SQL Server Column Store Indexes
0x00 基本设计
前面看了SQL Sever中指出OLAP功能的一些设计,这篇Paper就描述了其Column Store Indexes的设计,在看前面的两篇的时候最好看看这篇。在SQL Server中,primary index支持 heaps index(unordered) and B-trees index(ordered),但是secondary index支持btree index,不支持heaps的,当然还有另外的一些类型的index。这里的column index是添加了另外的一种index模式。在column index的物理存储设计上面如下:全局的数据会被分为row group,每个row group的数据量在、million左右,然后每个group中,不同的列会被分别压缩保存,称之为segment。segment使用SQL Server的 separate blob (LOB)来保存。
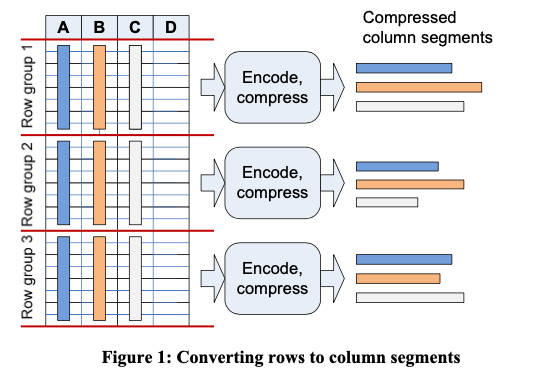
在这些segments之上,会有一个segment directory,记录了每个semgent的一些原数据,比如number of rows, size, how data is encoded, 和 min and max values等的信息。这样的保存方式之上,如何压缩数据是一个比较重要的内容,
- Encoding,这里关于如何将书表示为32bit or 64bit的整数表示,使用两种方式: a dictionary based encoding 和 a value based encoding。其中第一种适合一列的取值不同的值比较有限的情况,用一个整数作为key,实际的值作为value,形成一个dictionary。这个dict单独保存到一个地方,这种方式适合各种类型的数据。value based encoding适合应用到整数 or decimal类型的数据,这里就是一些integer or decimal的一些编码方式,会比一般的编码方式占用更少的空间。
- 另外的是使用一些另外的压缩方式,比如run-length encoding (RLE)。在一个row group之类,其顺序是不重要的,所以在一列的一个segment内,将数据重新安排,rearrangement。Paper中这里只是说rearrangement,但是没有说是排序。
在数据编码、压缩的一些优化之外,在查询处理上面这里也有一些其它的优化,这里没有选择实现了一个新的查询引擎,Paper中总结了选择在原来的基础之外优化而不是写一个全新的查询引擎的优点。在优化器这里Paper中主要提到的是求batch处理的一些优化,这里加入了一个batch segment 概念,
A batch segment consists of a sequence of batch operators that execute using the same set of threads. An operator can only extend the segment to a single child. In our implementation a join always extends its segment to the probe side.
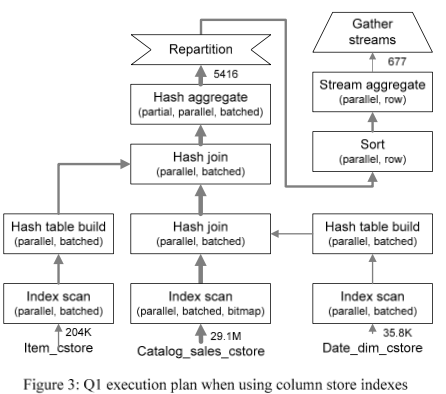
以join操作为例,这里还加入了一个BatchHashTableBuild,比如下面的执行graph,这里使用的join方式称之为batch hash join,hash join不在自己构建hash table,而是通过加入的BatchHashTableBuild算子来构建。BatchHashTableBuild算法除了构建hash table之外,还支持在hash key上面构建一个bitmap (Bloom filter),一个下推的操作,用于早期过滤掉不符合条件的数据。Paper中描述的另外的关于多table join的操作的优化的一种算法描述地比较抽象[2].
0x01 评估
这里的具体内容可以查看[1].
DB2 with BLU Acceleration: So Much More than Just a Column Store
0x10 压缩和结构
和前面的SQL Server的列存的拓展哟样,DB2这里也有一个BLU的功能,在DB2原有的一些组件之上实现了列存功能的一个拓展,行存和列存的表可以同时存在一个数据库中。对于列存来说,数据压缩是一个很重要的一个部分。一般数据按列保存的一个重要原因就是可以实现更好的压缩效果。BLU也使用dictionary的压缩方式,paper中举了一个压缩CountryCode的例子,使用一个16bit的整数表示,其中:1. 最常见的两个使用1bit来表示,0 and 1;2. 接下来的剩余的8ge使用3bit表示;3. 剩下的使用offset-coded partition使用一个8bit的方式表示。这种方式在一些情况下可以实现非常好的压缩效果。这种方式讲数据分为了3个分区,BLU实现压缩算法的使用了这样partition的思路,一般根据数据添加的时候数据信息的统计来进行分区。对于一个dictionary的分区,数据可以选择不同的数据保存方式:1. 保存完整的数据;2. 有一个相同的prefix;3. base value加上offset coding的方式。DB2在此的基础之上使用的数据保存方式,
- BLU中的表被分为column group。数据保存的时候对于可以为null的列,BLU内部实现的时候会使用两列来保存,一列保存数据,另外一列保存一个是否为null的一个标记。Column group的数据被保存在固定大小的pages中,这里和SQL Server的有写不同。另外一个更大的数据单元称之为extent,在存储上面是连续的,有固定数量的pages组成。Extent为一个空间分配的单元。每个extent只会保存一个column group的数据,一个column group中的一行数据的部分称之为tuplet。Tuplet在不同的column group使用相同的顺序保存,使用一个虚拟的TSN,Tuple Sequence Number,来标示。一个Page里面保存了一个TSN的区间,使用(StartTSN, TupletCount)的方式来标示。另外使用一个B+tree来记录Page和StartTSN之间的对应关系。
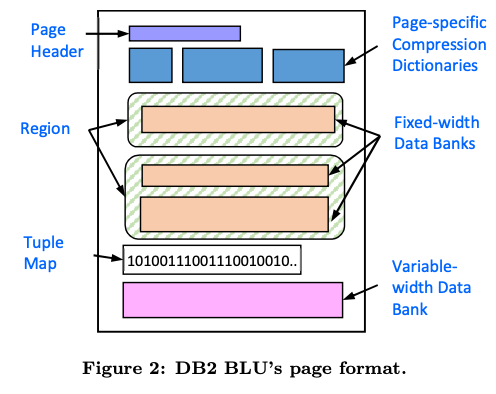
- Page的基本结构如下图。Page中一个主要的区域是中奖的Region,其中保存的tuplet的格式是相同的。一个Region是在一个Page之内的,由tuplet所属的cell来划分的一个partition。这里的Cell是另外的一个概念,对于单个列的column group,cell就是一个dictionary的partition,对于多个列的情况,paper中描述的是,与dictionary的cross product,叉积相关。比如在一个Page内,前面提到的CountryCode有第一个partition和第二个内的数据,那么这里就会有两个的region,因为partition不同起保存的格式有不同。一个Page内的Region超过来一个的话,会有一个tuple map来记录每个tuple属于哪一个region。TupleMap为一个Key为page-relative TSN (the row’s TSN - StartTSN for that page),value为region的索引这样的结构。在一个region内不分为固定宽度的banks。这里不同列的数据可能保存在不同的banks中,即使是同一列的数据部分的列和表示是否为null的列也可能在不同的bank。bank有一定的width,比如128-bit or 256-bit。比如对于128bit的情况,对于前面的CountryCode的3bit编码的情况,可以保存42条记录。一个Page内可能会保存一些没有压缩的数据,固定宽度的数据类型可以同样保存在banks中,而对于变长度的,数据保存在另外的一个区域,而记录这个数据位置的 (offset, length) 保存在banks中。有这里的结构可以看出,BLU的压缩主要是从dictionary的压缩方式上设计。
- 处理这些之外还有一些针对特殊情况的优化方式,比如一个partition内出现的不同的值比较少的话,可以为这个page单独设计一个编码,相关的信息保存到page-specific compression dictionaries中。
0x11 查询处理 & 数据更新
BLU的查询处理利用了DB2已经存在的很多技术,包括各种的查询优化等。同样地,和前面的SQL Server一样,这里处理列存数据的时候也不使用一次处理一条记录的方式,而是一次处理一个batch,这里称之为stride。这样处理可以减少一些函数调用的开销,降低cache miss rate,还可能利用一些loop unrolling等等优化措施。DB2一个操作的动作称之为evaluator,Paper中提到的和列存相关性比较大的evaluator:LeafPredicateEvaluator,LoadColumnEvaluator,为主要的两种访问列存数据的方式[3]。在这些操作的基础之上,Paper中还描述了Hash Join、Grouping和Aggregation的一些实现,其特定是这里的实现都是并发的,而且有不少的细节上面的优化和事得其robust的处理。这些操作的一个特点是有些操作直接就在编码之后的数据上面进行处理。列存的一个问题就是如何处理数据更新的问题,在前面的SQL Sevrer的paper中就话了比较多的篇幅来描述如何处理这些问题。BLU的Paper这里也是描述了数据更新在这里的实现。这里和前面的SQL Sever的实现有些差别。添加操作要求获取每一列所在的page,以及需要讲这些改动记录到日志中,带来不少的开销。
- 为了平摊insert操作的开销,这里使用的是buffering的方式,BLU中在buffer pool之外,一些非full状态的page用于buffer添加的数据,添加操作操作的是这些buffer page而不是原来的对应的page。一个buffer写满的时候,会被flush到磁盘,相关的记录就会被记录下来,类似于写了日志,相关的更新会被copies back到buffer pool中的page中。insert buffer中的page和buffer pool中的page格式是一样的,方便直接处理这里page上面的查询操作,这里的数据是没有committed的,所以查找查找只会对自己的transaction可见。另外使用分区的方式来减小锁的粒度也是一种常用的方法。
- 对于更新、删除操作,table会有一个2bit的内部TupleState列,用于记录一行数据目前的状态。一行数据被添加之后会处于Inserted状态,删除操作使其状态变为PendingDelete,实际的数据删除会被后面的后台操作执行。而更新操作为一个删除操作和添加操作的组合。为了处理更新操作的一些问题,这里会维护另外的一个内部的列,称之为PrevRowTSN,类似一个前向指针。
0x12 评估
这里的具体内容可以参看[3].
参考
- SQL Server Column Store Indexes, SIGMOD ‘10.
- Spatial Indexing in Microsoft SQL Server 2008, VLDB ‘08.
- DB2 with BLU Acceleration: So Much More than Just a Column Store, VLDB ‘13.
