The Snowflake Elastic Data Warehouse
0x00 引言
Snowflake是一个Data Warehouse的解决方案,基本特点是面向云,Software-as-a-Service (SaaS)的设计,采用存储计算分离的架构,支持弹性伸缩。Snowflake支持关系型数据库的一些特性,比如ANSI SQL的支持,以及还支持 ACID事务。Snowflake中保存的数据是半结构化的,本身就支持JSON、 Avro结构的数据。另外一点就是Snowflake支持end-to-end的全程数据加密,这个也是对安全性要求很高的企业服务的一种特性。部分功能特点:
- Pure Software-as-a-Service Experience,完全作为一个服务;
- Fault Resilience,高可用,高可靠。无缝在线版本升级;
- Semi-Structured and Schema-Less Data。处理长久的关系型数据中的数据,还支持ARRAY,OBJECTs,VARIANT之类的数据类型。
0x01 计算&存储
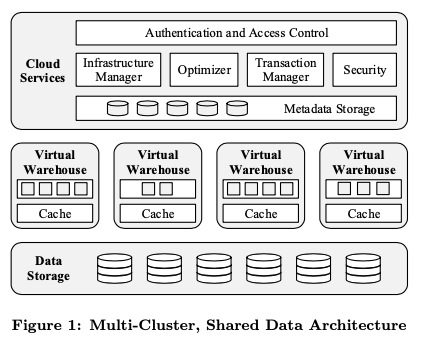
Snowflake的基本架构如下图,其主要分为三层。底层的是存储,Snowflake很特别的使用了S3存储最底层的存储方案,中间一层称之为Virtual Warehouses,为计算层,使用Amazon的EC2服务。最上层的是Cloud Services层,这里主要负责管理查询、Virtual Warehouses和处理元数据等的任务。
- 存储层Snowflake使用了S3的存储方式,其特点是应用参数、高可用性,可以实现很高的吞吐。缺点是高延迟、另外不支持append这样的操作,但是支持完整覆盖一个Object。S3在Snowflake中不仅仅用于存储持久化的数据,而且被用于存储临时数据,方便Snowflake可以支持产生非常大量中间结果的操作。S3最为一种Object Storage,其特性也影响到了Snowflake的设计:Snowflake将Table的数据拆分为一个个的partition,每个partition比较大,是不可变的。在一个partition内,Snowflake使用一种行列混合存储的、类似PAX的存储方式。每个File(在S3中应该称之为Object),会有一个header,记录不同的Column在在这个Object中的Offset,这样获取一个Column数据的时候,就可以根据这个Header的信息,利用S3提供的Get Range的操作只Get这一部分的数据,而不用Get全部的数据。元数据,比如一个table有哪些 S3 files组成, 统计数据, locks, transaction logs,被保存一个支持事务的分布式key-value store中,这个组件属于Cloud Services部分;
-
VWs最为计算层,实际上就是一些EC2的实例。使用EC2好处就是其可以被按需求创建,拓展和销毁等。在没有查询的时候,可以完全将VMs的机器关闭,这样就可以节省成本。一个查询操作只会运行在一个VW中,这样就可以获得很好的隔离性。Paper中这里提到,目前一个Worker Node不会在多个VMs中共享,但是会是未来工作的一部分。共享可以获取到更好的资源利用率。一个查询在被分配到一个VM中的时候,其工作会被拆分为多个部分,由VM中不同的Worker Node执行。失败的查询会通过重试来解决。一个查询只会早一个VM中执行,但是一个用户可以的任务可以在多个VMs中支持。
-
因为使用S3存储会带来更高的延迟,Snowflake在计算层使用了一层缓存。缓存数据被保存到本地的磁盘上面,根据Column使用不同的文件保存。并使用LRU算法管理缓存淘汰。多个Worker Node可能带来缓存多份的问题,Snowflake通过将在一个files上面的work根据一致性hash的方式分发到worker nodes上面。同一个文件上面的操作会一般在同一个node上面运行,提高缓存命中率。Snowflake这里的一致性hash使用一种lazy的模式,即在节点数据增加 or 减少的时候,不会立即导致data shuffle,
This solution amortizes the cost of replacing cache contents over multiple queries, resulting in much better availability than an eager cache or a pure shared-nothing system which would need to immediately shuffle large amounts of table data across nodes.一个例子如下。在增加了一台机器之后,T6应该被重新调度到节点6上面。但是Snowflake不会立即这么做。而是等待需要任务窃取的时候 or 重新运行的时候。
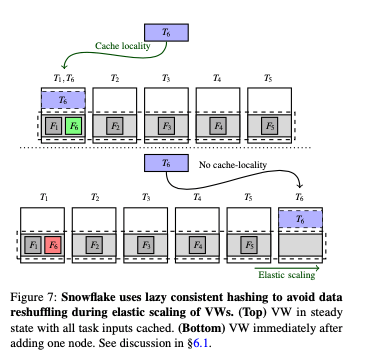
- 另外的一个问题是倾斜数据的处理。这里Snowflake采用了一种类似任务调度中常用的任务窃取的思路,在一个worker node完成其工作的时候,会询问其他的节点处理情况,如果存储没有处理完成的文件,会“窃取”一部分过来处理。
作为一个分析类似的应用,Snowflake的执行引擎使用列式风格的方式,数据被按列处理。为了利用好现在CPU的计算能力,使用Vectorized处理数据,利用SIMD的计算能力。另外使用Push-based的执行方式,因为Push-based可以提高缓存命中率。这里在Paper中没有具体说明,可以参考相关的Papers。
0x02 Cloud Services
在Snowflake中,Virtual Warehouses作为一种ephemeral的资源,根据用户需要确定。而Cloud Services作为一个整体存储,而且,是一个多租户的系统。包括access control, query optimizer,和transaction manager等在内的功能是需要长久存在的。Snowflake中的请求处理,用户的请求会被想发送到这里,进行前面几步的操作: parsing, object resolution, access control, 以及 plan optimization几步。Snowflake的查询优化器使用Cascades风格,由于Snowflake没有使用索引,相关的查询优化会简单一些。在优化器执行完成之后,相关的执行计划会被分发到各个Worker Nodes。Cloud Services会在查询进行的过程中监控运行的情况,统计会收集统计信息。
-
Snowflake作为分析型的数据仓库,其数据更新一般都是一次大批量地添加 or 更新,不适合频繁更新的情况。不过Snowflake同样支持ACID 事务,并支持SI的隔离级别。和一般的SI的隔离级别实现一样,Snowflake并发控制也是基于MVCCC的方式,
It follows that write operations (insert, update, delete, merge) on a table produce a newer version of the table by adding and removing whole files relative to the prior table version. File additions and removals are tracked in the metadata (in the global key-value store), in a form which allows the set of files that belong to a specific table version to be computed very efficiently. -
Snowflake没有使用索引,认为使用索引不适合Snowflake面向的workload。为了减少查询的时候访问的数据,而使用min-max based pruning的方式。基本思路是对于一些数据,记录其数据分布的一些信息。比如最大值,最小值。这样在查询一个区间内的数据的时候,就可以根据这个信息避免访问一些不会包含在所选访问内的数据了。
Building An Elastic Query Engine on Disaggregated Storage
0x10 基本思路
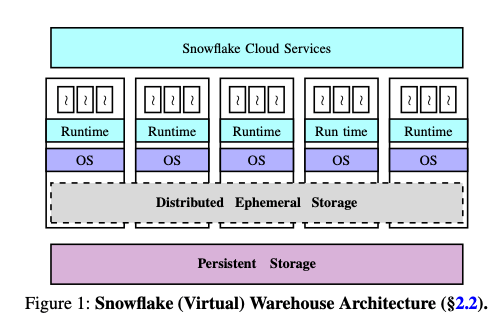
这篇Paper是Snowflake架构的继续优化,几种在Disaggregated Storage的设计上面。得益于网络速度的提高,Disaggregation的设计在最近的一段时间被研究了不少,比如OSDI ‘18的一篇best paper。Disaggregation主要可以在这样的几个方面带来优化:一个是解决硬件资源不匹配的问题,不同的应用对不同资源的要求差别很大。使用类似的机器配置会导致有些浪费了CPU、有些浪费了内存 or 磁盘之类的资源。另外一个就是缺少了灵活性,在一个类型的资源不足的时候,添加机器资源会导致还需要添加其它没有发生不足情况的资源。体现在Snowflake这里的时候,就是之前存储计算分离的时候,计算节点上面使用了基于磁盘的Local Cache,这里选择将Local Cache优化为一个全局的Ephemeral Storage来处理。如此优化之后的Snowflake的架构如下图,
0x11 基本设计
在Sowflake中,数据只要分为这样的一些类似:持久化的数据,这个就是Data Warehouse本身的数据,另外一个就是在运行过程中产生的临时的数据,即Intermediate Data,还有就是Metadata。Paper中先总结了Snowflake中请求的一些特点:只读操作占28%,不同查询涉及到的数据量差别非常大,而且经常出现spike;只写操作占13%,写操作占59%,同样不同操作涉及到的数据量差别非常大。这样不同的操作带来的中间数据量也是差别也是非常大的。这样对于全局的Distributed Ephemeral Storage设计上,使用in memory + SSD的设计,另外一个允许intermediate数据spill到S3上面,避免造成Distributed Ephemeral Storage容量不够用造成影响到正常运行的情况。
-
系统中出现设计到数据非常多查询的时候,会造成Intermediate Data数据也达到一个很高的峰值,但是平均不会很多。另外就是数据访问倾斜性很高。这个数据缓存带来了有利的空间。Ephemeral Storage保存数据设计到两种,一个是Intermediate Data,另外一个就是原始数据。Ephemeral Storage总是优先保存Intermediate Date。数据保存、访问通过一致性Hash的方式路由到一台机器上面,Ephemeral Storage节点通过LRU策略来决定缓存、驱逐缓存的数据(优先保存Intermediate Data)。虽然使用的Ephemeral Storage容量不大,但是实际上效果很不错,
Even though our ephemeral storage capacity is significantly lower than that of a customer’s persistent data (around 0.1% on an average), skewed file access distributions and temporal file access patterns common in data warehouses enable reasonably high cache hit rates (avg. hit rate is close to 80% for read-only queries and around 60% for read-write queries). -
虽然这里Snowflake使用的是Intermediate Data优先于缓存Persistent数据。但是也认为这个不一定就是最佳的策略,未来可可能将这种策略优化为分为两个部分。Snowflake这样实际上使用了三层的存储方式,compute-local memory, ephemeral storage system 和 remote persistent data store。Snowflake使用LRU决定将本地内存中的数据淘汰到本地SSD,另外一个就是有使用一个LRU将本地SSD的数据淘汰到Ephemeral Storage。目前的缓存淘汰策略在这样多层的存储模型下面可能并不是一个很好的方法。未来需要改进。
在调度任务的时候,Snowflake的调度器会考虑到缓存数据所在的位置,称之为Locality-aware task scheduling。也同样有提了一下前面讲到的work stealing策略。Paper中也提到了未来Snowflake的一些改进思路,比如优化调度器,同时考虑到读取Persistent Data和读取Intermediate Data带来的开销;2. 优化现在的机遇VM的隔离方式,因为目前的方式隔离效果不错但是资源利用率还有不少的优化空间;3. 另外一个就是资源共享上面的优化,比如通过Memory Disaggregation的思路提高内存利用率(目前统计的资源利用率分别是 Average CPU, Memory, Network TX and Network RX utilizations are roughly 51%, 19%, 11%, 32%)。
0x12 评估
这里具体的内容可以参考[2].
参考
- The Snowflake Elastic Data Warehouse, SIGMOD ‘16.
- Building An Elastic Query Engine on Disaggregated Storage, NSDI ‘20.
