Inverted Files for Text Search Engines
0x00 引言
这篇Paper是一篇总结性的文章,发表在06年,是一篇关于Inverted Index的一篇很好的文章。Inverted Index涉及到很多的数据结构和算法的设计,这里主要讨论的是Inverted File的设计。Inverted Index简单地说就是为文档建立索引,是Text Search Engine的一项基本的技术。Paper中先介绍了搜索中要考虑的一个重要因素,就是如何判定一个doc为用户想要搜索的doc。这里设计到以下的概念/统计数据,
— f_{d,t}, the frequency of term t in document d;
— f_{q,t}, the frequency of term t in the query;
— f_{t}, the number of documents containing one or more occurrences of term t;
— F_{t}, the number of occurrences of term t in the collection;
— N, the number of documents in the collection; and
— n, the number of indexed terms in the collection.
在结构排序的时候,会考虑到以下的一些思路:1. 在比较多doc中出现的terms获得计算出更小的weight,2. 在一个doc里面出现更多次的terms会计算出更高的权重,3. 出现更多terms的doc会得到更小的权重。一个根据前面的数据计算weight的方式如下,这种方式是利用查询向量 query vector w_{q,t}以及doc vector w_{d, t}的n维的余弦, \(w_{q,t}= \ln(1+\frac{N}{f_t}), w_{d,t}=1+\ln f_{d,t}\\ W_d=\sqrt{\sum_t{w_{d,t}^2}},W_q=\sqrt\sum_t{w_{q,t}^2},\\ S_{q,d}=\frac{\sum_t{w_{d,t}\cdot w_{q,t}}}{W_d\cdot W_q}. \\\) Paper中还提到了一些其它的计算方式,具体的信息可以参看[1]。总地来水,这些计算方式都依赖于前面提到数据。根据统计数据来对文档进行排序,进而得到与查询最匹配的doc。为了高效地根据这些信息对doc进行排序操作,获取查询的结果,Inverted Index由此而生,这里讨论了是Inverted Files,是Invented Index的主要结构,主要包含以下的概念,
The most efficient index structure for text query evaluation is the inverted file: a collection of lists,
one per term, recording the identifiers of the documents containing that term.
即一些list,记录了每个doc包含的term的统计。一个结构对于对于每个word t(这个结构称之为search structure or vocabulary stores)保存了:1. 一个f_{t}统计,记录那些文档包含了这个t,即一个计数值,2. 一个pointer,记录了在到对应的inverted list的起始位置。另外的结构就是一组的invented lists,这个结构中,对于每个word t,保存了包含了这个t的doc的id的list,2. 在一个doc d中的f_{d,t}统计信息。一个结构的示意如下:

0x01 基本思路
这篇Paper主要的内容就是如何组织结构。在前面提到的基本结构设计中,在查询单个word的情况下,处理起来的逻辑是比较简单的。Paper的提到了几种基本的思路,如下所示。比如有将包含词组单词的文档取出来,然后在进行二次去除的处理,这里这么处理是可以利用单词处理的逻辑,有因为查询词组的单词在物理位置上面处在一些,这样就需要消除一些不符合这个条件的结构。另外的就是添加一些位置信息,来辅助对包含词组单词的文档进行过滤操作。还有的策略就是使用某种词组索引来处理。
Three main strategies for Boolean phrase query evaluation have been developed.
— Process phrase queries as Boolean bags-of-words so that the terms can occur anywhere in matching document, then postprocess the retrieved documents to eliminate false matches.
— Add word positions to some or all of the index entries so that the locations of terms in documents can be checked during query evaluation.
— Use some form of partial phrase index or word-pair index so that phrase appearances can be directly identified.
这三种策略有有各自的优缺点。比如第一种策略的优点是比较简单,但是在实际上比较容易造成很低的效率。使用词组索引则词组可能出现的组合太多了。Paper中接下来讨论的是index如何构建,这里Paper总结了这样的几种方式:
-
In-Memory Inversion,直接在内存中构建。这里要先预处理一次,然后对于每个单独的doc拉进行相应的处理。这种方式的优点是内存利用率比较高,但是要处理的index大小超过内存大小的时候比较麻烦,这里可以有其它的一些处理这个问题的方法。

-
另外的一种策略是称之为Sort-Based Inversion。前面的这种两阶段的另外一个缺点是dock的parsing和fetching操作会带来很大的开销。开始的时候,数据以⟨t,d, f_{d,t}⟩的方式表示,以doc id进行排序,然后排序为以term order的数据。这种方式还是在上面的策略中的优化,主要是优化第二次处理doc时候带来的开销,
-
Merged-Based Inversion,实际上index构建的时候要求在内存不满足要求的时候也能够处理。而Merged-Based Inversion的方式则优化了前面在内存不足的时候的缺点。基本的处理流程如下。处理的时候,每次都是处理一个部分。在处理这个部分占用的内存达到一个限制的时候,将其flush到磁盘。然后处理后面的数据,数据都处理完成之后,将部分index合并成为一个完成的index。

index的另外一个问题是如何更新。doc添加的时候,由于index会被改动比较多,造成很低的性能,一般都会避免添加一个doc就改写index。Paper中也总结了几种的策略:1. Rebuild,这种方式是周期性得重建index;2. Intermittent Merge,周期性的新旧数据合并操作;3. Incremental Update,增量式更新,即在机会合适的时候进行更新操作,比如在访问到相关数据的时候顺便进行更新操作。
The per-list updates should be deferred for as long as possible to minimize the number of times each list is accessed. The simplest approach is to process as for the merging strategy and, when a memory limit is reached, then proceed through the whole index, amending each list in turn. ...
另外的一个方面的设计是关于如何实现分布式的search engine。这里提到了两种思路:1. Document-Distributed Architectures,这种思路是将doc划分,每个节点上面处理自己部分的doc。这种方式的优点是逻辑简单,可以直接在单机上面的逻辑上面实现,缺点是查询的时候需要发送到所有的机器,然后进行结合合并,这里带来的开销很大。2. 另外的一种策略称之为Term-Distributed Architectures,Index根据term来进行划分,这种方式优化了第一种方法的缺点,带来的问题是coordinating machine容易成为一个瓶颈。除了这些内容,Paper中还总结了压缩的策略,优化内存使用的一些策略等。另外的提高查询效率的几个思路比较有意思,总结如下:
-
Skipping,这个思路是避免不必要的数据fetching来提高性能,需要在inverted list添加一些其它的结构。通过将inverted list拆分为多个chunk,同时添加其它的数据信息,来获取一个chunk中的数据时候需要fetching来进行进一步处理来skip一些操作。
-
Frequency-Ordered Inverted Lists,即根据f_{d,t}来进行排序,比如,
将原始数据 ⟨12,2⟩ ⟨17,2⟩ ⟨29,1⟩ ⟨32,1⟩ ⟨40,6⟩ ⟨78,1⟩ ⟨101,3⟩ ⟨106,1⟩ 排序为 ⟨40,6⟩ ⟨101,3⟩ ⟨12,2⟩ ⟨17,2⟩ ⟨29,1⟩ ⟨32,1⟩ ⟨78,1⟩ ⟨106,1⟩, or优化成其它的表达方式,比如 ⟨6:1:40⟩ ⟨3:1:101⟩ ⟨2:2:12,17⟩ ⟨1:4:29,32,78,106⟩,这里还可以添加一些压缩方式,比如第一个id后面的id记录为差值: ⟨6:1:40⟩ ⟨3:1:101⟩ ⟨2:2:12,5⟩ ⟨1:4:29,3,46,28⟩.处理的时候处理w_{q,t} × w_{d,t} ≥ S的部分。
-
Impact-Ordered Inverted Lists,frequency-sorted approach的一个问题就是不是w_{q,t} × w_{d,t} ≥ S对应到最后的结果,而是w_{q,t} × w_{d,t} / W_d≥ S,
If it makes sense to frequency-sort the inverted lists into decreasing w_d,t order, then it makes even better sense to order them in decreasing impact order using w_d,t/W_d as a sort key. Then all that remains is to multiply each stored value by wq,t and add it to the corresponding accumulator. That is, an impact value incorporates the division by Wd into the index.
Paper中还有更多的内容……
Read as Needed: Building WiSER, a Flash-Optimized Search Engine
0x10 基本思路
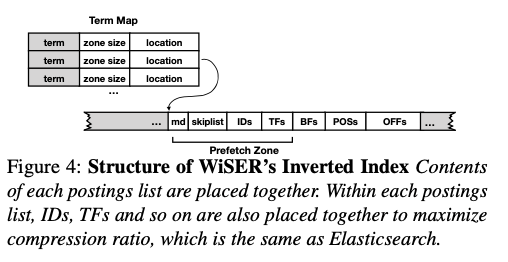
这篇Paper是将在SSD上面的Search Engine的优化,也就是前面提到的Inverted Index在SSD上面实现的时候的一些优化。这篇Paper根据SSD提供的高的读取带宽,提出了Read as Needed的优化观点,以便于充分利用现在硬件的性能。Inverted Index的基本结构一般如前面总结的那样,Paper中的主要对比对象是Elasticsearch,可以看作是一种Inverted Index的实现。其Inverted Index的基本结构如下。在Elasticseathc中一个基本的查询操作如下:
First, Elasticsearch locates a postings list by Term In dex (1) and a Term Dictionary (2), The Term Index and Term Dictionary contain location information of the skip lists, document IDs, positions, and offsets (details below).
Second, the engine will load the skip list, which contains more information for navigating document IDs, term frequencies, positions, and offsets.
Third, it will iterate through the document IDs and use the corresponding term frequencies to rank documents.
Fourth, after finding the documents with top scores, it will read offsets and document text to generate snippets.

Paper中认为Elastcisearch这样的将数据分为几个stage的设计,并将前面的stages的大小尽量缩小,方便Cache在内存中来提高性能。但是这样的设计可能导致的一个问题是读取放大。Paper中给出的数据是这样的设计性能比较依赖于内存到大小,而WiSER的设计是将内存看作是一个Buffer,而不是一个Cache,在内存不足的时候也能提供比较好的性能。WiSER的总体设计如下,在结构上面和Elasticseathc的区别是将不同几个stage拆分为更小的部分,相关的部分组织到一起,这里可以看是是原来的设计安装term分区的一种设计,同时在保存的数据位置上面进行一些改进。Paper中总结的WiSER的几个优化点如下:
-
Cross-Stage Data Grouping,这里的优化就体现在了WiSER结构的设计上面。和Elasticsearch每个部分单独保存不同,这里是将相关的数据分组保存,这些组包含了不同部分的数据,所以称之为Cross-Stage Data Grouping。在实际的数据中,postings lists都是比较小的,大部分的term数据都可以放进一个block中。将相关的数据就可以在一次的读取中都将其读取出来,降低了读取放大,
Due to highly efficient compression, the space consumed by each postings list is often small; however, due to Elasticsearch’s layout, the data required to serve a query is spread across multiple distant locations (Term Dictionary, ID-TF, POS, and OFF) -
Two-way Cost-aware Filters,在下图中结构中,POSs前面的结构是BFs,即Bloom Filter。用于词组查找的时候先确认这些的词组在doc中存在与否。在存在的情况下在进行后面的操作,是一种查找的优化措施。这个优化措施满足一个统计是 测试的negative tests比较高,这样才能直接避免后面的草在,另外的一个是读取BFs本身带来的开销要低。但是这两点是相互矛盾的。WiSER这里的优化措施是估计读取BF带来的开销,只有在划得来的情况下才去读BFs,
We estimate the relative I/O costs of Bloom filter and positions among different terms by term frequencies (available before positions are needed), which is proportional to the sizes of Bloom filters and positions.另外的一个优化是设计一种two-way的BF结构。即不仅仅处理一个term后面的term,还有一个处理前面的term。有些时候从后面一个term过滤前面一个会比用前面一个term过滤后面一个有更好的性能表现,主要的情况是一个tern的BD和POS数据更小的时候,使用这个term取过滤更加合适,因为需要读取更少的数据。这里在实现上的另外的一些优化措施:比如将BF分组,使用标记表示节约没有mask的BF的chunk部分,从而节省空间,
。。。 each of which contains a fixed number of filters (e.g., 128); the groups are indexed by a skip list to allow skipping reading large chunks of filters. In each group, we use a bitmap to mark the empty filters and only store non-empty filters in the array; thus, empty Bloom filters only take one bit of space (in the bitmap). -
Adaptive Prefetching,这里的优化涉及到Linux IO操作的一些行为。读取文件数据的时候,Linux会自动地进行一些预取数据的操作,但是这个不一定符合WiSER的访问特点,会导致一些无用的预取操作,从而造成读取放大。这里的基本思路是使用自己的预取策略,避免使用Linux默认的策略。如下图的结构图,WiSER将数据分为一些Prefetch Zone。通过madvise的MADV_SEQUENTIAL来手动处理。
-
Trade Disk Space for I/O,这里主要就是压缩策略上面的优化。通过将压缩的Block减小,虽然在压缩效率上面更差一些。但是会避免一些无用的读取,减少无用的解压缩操作。
0x11 评估
这里的具体信息可以参看[2].
参考
- Inverted Files for Text Search Engines, ACM Computing Surveys 2006.
- Read as Needed: Building WiSER, a Flash-Optimized Search Engine, FAST ‘20.
