期性地对这些权重求和,权重最高的一些link就最可能是发生了丢包的link。权重更高的也更可能发生了更多的丢包。
0x11 基本设计
007的基本设计如下图。007作为一般应用之外的组件部署,本身的组件主要是TCP Monitoring、Path Discovery和Analysis三个部分。TCP Monitoring Agent负责发现Host上面的TCP重传的行为,在监控到了TCP重传的时候,触发Path Discovery Agent的路径发现操作。这里的路径发现利用了traceroute的一些机制。在收到了这些信息之后,Analysis Agent路径vote的算法来分析最可能出现问题的Agent。
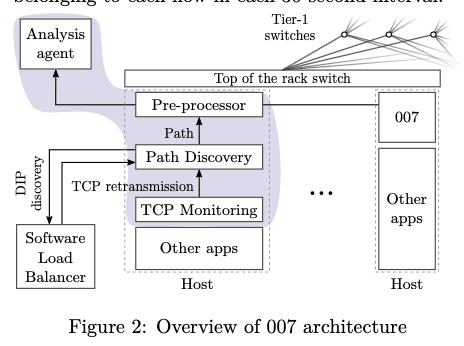
The Path Discovery Agent利用了ICMP,也就是traceroute中使用的思路。为了避免对一般的应用造成影响,这里要限制发送ICMp包的速率。这种思路在实际使用的时候要解决几个问题:
- 第一个就是要使用到真实的五元组,用来保证追踪到相同的路径。出现这里个原因是现在常用的VIP的方式,一个VIP后面可能实际上是多台的机器,会有一个LB来处理负载均衡的问题。为了处理这个问题,Path Discovery在进行路径发现的时候,要询问SLB来发现一个tcp flow的VIP-to-DIP的映射关系。这里如果在建立TCP连接的时候就识别来,则不会出发Path Discovery的操作。
- Blackhole问题,blackhole会导致某个地方的包被都其,这样traceroute自身也会失败,不过这种情况下刚刚好棒子发现了问题在哪里。另外的一个就是reouting的问题,就是路由的选择改变了,007这里认为Path Discovery在发送TCP重传之后很短的时候就会进行路径发现的操作,刚好遇上这种情况的概率很小。
在发现了路径之后,接下来就是利用这些信息来发现最可能发生问题的link。007使用的第一种算法是一个机遇vote的算法,简而言之就是工具前面vote的情况,记录一个权重。这些发生了重传的tcp flow的共同经过的地方就更加可能是出问题的地方。基本的算法如下。基本的思路就是根据前面的思路得到的权重对link进行排序,如果超过一个阈值,就认为它有问题。具体这里的分析可以参看[1]/

另外的一种方法更加复制,是一种优化算法。这个问题可以抽象为这样的一个优化问题, \(minimize\ ||\textbf{p}||_0\\ s.t.\ \textbf{Ap ≥ s}, p ∈\{0,1\}^L\) 这里A是C x L的路由举证,s是一个C x 1的向量,如果遇到了是否发生了重传的情况。L为link的数量,C为Connection的数量。
0x12 评估
这里的具体信息可以参看[2].
参考
- Pingmesh: A Large-Scale System for Data Center Network Latency Measurement and Analysis, SIGCOMM ’15.
- 007: Democratically Finding The Cause of Packet Drops, NSDI ‘18.
