LeanStore: In-Memory Data Management Beyond Main Memory
0x00 基本设计
这篇Paper是一个关于Storage Engine的一篇Paper。这篇Paper之前的一些研究是关于如何讲数据都放到内存中来处理,之后的研究中变为了来将一部分冷的数据放到磁盘上面来。又回到了类似之前普通数据库系统的思路,当然还是存在一些差别。这篇Paper重要将的是LeanStore的Buffer Pool方面的设计,存储上面LeanStore还是一个基于Btree的设计。其核心的一个设计是Pointer swizzling。Pointer swizzling就是一种引用数据Pape的一种技术,在一般的数据库系统中,一个page可能在Buffer Pool中,也可能还在磁盘上面。在这里一个swizzled的pointer指向一个已经load到内存中的page,而一个swizzled的指针引用的是磁盘上面的一个Paper。一般的Buffer Pool使用的时候,都要经过PageID到Pointer的转化,才能引用到内存中的Page。这里的实现一个就是使用一个hash table。基于hash table的buffer pool一个好处就是在一个地方统一管理内存中的page,page替换算法实现比较简单。
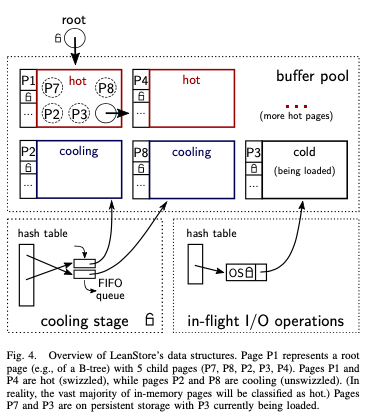
而这里基于pointer swizzling方法的情况下,引用一个page的指针是可能有很多个,而是是分散的。这里的解决办法是一个page只会有一个引用的结构。另外设计上面的一些考量是不会unswizzle掉一个有内存中page的page,这样处理的时候可以避免一些麻烦。另外一个page上面的指针信息可能被写入到磁盘,但是重新启动之后,这些指针的值对于新的进程来说是没有意义的,这样需要在evict一个inner page的时候,处理好其上面保存的子page的信息。这里和前面的不会unswizzle掉一个有内存中page的page设计相适应。在此基础之上的另外一些设计:
- Cooling Stage,Cooling Stage用于处理page替换的问题。基于hash table的buffer pool由于集中管理page,page替换实现比较直接。一般的LRU的思路是将最频繁使用的page放到一个list的前面,实际上是监控最频繁使用的page。而这里选择的方法是监控不频繁使用的page。LeanStore会speculatively的去unswizzle一个papge。speculatively地选择的page会不立即被evict,而是放到一个cooling stage的结构中。这里的思路类似于一些缓存替换算法中在给一次机会的思路,如果判断事物,可以被简单地重新拿回来。
- 这里Cooling Stage中会保存大概10%左右的page,大部分的page还是会在hot stage中。这里的主要结构是一个fifo队列,一个pape在到达这个queue的末位的时候就会被真的evict。访问page的时候,想要知道这个page在不在Cooling Stage中。为此这里又加了一个hash table来记录Cooling Stage的一些信息。如果访问的一些page在这里,那么会被从Cooling Stage中撤销。这个移动page的操作可以同步or异步地完成,LeanStore选择的是同步的方式。LeanStore还使用一个另外的一个hash table来管理loading中的page。对于每个load中的page使用一个mutex,到达serialize这里操作的效果。估计是类似于single in-flight的设计。
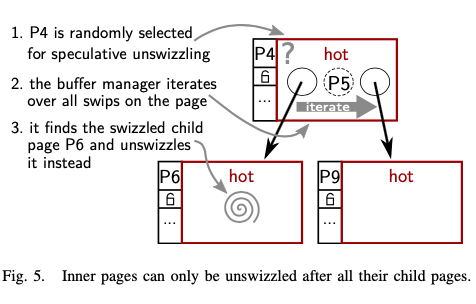
- 在这些设计的基础之上,一些操作的示意如下。Speculatively地unswizzling一个page就是使用随机选择的方式。由于要满足不会unswizzle掉一个有内存中page的page,就需要迭代查找器子page的情况,如果发现其子page中存在swizzled的,就使用这个子page替代。
另外这里的Optimistic Latches设计和Epoch-Based Reclamation都是来自已有的一些设计,没有太多特别的地方,内存的分配上面也考虑到NUMA的一些特点。另外LeanStore提到了实现上面的一些优化,比如将buffer frame和page的内容直接放到一起(buffer frame是buffer pool管理单位的一个抽象,对应到一个具体到page),而不是和一般的buffer pool一样一个buffer frame中使用一个指针来引用这个page,这样来提高数据的局部性;使用thread-local cache for deleted pages的思路来提高请求一个新page的性能;使用 I/O prefetching来提高scan性能,以及使用background writer线程来避免worker做写入数据的操作等。
0x01 评估
这里的具体内容可以参看[1],Paper中的数据看起来很不错。
Rethinking Logging, Checkpoints, and Recovery for High-Performance Storage Engines
0x10 基本设计
这篇Paper是发表在SIGMOD ’20上面,不过可以提前下载到。主要描述的是LeanStore在WAL上面的改进,涉及到LSN、数据Fush和Checkpoints等多个方面。在ARIES风格的WAL中,日志项之间的顺序是由一个LSN来决定的,所有的日志数据在逻辑上面都写入一个Log中。这样在面前的告诉硬件下面会带来不小的开销。现在一些的研究的优化思路是将一个Log转变为多个Log,来降低些一个Log带来的冲突。这样的设计要解决的一个问题是不同的Log中有顺序关系的Log应该如何确定。这里提到的一种方法是global sequence numbers (GSN)。
- global sequence number (GSN),GSN类似于Lampor提出的logical clock的思路,每个page会维护一个GSN的信息,写page和log的时候也会将这个数据一起写入到磁盘。一个事务执行的时候,如果要更新一个page,需要讲这个page和这个事物的GSN设置为max(tx GSN, page GSN) + 1。不更新的话设置为max(tx GSN, page GSN)。写入一个日志项的时候,log设置为自己的GSN为max(tx GSN, page GSN, log GSN),这个GSN会在日志项写入的时候也记录在其中。除了GSN之外,每个日志项还会记录自己的LSN,和一般的LSN类似。通过GSN来维护了不同log的相关日志项之间的顺序关系。在此之外,这篇Paper中还提到的[3]中的一个优化思路是passive group commit:即一个事物要提交的时候,它会首先flush日志这部分的log到磁盘,然后会在一个 group commit queue等待,等到到这个事物GSN前面的都持久化之后,这个事物也就可以完成最后的commit。
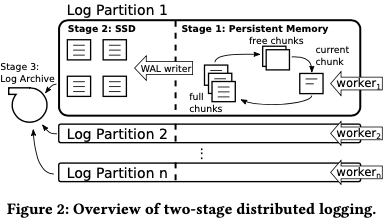
Paper中这里也采用这样的思路,不过作出了一些改进。这个GSN也带来了high instruction overhead和一些事物的高延迟。这里使用的Logging方式称之为Two-Stage Distributed Logging,总体上还是GSN的思路。总体的设计如下,每个woker线程会有自己的一个log,一个事务是有一个worker线程来操作完成的,这样的话一个事务的日志都会被写到一个log中。(限制一个事务由一个线程来执行,在一些workload下面会有一些缺点的)。日志的写入分为三个步骤:1. 第一个小的log chunk先组织为中的一个circular list。写满了数据的chunks,会由一个wirter现场来讲这些数据flush到第二个阶段;2. 待到数据写入到磁盘之后,对应的chunk回重新添加到free chunks的结构中;3. 一个Log Archive回组织起来用于后面可能的media recovery。
在此的基础之上提到的一个优化称之为Low-Latency Commit Through RFA。GSN的设计下面,一个事务要完成提交,想要等到其它的log之前的改动数据也持久化。[3]使用的是passive group commit的思路,解决了一些问题,但是可能带来的延迟问题没有解决。这里使用的思路是基于一个观察:在实际的应用中,事务之间多数没有逻辑上面的冲突,也没有更新了相同的page,这样的话等到比起小的GSM都commit/abort是不必要的。RFA在GSN的基础上面做了下图的修改:
-
01.对于每个page,记录下L-last,记录下最后更新这个page的log。这些数据不需要持久化;02. 一个事务开始的时候,获取GSN-flushed的信息,即事务启动的所有的log以及持久化的GSN的最大值;03. 每个事务会维护一个needsRemoteFlush的flag,初始化为false。
-
一个事务访问一个page的是,无论是读or写,都需要比较这个page的GSN和自己的GSN-flushed。如果page GSN < GSN-flushed,表面相关的log已经被flush到磁盘了,操作可以继续。不满足这个条件的话,检查L-last 是不是和面前的事务为同一个,相同的话操作可以继续。这两个检查失败的话,想要设置needsRemoteFlush为true,
Only if both checks fail, then the needsRemoteFlush flag is set to true, which causes all logs to be flushed when the transaction commits. In a nutshell, remote flushes are avoided whenever the log records of a transaction depend only on (1) guaranteed flushed changes or on (2) changes from its own log.这样处理来避免一些实际上不需要的等待,从而来降低延迟。
0x11 Checkpointing and Others
这里的提交的Checkpointing主要是解决这样的一个问题:目前常见的触发Checkpointing的方式是看日志到达一定的大小or经过来一段定义的时间。这样的一个缺点是可能造成突然的磁盘写入尖峰,目前MongoDB使用wiredtiger好像就存在这个问题。Paper中举例了PG中使用的方式:PG将刷脏的操作分给两个进程,一个称之为checkpointer,在日志到达一定的大小or经过了一个定义的时间时候,checkpointer会将buffer pool中的所有dirty pages都flush到磁盘,来完成checkpointing的操作。这样checkpointer刷脏的时候会有一个写入流量的burst。为了解决/优化这个问题,PG引入来一个background writer进程,这个进程会周期行地从buffer pool中取出一定数量的dirty pages来写入磁盘,这样降低checkpointing操作的时候需要写入的数据的量。Paper中认为这种方式还存在一些问题是比较难使用workload的变化,以及这些参数需要人来设置一个合理的值。
-
这里解决这个问题的办法还是将大拆分的思路。通过将buffer pool分为逻辑上面S个shards。每次checpointer的操作称之为checkpoint increment。每次操作通过RR的方式选择一个shard,然后将这个shard里面的dirty pages写入磁盘。总体的思路如下的伪代码所示。checpointer会维护一个table,记录下每个shard以及持久化的最大的GSN的信息。每次checkpoint increment操作的时候,记录下吗所有log的最小的GSN,每个flsuh完一个shard的时候,会更新这个table里面对应shard的GSN信息为之前获取到的最小的GSN。table中最小的GSN最为一个完成持久化的一个信息。
// Maintain the persisted GSN for each shard GSN maxChkptedInShard[num_shards]; // Initially zero unsigned current_incr = 0; // Triggered by writing a certain amount of WAL void checkpoint_increment() { min_current_gsn = logs.getMinCurrentGsn(); shard = current_incr % num_shards; pages = bufferPool.getPagesInShard(shard); foreach (page in pages) { if (page.isDirty()) write(page); } maxChkptedInShard[shard] = min_current_gsn; // Get the minimum GSN up to which all // shards are checkpointed chkpted_gsn = min_val(maxChkptedInShard); min_tx_gsn = txManager.getMinActiveTxGsn(); logs.prune(min(chkpted_gsn, min_tx_gsn)); ++current_incr; }Paper中提到这里没有使用time-based,有说不会造成很大的写入放大。这里看起来还是PG使用background writer方式的一种优化。
-
另外一个需要写入dirty page的原因是需要load新的page的时候,有没有合适的free page可用。这个时候要将一些pages从buffer pool的淘汰,如果是dirty page需要写入磁盘。这里的优化思路是将pages分为三个部分,如下图所示。Hot部分的直接用指针引用,对用到前面paper的swizzled pointer。Cool部分的则需要使用page ID来查找到引用这个page的pointer。Free部分则为空闲的page。Page在不同的部分转化如下。如果pages在不同的部分流动达到一个平衡,则不需要有这样的刷脏操作了。Paper实现这样的平衡使用的思路是使用一个page provider线程,这个线程一般的操作,
(1) It unswizzles pages and puts them into the cool area, which is organized as a FIFO queue. From there they get re-swizzled if worker threads access them again in a timely manner. Access to the queue is sped up with a hash table lookup. (2) Pages from the older end of the queue are evicted and put into the free list. (3) Before a dirty page can be evicted, it is persisted to disk first.在图中使用的转化方式的基础上面,这个线程的工作就是取保证这三个部分中page数量保持在合适的比例,实现动态适应wrokload的情况。

ARIES风格中,其中的一个策略是steal,也没有提交数据的page也可以被刷到磁盘上面。这样的一个有点是可以处理比内存要大的事务。而最近研究的内存数据库系统是no-steal测试的,这样的优化是可以消除一些undo的需要。 这里使用的是steal的策略,主要的考虑是no-steal的模式需要追踪uncommitted changes的信息会带来不小的开销。这里Recovery基本上面沿用了ARIES的思路,分为log analysis, redo, 和 undo三个步骤。这里在这样的基础上面的优化是并行化来处理。redo阶段会根据page ID来分区,通过合并前面一步的logs,在根据(pageId,GSN)来排序。后面的操作就是一个一个page进行redo处理,可以是并行的。
0x12 评估
这里的具体内容可以参看[2].
参考
- LeanStore: In-Memory Data Management Beyond Main Memory, ICDE ‘18.
- Rethinking Logging, Checkpoints, and Recovery for High-Performance Storage Engines, SIGMOD ‘20.
- Scalable Logging through Emerging Non-Volatile Memory, VLDB ‘14.
