Efficient Transaction Processing in SAP HANA Database – The End of a Column Store Myth
0x00 基本思路
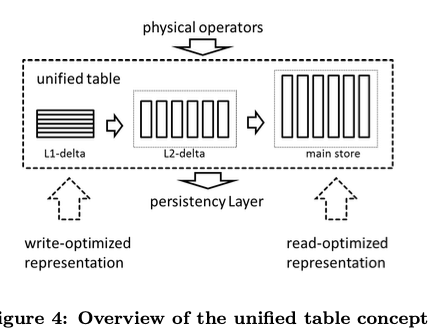
SAP HANA数据库是一个列式存储的数据库。这篇Paper的核心是将了SAP HAMA 2层的delta的数据存储的设计,这里虽然还将到HANA数据的一些功能特点,但是好像就是一些功能介绍。HANA主要还是一个为分析类型的workload设计的数据,使用列式存储,这样对于高效执行一些事务处理就会比较麻烦。一般的设计是使用存储delta数据和存储主要数据的部分组成,比如前面的SQL Server的为分析型workload的优化。HANA这里的特点是不仅仅是单个的保存delta数据的设计,而是使用了2层的设计。基本的思路如下图,
-
L1-delta,L1-delta数据保存方式是一个写入优化的设计。一般的数据写入的时候都是先写入到L1-delta,然后通过merge操作到L2-delta。这里数据是没有压缩的,数据上面的操作也应该是直接直接操作的方式。单个节点上面L1-delta一般保存10000到100000行的数据,从下面的图来看,这里的存储方式是以行存的方式存储的;
-
L2-delta,L1-delta类似于长的delta+main-store的设计。而L2-delta是HANA这里有特点的一个部分,这里的存储方式是以列存的方式存储的。除列列存之外,这里还使用了dictionary encoding来实现数据压缩,但是这里的dictionary数据是没有压缩的。未来更高效地支持一些操作比如点查询,这里需要一个索引。单个节点这里L2 delta Store的大小在10 Million级别;
-
Main Store,这里复制保存大部分的数据,这里保存的数据会以更高压缩率的方式保存:
.. all values within a column are represented via the position in a sorted dictionary and stored in a bit-packed manner to have a tight packing of the individual values. While the dictionary is always compressed using a variety of prefix-coding schemes, a combination of different compression techniques ...
0x01 基本操作
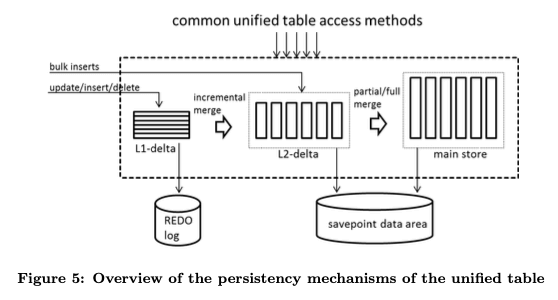
在这种模式下面,HANA支持完整的事务的ACID特性,一般支持ACID的特性都是使用WAL来实现的,这里也不例外。在数据统计到数据库中的时候,对于量不大的添加操作,都是先添加到L1-delta中,而对于大批量的bulk insert操作,会直接添加到L2-delta中。添加操作会导致写log,但是L1-delta到L2-delta,以及L2-detla到main store的数据转移操作的时候,是不用写log操作的。这种工作模式下面,很重要的一个操作就是Merge操作,这里和LSM-tree的操作思路有很多相似的地方。但是这里的会涉及到不少的和HANA实现相关的一些优化,和HANA使用的压缩方式有比较大的关系,特别是dictionary encoding压缩的方式,具体的细节可以参看[1].
Towards Scalable Real-time Analytics: An Architecture for Scale-out of OLxP Workloads
0x10 基本思路
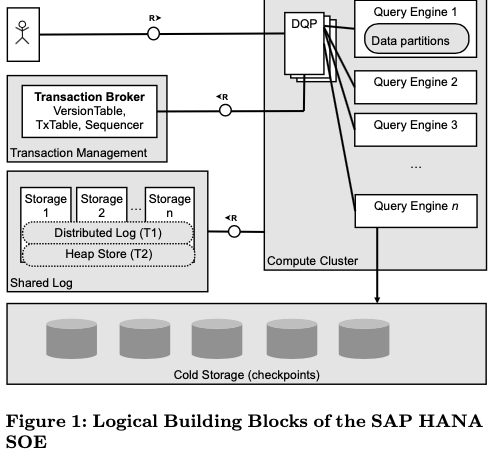
这篇Paper也是关于HANA的一篇Paper,主要的内容是HANA的Scale-out Extension,主要是如何HANA数据库的分布式拓展。同时在现在的对OLAP支持的基础之上,实现对OLTP的良好支持。基本的架构如下,这种架构和其它的一些产品有很多类似的地方。从下面的结构来看,这里的Scale-out Extension主要还是主要支持在单个的IDC之内,和现在的很多分布式数据库有些不同的地方。为了实现Scale-out,一般要将存储、计算等的操作划分、分发到多个的节点上面支持。由于HANA想要支持事务操作,有些操作比较难实现完全的逻辑上面的拆分,比如这里的transaction management为一个逻辑上中心化的设计。数据库一般依赖于日志来实现数据库的ACID特性,但是数据和计算发布到多个节点上面之后,如果日志每个节点写各自的日志,就会无法实现目前的WAL逻辑。这里的具体解决方式是使用了一个Shared Log来实现一个分布式的WAL。
0x11 基本设计
HANA的基本架构如上图。用户的操作都是发送到查询引擎操作。HANA查询操作中,使用了一些查询编译的方式,即将SQL编译到C。查询优化器运行在DQP节点上面。一般的思路就是这些优化器生成执行计划之后,会讲这些计划发动到后面的查询引擎,每个节点根据自己负责处理部分的数据来实现操作(HSQE node)。HANA的一个设计是要同时支持LTAP和OLTP的操作,但是这两种类型workload有这很大的差别,为了解决差异,HANA的思路是将HSQE节点分为两个部分,一个部分执行OLTP操作,一部分执行OLAP操作。另外,
-
Transaction Broker操作一个中心化的事务管理器。在ACID的特性上面,HANA支持SI的事物隔离级别。SI的隔离一般都是基于MVCC的并发控制来实现。Transaction Broker这里在这里的角色有作为一个发号器的角色。事务的执行想要首先向Transaction Broker中的Sequencer来申请一个逻辑时间戳。另外事物的执行状态也会保存到Transaction Broker中。Transaction Broker中还有一个Version Table的角色,重要用于处理写入事务写入冲突的问题。事务执行的时候会讲write set的信息保存到这个version table中,用于探测写入冲突。
-
Transaction Broker的这里的设计明显是一个单点问题。Paper中的观点认为,Transaction Broker处理的这些工作都是比较轻量级的工作,单点Transaction Broker能够处理这些工作。在时间戳的分配上面,Transaction Broker也根据不同的workload进行一些区别化的处理,borker会维护一个last committed时间戳,每次事务提交的时候就会更新。这个时间在OLTP事务执行读取操作的时候会作为一个start time。另外的一个OLAP read timestamp则是使用一种基于services-level agreement的周期性(epoch)更新的方式,这样设计的原因是方便批量地调度OLAP查询操作。
-
Transaction Broker这里的不会保存持久化的数据,在这个broker故障之后,其它的节点可以被选举为新的Transaction Broker,需要恢复的数据从日志中恢复,这样一定程度上面简化了系统的设计:
... An epoch-based versioning scheme is used to ensure a “split-brain” scenario is not possible. All currently running read/write transactions are aborted (the new broker starts with an empty version and transaction table), and the sequencer can be recovered by querying the log to find the last written offset.
在写日志方面,HANA使用了一个单独的distributed shared log组件。这个shared log的设计类似于CORFU shared log的设计,另外针对这里的环境做了一些优化。这个shared log要求实现这样的一些特点:
1. Each log entry may be written to an arbitrary number of logical streams within the log.
2. The log provides a total order over all writes to all streams, guaranteeing linearizeable operations.
3. The log interface includes a scan operation which performs bulk reads of log entries based on a specified predicate on the metadata.
4. A secondary unordered heap store is provided for large offline / asynchronous writes.
HANA这里执行一个事物的时候,log中存储的关于一个事物的log作为一个单独的log entry,这个log entry应该是一个逻辑上的单个。为了更好地利用机器、网络的资源,log写入到streams的层面,每个log entry会带有它保存在的streams的IDs。在totally order writes的特性上面,这里使用了CORFU shared log的思路,具体怎么实现没有细讲,细节可以参看CORFU shared log的论文。另外为了支持大事物写入的大的log entry,这里引入了一个heap store的优化设计。在提交large transaction的时候,large log entry会在without synchronization的情况下写入这个heap store,后面提交的时候请求到相应的mutex,然后在写入一个小的commit entry到log中作为整个的提交。在这些组件的基础之上,HANA这里执行一个事物的基本流程如下:
- 首先从Transaction Broker获取一个read timestamp,同时在Transaction Broker中的transaction table中记录这个事务为running状态;这个事务将查询、更新等的操作发动到query cluster;
- 对于接受到这些操作的计算节点,如果发现对应data slice(s)对应版本的数据不在本节点上面,这个节点回去log中查询对应data slices的处理中的更新数据的信息,如果本地已经存在了相关的数据,直接查询本地的cache;
- Query Cluster处理查询和更新的操作:执行查询操作返回数据;在read only的模式下面执行更新操作,已经存在的rows不会被更新,这些更新可能被缓存起来;在two-tier的存储模式下面,如果更新操作是有比较大的写入,这里会讲这些数据异步写入第二层的存储,之后讲存储的信息通知transaction executor;这些操作完成之后,compute cluster返回写入数据的row IDs。
- 事务将这些ID推送到Transaction Broker,检查写入的冲突情况。如果存在冲突否则需要abort;如果没有冲突,事务请求一个commit timestamp,并将这个事物的状态改为pre commit状态。这个的commit timestamp即为这个日志的LSN;
- 如果事物两层存储的模式(应该和heap store为大事务的优化相关),这里还需要等到数据写入完成,如果是使用单层的存储模式,或者是写入的数据量比较小,会直接在commit操作的时候写入commit record数据的时候一并写入;
- 事物通过写入带有前面获取到LSN的commit record来完成事物的提交。如果log写入成功,则事物再次请求Transaction Broker,更新事物的状态为已经提交;如果log写入识别,也需要再次请求Transaction Broker来更新事物状态为abort。
- 最后向client返回执行情况的信息、数据等。
另外,对于read only的事务,执行的模式会简单一些。开始的时候也是向Transaction Broker请求一个timestamp,然后将查询发送到compute nodes,这些节点根据timestamp查询相应版本的数据,如果对应版本的数据不存在,表示这些数据应该明确支持写入到了shared log中,没有更新到这里,需要查询shared log获取相关的数据。。这里事务之间的并发控制类似于一种乐观的并发控制。数据写入的时候,不直接更新数据避免了一些事务提交的麻烦 ,而是将这个逻辑放到了shared log中实现。这样会导致的数据就是query clsuter中的节点不一定有最新的数据,需要这里的从shared log拉取的操作来处理这种情况。Paper中谈到了这种模式在支持不同的worloads下面的一些问题和对应的优化方式:OLTP一般期望读取到最新的数据,而OLAP的操作,数据不是最新的不是很大的问题。如果使用情况的思路,在混合的worload下面,从log中拉取最新的操作会比较频繁,影响到系统的性能和稳定,这里优化方式和前面的OLAP获取read timestamp方式对应,不要求读取最新的数据可以很好缓解这种情况。
0x12 评估
这里的的具体信息可以参看[2].
参考
- Efficient Transaction Processing in SAP HANA Database – The End of a Column Store Myth, SIGMOD ‘12.
- Towards Scalable Real-time Analytics: An Architecture for Scale-out of OLxP Workloads, VLDB ‘15.
