Maelstrom: Mitigating Datacenter-level Disasters by Draining Interdependent Traffic Safely and Efficiently
0x00 基本概念
这篇Paper描述的Facebook用于将一个Datacenter内部的流量转移到另外的Datacenters的工具,用于解决DC级别的容灾的问题。Maelstrom很好的解决了不同类型的服务的流量迁移操作,并将相关的演练经常进行,常态化。在了解Maelstrom的基本设计之前,Paper描述了Facebook很High Level的一个架构。用户的流量经过PoP接入,在这里一个四层的Edge LB流量转发到不同的DCs中,一个DC会逻辑上面将其分为不同的Clusters。Cluster有Fronted Cluster和Service Cluster,两者前面都会有一个七层的LB。一个服务会使用到不同DCs的多个Clusters,对于一个服务,会分配一个VIP用于用户请求到对用的服务,一个VIP包含了edge weight和cluster wight属性的信息,前者用于edge LB转发到那个DC的流量的比例,而后面决定了转发到那个Cluster流量的比例。
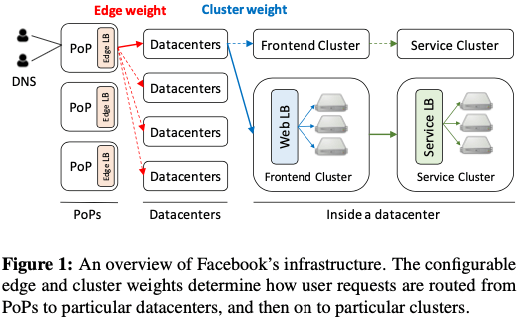
流量会分为不同的类型,Maelstrom这里总结为这样的几种,1. Stateless,很大部分的流量都是Stateless的,这种力量转移起来比较简单,改变转发的方向就可以了;2. Sticky,这种类型的流量包含了Session信息,比如Messaging类型的服务。这类型的转移起来需要重新建立Session;3. Replication,这类型的流量来自于分布式存储系统复制的流量,改变这些流量需要对系统进行重新配置。需要停止使用这个数据中心,或者是使用其它的数据中心替代。需要相关的系统有对应的处理逻辑。一般而言对相关系统要求比较高。4,Stateful,一般是主从类的系统,如果是Master在故障/模拟故障的数据中心,需要有切主的操作。另外可能需要讲一些states信息复制到新的DC。
0x01 总体设计
Maelstrom作为一个generic流量迁移到系统,它将相关的操作抽象为一个个的tasks。若干的tasks组成一个runbook,代表了迁移流量的具体的一些操作。一个runbook记录了这样的一些内容:Task specifications。具体描述这个runbooh包含的tasks。比如这样描述的一些task:
TaskTemplate Parameter Description
TrafficShift {vip type, target, ratio, ...} Shift traffic into or out of a cluster or a
datacenter (specified by target): vip type specifies the
traffic; ratio specifies the amount of traffic to shift.
ShardShift {service id, target, ratio, ...} Move persistent data shards into or out of a
cluster or a datacenter via our shard manager (target
and ratio have same semantics as in TrafficShift).
JobUpdate {operation, job ids, ...} Stop or restart jobs running in containers.
ConfigChange {path, rev id, content, ...} Revert and/or update configuration in our
distributed configuration store.
另外的Dependency Graph用于描述task之间的依赖关系。Task之间的依赖关系通过Bootstrapping关系,及一个服务依赖的底层资源,RPC请求资源以及State信息来获取;Condition有Pre-Condition和Post-Condition;Health Metrics用于监控系统目前的状态。在具体的故障解决了之后,还会有一个对用的recovery runbook来将流量服务。一个task作为一个抽象,具体的操作可以是shifting a portion of traffic, migrating data shards, restarting container jobs, 和 changing configuration等这样的一些操作。而不同的tasks之前是存储依赖关心,这样就要求不同的tasks之间存在对应的执行先后关系。每个服务会其自身的service-specific runbooks。对于Service级别的不可用,Paper中举例了一个messaging服务的例子:
Taking our interactive messaging service as an example, the runbook for draining the service’s sticky traffic (upon software failures in a datacenter) includes two tasks in order: 1) redirecting new session requests to the other datacenters, and 2) terminating established sessions in the failing datacenter to force them reconnect. A recovery runbook can be used to restore messaging traffic back to the datacenter.
如果是整个数据中心变得不可用,Maelstrom会执行一个datacenter evacuation runbook,用于迁移所有服务的流量。这样的datacenter evacuation runbook有这些服务队用的service-specific runbooks组成。而这些组成的service-specific runbooks也会有dependencies的关系要处理。执行的时候,主要涉及到的是下图中的Scheduler 和 Executor组件,而前面的UI用于展示。Scheduler用于在满足runbook的tasks执行限制条件的基础之上,比如先后关系,并行的调度执行tasks,而task应该是具体的系统来实现的。
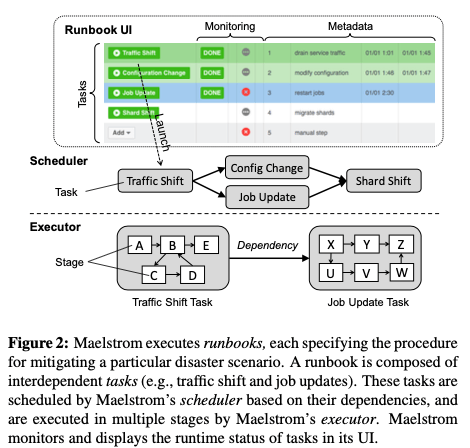
以messing服务为例,Maelstrom执行的一个流程。在Mesal本身的逻辑上限制一个task执行之外,还有外部的限制条件,比如 network over-subscription within a datacenter, cache hit rate 和 I/O saturation等。另外的service-specific 限制和具体的服务相关,比如迁移stateful traffic设计到master切换, 需要slave同步完成master的数据等。在实际进行操作的时候,需要处理资源的一些问题。将一个DC内的服务迁移到另外的DCs的时候,是否造成了资源的overload要特别注意。Maelstrom在处理的时候会进行这样的一些操作来保证:1. Verifying capacity,及迁移过来之后没有超过一个DC的资源限制;2. Prioritizing important traffic,在资源无法满足的时候,优先处理优先级高的服务;3. Graceful degradation,采用一些降级的措施。
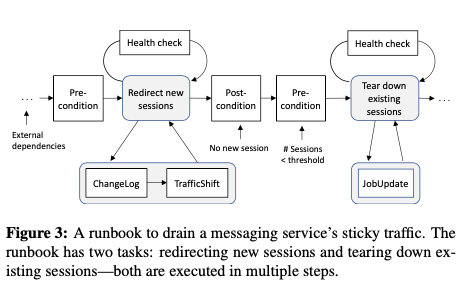
Maelstrom在决定操作的速度上面使用一种closed feedback loop的方法。这里涉及到两个核心的参数是step size 和 wait time。前者决定每次操作的流量的比较,后者决定上层操作完成之后等待多长时间在进行下一次操作。调整这两个参数就涉及到一个安全性和效率上面的平衡。Maelstrom一般的方法是从一个小的step size出发,逐步增加迁移到速度。这些参数会根据health metrics来进行调整。在Maelstrom本身的容灾机制上面,基本的思路是运行多个Maelstrom实例来实现,maelstrom的元数据则保存到一个高可用的分布式存储系统中。另外实现了一个最小化的版本,可以在任意的 engineering development server上面运行。
0x02 评估
这里可以参看[1].
Gandalf: An Intelligent, End-To-End Analytics Service for Safe Deployment in Large-Scale Cloud Infrastructure
0x10 引言
Gandalf是微软发表在NSDI ‘20上面的一篇关于部署的Paper。按照一般的经验,在Cloud Infrastructure中,大部分的故障时在部署新版本的时候导致的。原因会是多样性的,比如软件bug,人为错误等。Gandalf做为一个Analytics Service,用于分析部署之后的系统情况,快速发现定位问题。一般的线上的系统会有相应的监控作为一个watch dog,在一些指标超过了某个阈值的时候进行报警,但是这样的系统存在两个问题,一个问题是这样的监控一般是component level的,缺乏整体的信息;另外一个就是false alarm,这种监控很容易收到“噪音”的影响,这个有过相关经历的都有所了解。Gandalf的思路持续地监控多个层面的一些信息,比如service-level logs, performance counters, 和 process-level events,然后根据结合过去的部署的请求,分析出系统是否处于一个异常的状态,从而决定后面的行为,
The core decision logic of Gandalf is a novel model composed of anomaly detection, correlation analysis and impact assessment. The model first detects anomaly from raw telemetry data. It then identifies if a rollout is highly correlated to the detected failures through both temporal and spatial correlation and an ensemble ranking algorithm...
按照Paper的描述,Gandalf也是一个在微软实际的生产环境中运行了一段时间的系统。
0x11 基本设计
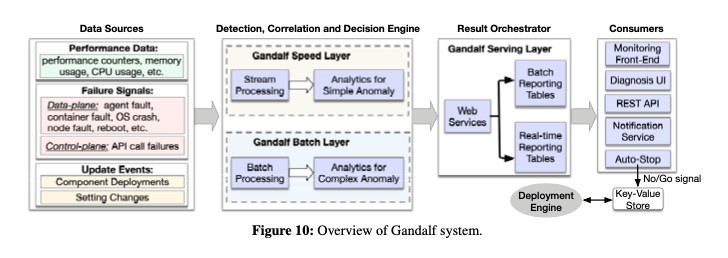
Gandalf的基本架构如下,总体的架构是一个lambda架构,分为实时处理的部分和批处理的部分。从用自顶向下的方式采集收集telemetry数据。采集的数据主要包括性能数据,比如CPU、内存的一些性能统计;另外是一个错误信息,比如 agent faults, container faults, OS crashes, node reboots 和 API call exceptions等;还有update事件信息,比如组件更新、部署的信息,设置变更的信息等。数据收集之后进入lambda架构的处境处理系统中,这里分为speed layer 和 batch layer两层。前者用于分析容易发现的问题,后者用于分析潜在的、更加深层次的问题。后面就是一些结果处理了。
- Data Source持续性地收集系统的信息,收集的数据是很多样的。比如 service logs, Windows OS events, performance counters, 和 machine/process/service-level exceptions等。在收集到原始的数据之后,会预处理一下这些数据,从中提取出关键部分的信息,比如异常信息,错误码等。这些信息会包含其它的一些熟悉,比如timestamps, node IDs 和 service types 等。对于新添加的一个服务,Gandalf对此不了解的情况下,需要向其提供哪里可以收集到这个服务部署的事件信息、已经其监控的数据。为了方便处理,这里要求这些数据是一些结构化的信息。比如对于部署事件信息,包含了Timestamp 、Location、 Pivot Group、BuildVersion 以及AdditionalInfo等,对于监控信息,包含了Timestamp、Location、 Pivot Group、Signature和AdditionalInfo这些的一些信息。
- 在数据处理上面,为了兼顾速度和覆盖完整,这里使用lambda架构分配speed layer和batch layer。前者使用了Microsoft Kusto来实现 Kusto作为一个列式的第延迟的数据处理系统。这个系统估计和微软之前发表的Trill有一定的关系。Kusto延迟低,但是在实现复杂的算法上面有一些缺点。所以下面就使用了一个Batch Layer进行不足。Batch Layer是一个类似于Hadoop的系统。在数据处理的时候都是增量进行的,每个一段时间,比如5minutes,Speed Layer从Kusto拉去最近产生的数据,而Batch Layer在小时级别的粒度上面进行处理。
- 数据上报会经过一个Web Services,也是使用微软自己的一些系统实现。数据的结构被分配两种Tables,一个Batch Reporting Tables,另外一个是Readl Time Reporting Tables。结构包括the deployment impact assessment, the recommended decisions (“go” or “no-go”), the anomaly patterns, 以及the correlation information等这样的一些信息。
0x12 Algorithm设计
数据在Gandalf中经过算法计算得出一个结构。主要分为Correlation Process和Decision Process两步。前者主要是探测异常情况,第一步就是一个Anomaly Detection处理,使用Holt-Winters forecasting算法,基本的思路是根据回去30台的数据得出一个预测值,如果超过太多就认为这个数据是异常的,Paper中设置的是4σ。由于存在多个组件并发部署的情况,这里会有一个Ensemble Voting步骤来处理。对于一个在时刻t_f发生的异常e,同一个节点上面,一个在时刻t_d部署的组件c。Gandalf会认为e会对在其去前面一个时间窗口w_b和其后面的一个时间窗口w_a有影响,时间前面的是认为和其没有关系的一种因素,而后面发生的认为是和其相关的一种因素,这里抽象为vetos和votes。对于一个时间窗口内的votes和vetos,定义为 \(P_i = \sum_k{V(e,c|WD_i)}. \\ B = \sum_k{VO(e,c|WD_{-1})}, where\ age(e,c)<WD_{−1}\ and\ WD_{−1}=72.\\ 另外定义age(e, c) = t^f - t^f.\) WD为小时粒度的时间窗口,定位WD1=1, WD2=24, WD3=72,为WD4位两次部署之间的时间,k位节点数量。在得到了P和B的数据之后,使用下面的公式计算时间上面的相关性。这个公式核心就是Pi-B和B的比值,这里又用log处理了一下,此外有考虑了一个权重。+1应该是用来处理数值为0的情况。 \(ST(e, c) = \sum_{i∈[1,4]}{w_i\log(\frac{P_i-B+1}{B+1})}, where\ P_i > B.\) 这里w_i是WD_i的一个权重值。另外一个是“空间”上面的相关性。这里使用了这样的计算方式, \(SS(e, c|t_1,t_2)=N_f / N_{df}.\) N_f表示在t1到t2出现部署了组件c又出现了事件e的节点的数量,而N_df表示出现e的总共的节点的数量。如果计算出来的值咸鱼一个阈值,则认为这个e和c的部署操作关系不大,就不考虑这个了。否则计算一个blame值$blame(e) = arg\ max_{c_j} ST(e, c_j)$。另外这里会使用一个称之为Time Decaying的思路来处理降低过去的部署的blame的值,因为一般情况下都更加注意最近的部署,也更加可能和最近的部署相关。
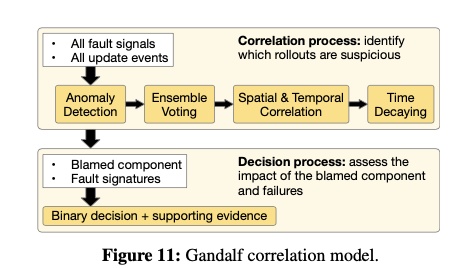
在这样的基础上面,根据前面计算出来的数据来得出一个go or no-go的结论,
Finally, we make a go/no-go decision for the component cj by evaluating the impacting scopes of the deployment such as the number of impacted clusters, the number of impacted nodes, number of customers are impacted, etc. Instead of setting static thresholds for each feature, the decision criteria are trained dynamically with a Gaussian discriminant classifier
使用这里没有和一般监控报警使用的固定的阈值,而是使用了使用分类的方法。除了上面的generic的部分之外,系统还会考虑进入特定的信息,比如对于程序的异常信息,TimeoutException和NullPointerException显然包含的意义是不同的,前者更大可能是噪声信息,而NullPointerException则很敏感,一般系统都不应该出现这个异常,出现一般以为着存在问题。所以这里可以设置一个权重值,这个值在0到100之间。这两个例子的话可以讲前者设置为0.01,而后者设置为10。这样会明显对空指针异常敏感。如果设置为0,则表示完全不关系这样的异常信息。
0x13 评估
这里的具体信息可以参看[2].
参考
- Maelstrom: Mitigating Datacenter-level Disasters by Draining Interdependent Traffic Safely and Efficiently, OSDI ‘18.
- Gandalf: An Intelligent, End-To-End Analytics Service for Safe Deployment in Large-Scale Cloud Infrastructure, NSDI ‘20.
- Millions of Tiny Databases, NSDI ‘20.
