Real-Time Analytical Processing with SQL Server
0x00 基本架构
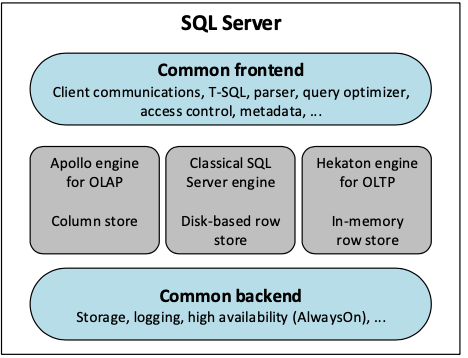
这篇Paper是关于SQL Server的OLAP拓展。下面的SQL Server的基本架构图上面,近些年在原来的传统的Disk Based ROW Store的基础之上,有发展了内存存储引擎和Column Store。这里主要是关于OLAP的部分,即Column Store部分,这里功能的实现也会利用Hekaton提供的一部分功能。SQL Server这里将列存的索引称之为,columnstore index (CSI) 。CSI的存储利用了SQL Server blobs (LOB)的功能,这里的数据会被按列拆分分别存储,然后将这些数据拆分为segment,每个segment有million左右行的数据,一个segment作为一个压缩的整体保存,一个directory结构会保存segment的位置信息以及用于压缩的相关数据,频繁使用的数据会被cache在内存中,
... A directory keeps track of the location of segments and dictionaries so all segments comprising a column and any associated dictionaries can be easily found. The directory contains additional metadata about each segment such as number of rows, size, how data is encoded, and min and max values.
Column Store这些的存储方式一般都比较难处理数据更新的问题,Paper中讲到的SQL Server还支持Primary CSI的更新,不支持Secondary CSI的更新,现在的SQL Server版本是已经支持了的。为了支持更新,这里引入了delete bitmaps 和 delta stores。一个delete bitmap用于标记一个index那些row的数据已经被删除。delete bitmap结构在内存和disk上面使用不同结构表示,适应不同存储介质的不同特点。delta store则用于处理数据的添加和更新的问题,这里实际上就是B+ tree的结构,暂时保存没有合并到主存储的数据,这个delta store可能有0个or多个。在执行引擎上面,SQL Svever使用的是Cascades风格的优化器,为TP类型的workload设计,一般每次就是处理一行的数据,在AP类型的workload下面,这种方式不是很适用,这里的优化方式是使用每次处理一个batch,batch的大小在K级别左右,
... most query operators are supported in batch mode: scan, filter, project, hash join (inner, outer, semi- and anti-semi joins), hash aggregation, and union. The scan operator scans the required set of columns from a segment and outputs batches of rows. Certain filter predicates and bitmap (Bloom) filters are pushed down into scan operators.
0x01 In-Memory and Updating Secondary
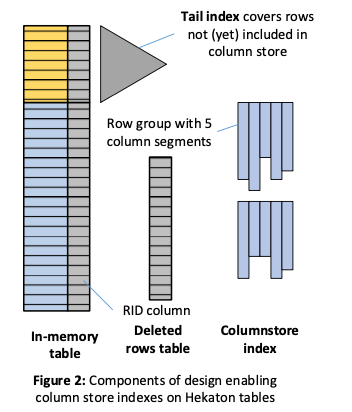
SQL Server 2016支持使用使用Hekaton engine来提供处理的性能。内存中的table会包含所有的数据,但是CSI中则不能保证,有一部分只会在内存中的table中,这里在下图中用黄色的表示,新添加 or 更新的数据会添加到内存中的table中,但是不会马上添加到CSI中。这些数据会有一个tail index。这个table会有隐藏的RID一列,来表示在column store的位置信息。一个Deleted Rows Table记录被删除rows的RID信息。内存中的table即Hekaton table。这个RID会包含row group ID的信息,从而由此得到segment的信息,称之为row group,即前面提到的一个压缩的整体。对于还在tail index中的数据,RID的值回事一个特殊的无效值。同样地,这个值也可以用来表示memory table中的row还是在tail index中,对于删除RID为无效值的row,直接从memory table中删除即可,而有效的时候还要将这个RID记录到delete rows table中。这些delta数据和deleted rows table在合适的时候需要merge到base数据中,这里使用了后台的data migration task,这个任务的处理分为两个stages,
-
Stage 1 (everything occurs in a single Hekaton transaction):。在一部分会扫描内存table,选择合适的在tail index中的rows。这里不会选择所有的在tail index中的数据,而是会在一个统计,这个统计是关于这些数据的最近的更新频率,如果认为比较高的话就会不会早改变,而在被认为比较“冷”的时候才会进行下面的操作。相关的数据会被组织为先的row group,并被赋予RID,这一部分的数据这些RID会被添加到deleted rows table中。所有commit的时候,tail index中的一些数据已经添加到CSI中,但是看起来系统还是没有什么变化。这里在添加RID在deleted rows table的时候,一个优化是选择添加range RIDs的方式避免一次性添加大量的数据到这个table中。
-
Stage 2: This stage uses a sequence of short transactions。这部分操作的时候,每个事物会将一个RID从deleted rows table中删除,然后更新memory table中对应row的RID。这样这些数据就可以通过CSI来访问来。设计这样的数据迁移的方式主要是为了处理不会在CSI和memory table的tail index的数据看到重复的数据,满足正确的snapshot语义。在实现的时候,Paper中提到了stage2的一些优化:前面提到的stage2的算法可能会导致很大的logging的开销,这里的优化是logging只会设计到RID的相信,而value部分则从已经生成的row groups中恢复。另外的一个可能的问题是这个的事物和用户的事物形成冲突,这里的一个优化是使用batch的方式,另外一个优化是冲突的时候不abort用户的事务,这种情况下如果后台的事物没有提交就abort后台事物,如果已经committed了,由于用户事物和这个后台事物更新的是不同的数据部分,这里使用额外的特别处理逻辑,
If it has committed, SQL Server uses special handling logic which causes the user transaction to update the row version created by the background transaction, instead of the row version the user transaction wanted to update originally. This is possible, since the background transaction does not change any user-visible data, so having a user transaction override its changes is acceptable.
这里的CSI初始的版本不支持secondary CSIs 的更新操作(Note that a secondary CSI need only include columns relevant to analytical queries, thereby saving space and speeding up compression.),在后面的版本中这种功能被添加。基本的思路和前面的方法类似,一个delete buffer记录被讹删除的数据,另外的一些delta stores记录最近被更新 or 添加的数据。在操作的时候从base data中获取的数据要先过滤掉被删除的数据,然后合并最近添加 and 更新的数据,才能得到最终的数据。涉及到次级索引更新的时候,添加操作会将设计到多个detal store,即对应到多个indexs。而更新操作被看作为一个删除操作和一个添加操作的结合。删除操作的时候,会先在base index中查找符合条件的数据,定位了row之后根据次级索引的key查找次级索引,在不符合添加的情况下不会实际取进行后面的操作。然后会查找delta stores,这个发现了对应数据的之后直接删除即可。如果在delta stores中没有发现,这些数据则在被压缩保存的数据中,为了避免操作这些压缩数据,这里会将这些删除的数据添加到delete buffer中,而不是实际上进行删除操作。在压缩保存的数据中,可能保存了一个key对应的多个版本的数据,这里删除的时候标记删除的记录也会带有一个版本好,delete buffer中一个<K, GD>记录表示key为K对应的记录,其版本好小于等于GD的版本被删除了。
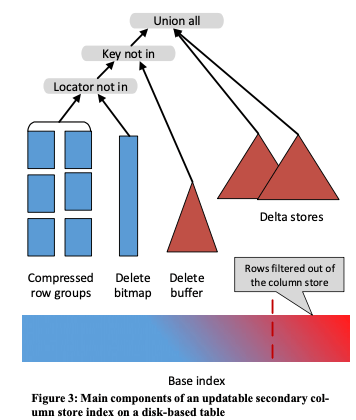
这里delete buffer之后有一个delete bitmap,用于标记那一行的数据被删除了,看起来这里的功能和delete buffer的功能重合了,这里设计delete buffer的原因是使用delete bitmap标记删除了时候需要对原来的数据进行解压缩来获取一些信息,这样会带来额外的开销。另外AP类型的workloads对scan的需求比较多,这离也进行了一些优化。比如使用Bloom filters和和利用一些min-max 的metadata信息等等,
We short-circuit the anti-semi-join, pre-qualifying data using a Bloom (bitmap) filter. The bitmap filter is constructed from the de- lete buffer contents during the hash build. If the bitmap filter test fails (i.e. the key is definitely not in the delete buffer) then the row is output into the scan...
Paper中还提到了这里支持在Primary Cloumn Stores上面添加btree Indexs的功能。CSIs适合处理扫描大量的数据,但是实际情况中还是会有一些的操作只会涉及到少量的数据,这样CSIs就会有一些不做。通过添加btree index,一些只涉及到少量数据的操作直接就查询btree index。这里btree idnex会记录这些数据的locator信息,即group ID 和 position of the row within the row group的信息。但是这里的一个问题是这些数据可能会变化的,比如更新操作导致在delta store中添加了相关的记录。这里的解决方式是使用一个mapping index,这个index会映射original locator 到其 current locator。这个index统一用一个btree来保存。
0x02 Columnstore and B+ tree – Are Hybrid Physical Designs Important?
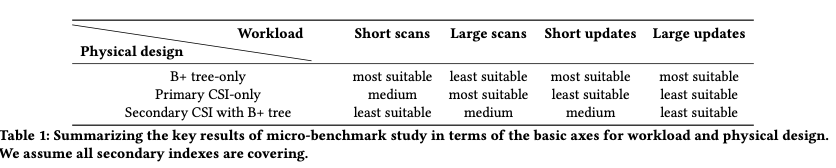
这篇Paper是SQL Server在上面的功能上面的拓展。Paper一一些workload为例,得出来这样的一些结论,即不同的index结构适应不同的workloads。基本的一个情况总结如下。而这里的功能就是在数据库的workload,来自动推荐一个适合目前workload的index的设计。这个功能可以支持推荐创建什么样的btree index or CSIs,或者是两个结合的indexs。这个功能的实现基于SQL Sever原来的 Database Engine Tuning Advisor功能,是在原来DTA功能上面的拓展。这个问题被描述为给定一个用户的workload,DTA找出一个合适的设计来最优化一些指标。
Paper中提到了DTA作出推荐之前,需要知道哪些信息:对于btree index,数据按行保存,保存这些数据需要多个pages的信息比较重要。对于column index,数据按列存储,per-column sizes的信息就比较重要,
- Candidate Selection。这部分主要是找出建立一个什么样的column indexs。Paper中这里有些困惑的地方,前面讲到了We support recommending both primary and secondary columnstore indexes on a table,但是后面有提到As of writing, SQL Server supports only one columnstore index per table。SQL Server在构建column index的时候有一些限制,有些数据类型不支持column index,一个table有不支持column index的数据类型列的时候,就不能在这个table上面构建primary columnstore index。但是可以构建不包含不支持columnstore index 列的secondary index。在选择建立什么样的column index的时候,考虑到SQL Server supports only one columnstore index per table这样的限制,这里有两种策略,1. 这个CSI只会包含在select操作中涉及到的列,2. 包含table的所有的列。目前的算法是支持策略一的,选择二是因为二的设计在查询操作,哪些不会涉及到列可以不去访问,对查询不会有太大的影响,但是在可能涉及到其它列的查询的时候,会有不少的优势。缺点是带来一些额外的维护这些列的开销。
- 在计算出创建什么样的column index 和btree index之后,会创建hypothetical indexes,使用SQL Server的what-if API来进行估计效果,即真的这么做了能得到的效果怎么样的一个估计。Paper描述了一些关于Columnstore Size Estimation的内容,优化器需要这样的一些信息来作出决策。在估计column index size主要处理两个问题,一个是不能扫描大量的数据,这里使用的是block-level采样的方式,但是简单的block-level的采样在一些情况下会带来比较大的误差。这里使用的误差修正方式来自之前的另外一篇论文,还有的一些问题就是如何在压缩的数据上面比较准确的估计,另外压缩的效果和实际的数据相关性很大,容易引进误差[2]。
emmmmm,这里的思路是如何在合适的时候选择合适的索引,不少内容和SQL Sever具体的一些特性、功能相关,看看思路吧。
0x03 评估
这里的具体内容可以参看[1, 2].
参考
- Real-Time Analytical Processing with SQL Server, VLDB ‘15.
- Columnstore and B+ tree – Are Hybrid Physical Designs Important?, SIGMOD ‘18.
